
《面向对象程序设计》第三单元 JML 总结
一、实现规格所采取的设计策略
首先,类方法规格分为正常行为规格与异常行为规格,在JML书写时习惯将异常部分置后。但实际在进入函数时就进行异常判断才是保险的做法,因为异常抛出的条件往往较为简单,而其互补条件表达式复杂,如此可以避免因为手滑在正常代码段执行时抛出无法被catch的异常导致程序整段垮掉。
在方法规格中,会规定前置条件、后置条件和副作用约定,这是实现函数正常功能的核心部分。在实现方法规格的过程中,通过分析前置条件理解接口对应函数传入参数的范围与含义,通过分析后置条件理解方法所要实现的功能,而副作用约定限制了修改的属性范围。
在具体的方法规格中,最为关键的后置条件又分为核心功能表述与无关量不变的表述。笔者在实现时往往先按照核心功能表述完成代码,再检查代码所涉及的变化是否符合上述限制,之后进行复杂度优化和数据结构调整,最终再次检查是否符合规格要求。
一些复杂方法的具体实现策略在下文中有详细说明。
类型规格作业涉及较少,多规定一些基本属性要求,在此不作赘述。
二、测试的方法和策略
本单元作业可使用对拍的方法进行黑盒测试,即按照一定的规则生成测试数据,通过命令行调用不同同志的jar包,并进行输出比对。由于时间的关系,上述过程仅存在于笔者的想象中。
除了对拍测试,还可以使用JUnit进行单元测试。JUnit在对简单的原子方法进行测试时比较简单,但对涉及到多个子功能和数据结构的组合方法测试时略显无力。
另外可以直接进行手动黑盒测试,一般用于基本功能和特殊边界数据的测试。
本单元最大的启发和教训的内容就是测试至关重要。即使按照JML完成了功能设计并通过了基本测试,代码仍有可能存在致命的问题,不论是在正确性方面还是性能方面。
三、容器的选择
JML规范通常使用数组来表述数据的集合。但在代码实际实现的过程中,单纯的数组往往存在诸多的不足,增删查改冗长耗时。
在之前的作业中多使用类数组的ArrayList,其底层通过数组实现。但与数组不同,ArrayList具有可变长的特点,且封装了许多基本的方法,使用起来较为简单。通过add(index, object)将元素插入指定下标位置位置或通过remove(index)删除制定下标的元素时,一般情况需要复制底层数组,时间复杂度最差为o(n);通过set(index, object)设定指定下标的元素时,时间复杂度为o(1);通过get(index)按下标读取数据时,时间复杂度也为o(1)。可以看出,ArrayList中插入、删除和直接查找元素的时间复杂度均较高,而按下标修改、读取元素时时间复杂度则较低,因为前者常常触发底层数组拷贝,造成时间和空间的浪费。
本次作业中涉及大量图相关的数据结构,如果仍单纯地使用list来组织数据,则性能和操作简洁性无法满足需求。HashMap在本单元作业中应用非常广泛。HashMap是一种类字典的数据结构,能近似达到o(1)级别的查询复杂度,对外接口通过键值对存储数据。笔者使用HashMap实现了Person类中邻接节点<Person, Integer>的存储,可以直接通过Person映射到两人关系的Value;类似的,Network中的:
/* id 到 Person */
private final HashMap<Integer, Person> id2person;
/* id 到 Group */
private final HashMap<Integer, Group> id2group;
/* id message Group */
private final HashMap<Integer, Message> id2message;
/* 连通块的并查集中,每个连通块 id 到 Person */
private final ArrayList<HashMap<Integer, Person>> circles;
/* emojiId 到 该表情的热度heat */
private final HashMap<Integer, Integer> emojiId2heat;
/* 为方便最短路径算法设计的邻接表: <Person1, <与Person1邻接的Person2, 两者关系的Value>> */
private final HashMap<Person, HashMap<Person, Integer>> adjacencyList;
往年博客中有提到设计<Person, Id>和<Id, Person>双重HashMap映射,但在实际操作中发现,Network中由Person映射到Id的需求非常少,组织这样的数据结构所额外耗费的时间反而造成了负优化。
还有Group中常用到的HashMap<Person, Integer> person2age等。
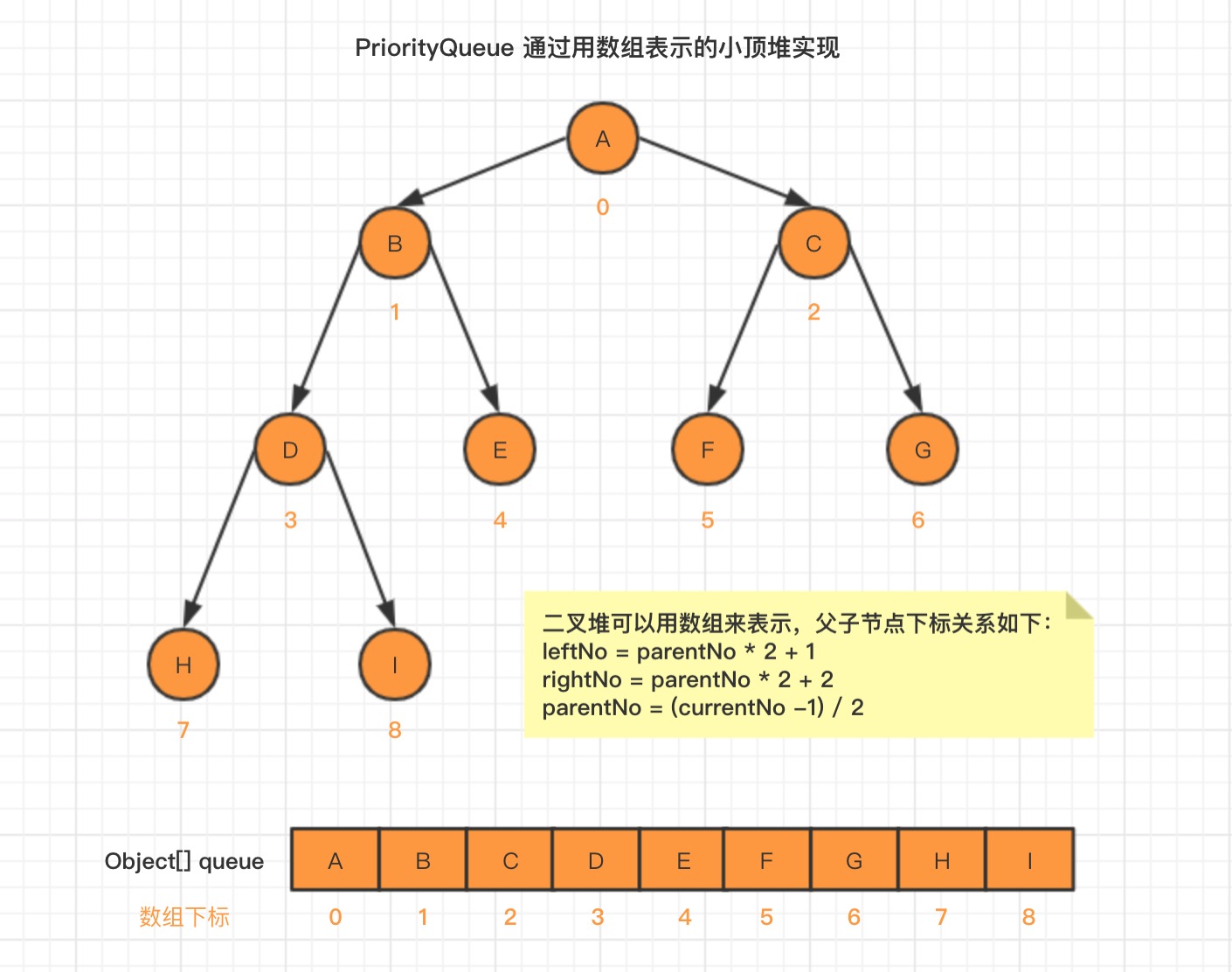
此次作业还特别用到了PriorityQueue,对外接口是队列的设计,底层实现是小顶堆的数据结构。在迪杰斯特拉算法的优化中起到重要作用。
四、性能问题
本单元给出的JML规格并未有性能规定,但数据强测对程序性能具有严格的要求。
数据结构的优化参照☝。
除去最基本的子功能方法与优化困难的一些特殊方法外,关键影响性能的可优化方法有以下几个:
Network中的isCircle(),queryBlockSum(),sendIndirectMessage();
Group中的getValueSum(),getAgeMean(),getAgeVar();
isCircle()自然语言描述即查询两个节点在图中是否连通。笔者第一次作业通过bfs+查集实现,即在每次bfs时记录此连通分支的节点情况,存入缓存,新的查询指令到来时首先在缓存中查询,失败后再进行bfs,而每一次添加关系均冲刷缓存。在后两次作业中完全改为并查集,即通过一个list嵌套HashMap存储图的连通分支,在每次添加关系时更新目前连通分支的状态。
queryBlockSum()即为查询连通块的数目。如果按JML直接莽不做任何优化,本方法将吃掉秒级的CPU时间,直接造成超时。连通块的数目与☝连通判断逻辑上紧密关联。笔者通过维护一个Integer,在每次更新并查集时更新该整数,记录连通块数目,大大降低时间复杂度。
sendIndirectMessage()主要涉及的是最短路径算法。笔者通过堆优化+迪杰斯特拉算法实现寻路。迪杰斯特拉算法每轮需要添加可接触的最短边到集合中,而维护一个小顶堆即可通过每次取堆顶元素来实现。如☝所写,小顶堆可通过JAVA自带的PriorityQueue实现,同时笔者设计了Edge类做为基本元素参与到堆实现中,存储了两端点和边的权重。
getValueSum()自然语言描述为求群中人与人直接所有关系的权重之和(每条边计算两次,但自圈不计算)。笔者维护了整数ValueSum,每次添加Person时更新,查询时直接返回该值。(似乎并未减小时间复杂度)。
getAgeMean()即求群中年龄平均数。维护年龄和ageSum,查询时返回ageSum / person2age.size()计算结果即可。需要注意的是,按照JML规格,此处有int除法精度损失,在优化时需要保留该损失。
getAgeVar()即求群中年龄方差,通过数学运算将公式拆解,分别维护年龄平方和agePowerSum、年龄和ageSum,在查询时通过(agePowerSum + size * mean * mean - 2 * ageSum * mean) / size返回计算值。此处同样有int除法精度损失,需要保留。
五、作业架构设计
本单元作业描述了一个社交网络系统。
基本节点为Person,Person本身有ID、name、age、SocialValue、Money等属性。
Person间通过内置的邻接表表示节点间的关系与权重,进而形成了关系网络。
多个Person可以建群Group,群有ID等属性。
Person可以给其他Person或Group发送Message,即单发/群发消息。
Message又分为基础Message、NoticeMessage、RedEnvelopeMessage和EmojiMessage,不同种类的消息对发送人和接收人/群的属性有不同的影,。例如红包消息会改变相关Person的金钱属性,有趣的是发红包的人也会抢红包。
在Network中维护Emojis、messages来存储目前有的表情和消息,而每个Person也会存储接收到的消息。
2021-05-31

