目标检测中的Anchor详解
目标检测中的Anchor详解
👆原文链接
常用的Anchor Box定义
- Faster R-CNN 定义三组纵横比
ratio = [0.5,1,2]和三种尺度scale = [8,16,32],可以组合处9种不同的形状和大小的边框。 - YOLO V2 V3 则不是使用预设的纵横比和尺度的组合,而是使用
k-means聚类的方法,从训练集中学习得到不同的Anchor - SSD 固定设置了5种不同的纵横比
ratio=[1,2,3,1/2,1/3],由于使用了多尺度的特征,对于每种尺度只有一个固定的scale
Anchor 的意义
Anchor Box的生成是以CNN网络最后生成的Feature Map上的点为中心的(映射回原图的坐标),以Faster R-CNN为例,使用VGG网络对对输入的图像下采样了16倍,也就是Feature Map上的一个点对应于输入图像上的一个\(16 \times 16\)的正方形区域(感受野)。根据预定义的Anchor,Feature Map上的一点为中心 就可以在原图上生成9种不同形状不同大小的边框,如下图:
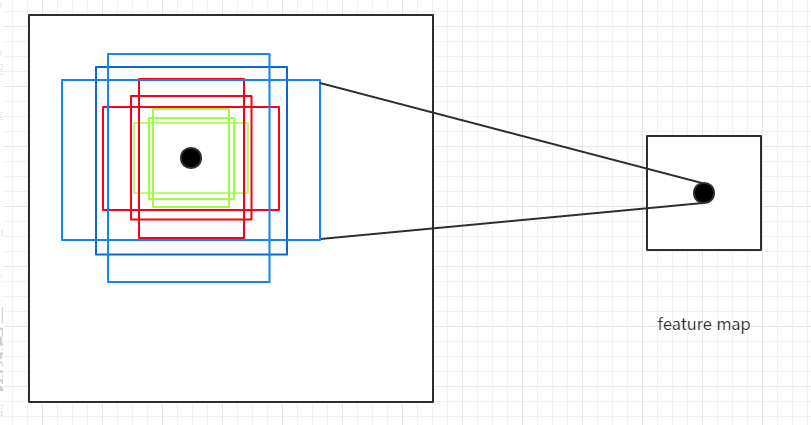
从上图也可以看出为什么需要Anchor。根据CNN的感受野,一个Feature Map上的点对应于原图的\(16 \times 16\)的正方形区域,仅仅利用该区域的边框进行目标定位,其精度无疑会很差,甚至根本“框”不到目标。 而加入了Anchor后,一个Feature Map上的点可以生成9中不同形状不同大小的框,这样“框”住目标的概率就会很大,就大大的提高了检查的召回率;再通过后续的网络对这些边框进行调整,其精度也能大大的提高。
YOLO 的Anchor Box
YOLO v2,v3的Anchor Box 的大小和形状是通过对训练数据的聚类得到的。 作者发现如果采用标准的k-means(即用欧式距离来衡量差异),在box的尺寸比较大的时候其误差也更大,而我们希望的是误差和box的尺寸没有太大关系。这里的意思是不能直接使用\(x,y,w,h\)这样的四维数据来聚类,因为框的大小不一样,这样大的定位框的误差可能更大,小的定位框误差会小,这样不均衡,很难判断聚类效果的好坏。
所以通过IOU定义了如下的距离函数,使得误差和box的大小无关:
\]
Anchor 计算
这里先计算每个Anchor的长和宽,至于其中心位置是Feature Map的每个点在原图上的映射,是固定,可以先不考虑。
从上面可以知道,任意的形状和大小的Anchor的宽和高都可以从最基础的宽和高\(16 \times 16\)变换而来。首先看三种ratio的变换。
设矩形框的面积\(s = 16 \times 16\),矩形框的宽\(w\),高为\(h\),则有:
\begin{array}{c}
w \times h = s\\ \frac{w}{h} = ratio
\end{array}
\right. =>
\left\{ \begin{array}{c}
w = ratio \cdot h \\ ratio \times h^2 = s
\end{array} \right.
\]
所以最终得到
\begin{array}{c}
h = \sqrt{s / ratio} \\
w = ratio \cdot h = \sqrt{s \cdot ratio}
\end{array}
\right.
\]
不同尺度的是在基础的尺度上的缩放,设尺度为\(scale\),则缩放后的面积为\(scale \cdot s\)。当然也可以从宽高的缩放比例来看,基础的面积为\(16 \times 16\),则尺度为$128 \times 128 \(则是相当于长宽高各放大了3倍。只是要注意数值的变换,从面积的角度看缩放因子为\)scale_{area} = (128 \times 128) / (16 \times 16)$,从宽高看的话,缩放因子为宽高的比值。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!