
python-图书评论数据分析与可视化
【题目描述】豆瓣图书评论数据爬取。以《平凡的世界》、《都挺好》等为分析对象,编写程序爬取豆瓣读书上针对该图书的短评信息,要求:
(1)对前3页短评信息进行跨页连续爬取;
(2)爬取的数据包含用户名、短评内容、评论时间、评分和点赞数(有用数);
(3)能够根据选择的排序方式(热门或最新)进行爬取,并分别针对热门和最新排序,输出前10位短评信息(包括用户名、短评内容、评论时间、评分和点赞数)。
(4)根据点赞数的多少,按照从多到少的顺序将排名前10位的短评信息输出;
(5附加)结合中文分词和词云生成,对前3页的短评内容进行文本分析:按照词语出现的次数从高到低排序,输出前10位排序结果;并生成一个属于自己的词云图形。
【练习要求】请给出源代码程序和运行测试结果,源代码程序要求添加必要的注释。
源代码:

import re from collections import Counter import requests from lxml import etree import pandas as pd import jieba import matplotlib.pyplot as plt from wordcloud import WordCloud headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.39" } comments = [] words = [] def regex_change(line): # 前缀的正则 username_regex = re.compile(r"^\d+::") # URL,为了防止对中文的过滤,所以使用[a-zA-Z0-9]而不是\w url_regex = re.compile(r""" (https?://)? ([a-zA-Z0-9]+) (\.[a-zA-Z0-9]+) (\.[a-zA-Z0-9]+)* (/[a-zA-Z0-9]+)* """, re.VERBOSE | re.IGNORECASE) # 剔除日期 data_regex = re.compile(u""" #utf-8编码 年 | 月 | 日 | (周一) | (周二) | (周三) | (周四) | (周五) | (周六) """, re.VERBOSE) # 剔除所有数字 decimal_regex = re.compile(r"[^a-zA-Z]\d+") # 剔除空格 space_regex = re.compile(r"\s+") regEx = "[\n”“|,,;;''/?! 。的了是]" # 去除字符串中的换行符、中文冒号、|,需要去除什么字符就在里面写什么字符 line = re.sub(regEx, "", line) line = username_regex.sub(r"", line) line = url_regex.sub(r"", line) line = data_regex.sub(r"", line) line = decimal_regex.sub(r"", line) line = space_regex.sub(r"", line) return line def getComments(url): score = 0 resp = requests.get(url, headers=headers).text html = etree.HTML(resp) comment_list = html.xpath(".//div[@class='comment']") for comment in comment_list: status = "" name = comment.xpath(".//span[@class='comment-info']/a/text()")[0] # 用户名 content = comment.xpath(".//p[@class='comment-content']/span[@class='short']/text()")[0] # 短评内容 content = str(content).strip() word = jieba.cut(content, cut_all=False, HMM=False) time = comment.xpath(".//span[@class='comment-info']/a/text()")[1] # 评论时间 mark = comment.xpath(".//span[@class='comment-info']/span/@title") # 评分 if len(mark) == 0: score = 0 else: for i in mark: status = str(i) if status == "力荐": score = 5 elif status == "推荐": score = 4 elif status == "还行": score = 3 elif status == "较差": score = 2 elif status == "很差": score = 1 good = comment.xpath(".//span[@class='comment-vote']/span[@class='vote-count']/text()")[0] # 点赞数(有用数) comments.append([str(name), content, str(time), score, int(good)]) for i in word: if len(regex_change(i)) >= 2: words.append(regex_change(i)) def getWordCloud(words): # 生成词云 all_words = [] all_words += [word for word in words] dict_words = dict(Counter(all_words)) bow_words = sorted(dict_words.items(), key=lambda d: d[1], reverse=True) print("热词前10位:") for i in range(10): print(bow_words[i]) text = ' '.join(words) w = WordCloud(background_color='white', width=1000, height=700, font_path='simhei.ttf', margin=10).generate(text) plt.show() plt.imshow(w) w.to_file('wordcloud.png') print("请选择以下选项:") print(" 1.热门评论") print(" 2.最新评论") info = int(input()) print("前10位短评信息:") title = ['用户名', '短评内容', '评论时间', '评分', '点赞数'] if info == 1: comments = [] words = [] for i in range(0, 60, 20): url = "https://book.douban.com/subject/10517238/comments/?start={}&limit=20&status=P&sort=new_score".format( i) # 前3页短评信息(热门) getComments(url) df = pd.DataFrame(comments, columns=title) print(df.head(10)) print("点赞数前10位的短评信息:") df = df.sort_values(by='点赞数', ascending=False) print(df.head(10)) getWordCloud(words) elif info == 2: comments = [] words=[] for i in range(0, 60, 20): url = "https://book.douban.com/subject/10517238/comments/?start={}&limit=20&status=P&sort=time".format( i) # 前3页短评信息(最新) getComments(url) df = pd.DataFrame(comments, columns=title) print(df.head(10)) print("点赞数前10位的短评信息:") df = df.sort_values(by='点赞数', ascending=False) print(df.head(10)) getWordCloud(words)
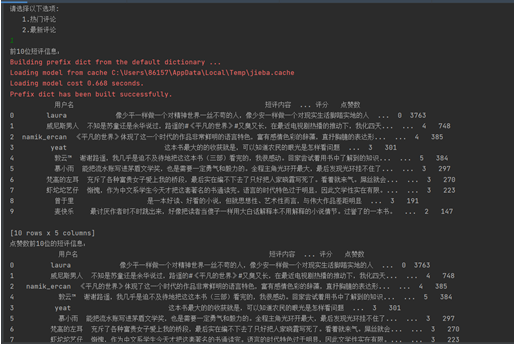
运行结果:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律