
《面向对象设计与构造》课设第一单元总结回顾
一、概述
第一单元的Project主要围绕表达式的解析、求导和输出与化简。
在三次作业全部结束后,返回来揣摩题意,笔者认为,课程组将这一题目设为第一次作业,可能部分原因在于表达式和求导这样的概念非常严谨且数学化,其文法规范、方法规则同学们也十分熟悉,更容易上手,不容易产生歧义和误解。另外,表达式中的项、因子等概念本身就富有层次化结构,方便引导同学使用继承、多态等方法,初步建立面向对象的构造思维。
按照自然流派的思路,万事万物都可以抽象为对象。在第一单元作业中,上至表达式,下至底层的加减、空白符,理论上都可以为其设计一个类,总体架构就形成一个巨大的层次结构(确实有人这样做)。但当类的设计过于下放于底层时,类的数量激增,程序的可读性、可维护性都会一定程度地下降(当然这种设计还是要比一个类包打天下合适得多)。所以寻找抽象与细节的Tradeoff就显得十分重要了。笔者认为在本次作业乃至以后的职业生涯中,可能需要一直学着去寻找这样的Balance。
二、第一次作业
-
整体感受
第一次作业总体而言十分简单,属于热身级别,但笔者认为做得最糟糕的也是第一次作业。虽然这是三次作业中分数拿得最高的一次,但程序的可迭代性、可维护性等方面做得相当差。但换个角度想,这是不是也为后面留出了进步空间呢 : ) 。
-
类的架构设计
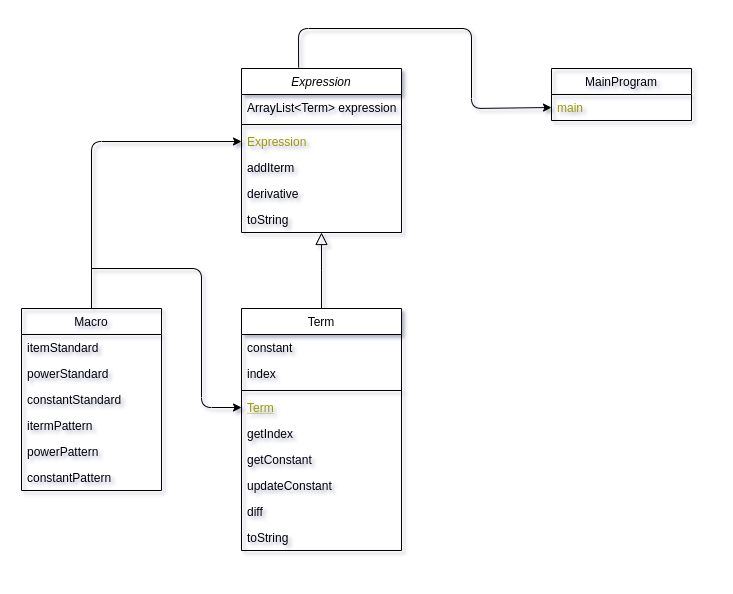
如上图所示,核心的类只有两个:Expression 和 Term,底层的大量细节被全部收纳在了Term类中,导致其复杂度爆表。
当时笔者从题目出发,认为项中的因子只有两个:constant 和 power,遂将其抽象为Term中的两个属性:constant 和 index。是的,甚至省略了底数。因为每一个项最多由系数、固定底数x和指数三者组成,所以独立地看,这样的设计似乎没有什么问题。若从可迭代性来看,这真的是很糟糕、很敷衍的设计。
-
度量分析
| Class | CBO | DIT | LCOM | NOC | RFC | WMC |
|---|---|---|---|---|---|---|
| Expression | 3 | 1 | 1 | 0 | 23 | 16 |
| Term | 2 | 1 | 1 | 0 | 23 | 19 |
| MainProgram | 2 | 1 | 1 | 0 | 11 | 1 |
| Macro | 3 | 1 | 6 | 0 | 7 | 6 |
| Total | 42 | |||||
| Average | 2.50 | 1.00 | 2.25 | 0.00 | 16.00 | 10.50 |
从上表可以看出,两个核心类和main类的RFC非常高,即其与其他类的耦合性很高,频繁的互相调用显示着最初设计的缺陷。由于大量细节被收纳于Term类中,其Weighted Methods达到19才满足了设计要求,Expression类有同样的问题。
-
核心功能设计分析
如上文概述中所写,核心功能分为三部分:解析表达式、求导、输出与化简。
第一次作业中,由于没有不存在嵌套等复杂组成形式,所以笔者选择了超级无敌大正则来进行匹配解析,甚至在一个引号内写完了整个项的正则匹配法则,而没有通过使用小的正则变量组合更上一级的正则。笔者认为唯一做得较好的是设计了一个类收纳静态的正则表达式变量以及compile。在空白字符的处理上,笔者选择了无脑replaceAll,一个非常权宜但在当时又确实省力的过滤方法。
在求导方面,Term对象中,只需将index--,更新系数即可(当然还需要特判index为0的情况);Expression对象中,只需将list中所有的Term依次求导即可。
输出时,底层产生基本字符串,上层负责拼接底层传出的字符串。在化简方面,由于第一次作业项的组成非常单一,故在解析时我加入了根据index合并的逻辑;输出时,项对象会根据指数系数情况调整,故是一个很大的if-else段。(形似第一次实验课代码中toString的逻辑)
-
Bug分析
第一次作业整体形式比较简单,编码、自测也很少出bug。但互测在同学中出现很多爆栈的情况,需要注意。
强测互测未被hack,互测hack 3人次。Bug点均在于爆栈。
三、 第二次作业
-
整体感受
第二次作业是一次痛苦的破蛹,两天内重构两次,最终由全正则转为递归下降。
第一次重构原因在于,第一次作业笔者在Term一级下没有留出任何迭代拓展空间,要适应第二次作业的三角函数与表达式因子,就需要对整体架构作大幅的修改,甚至不如重构来得舒服。
第二次重构是因为笔者做了很多尝试,但始终无法使用单纯的正则方法去解决因子与表达式的嵌套关系。最终自学递归下降的解析方法,又一次重构代码,完成了作业要求。
-
类的架构设计
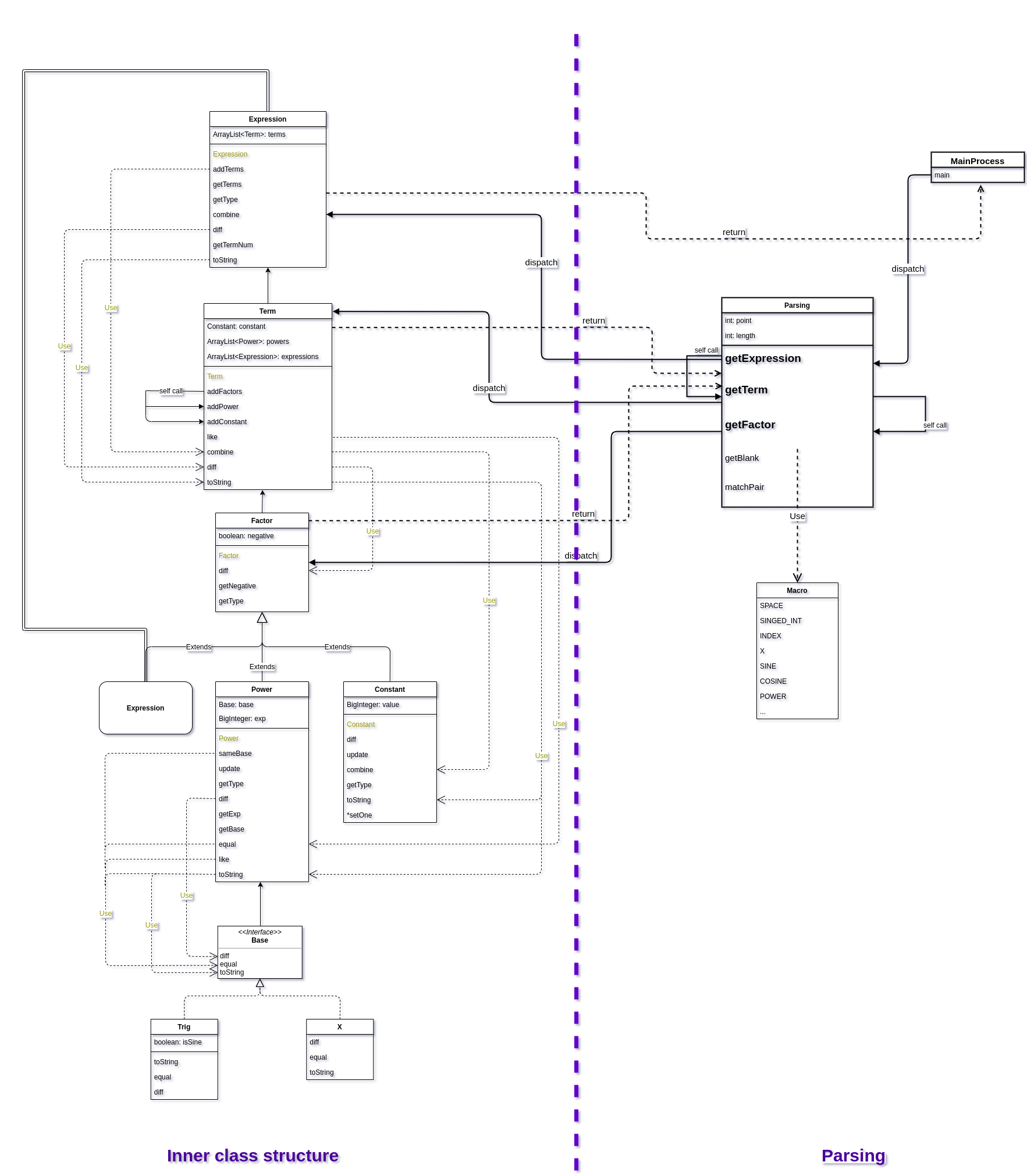
如上图所示(画了近两个小时的图: ( ),笔者将用于存储表达式结构的类和用于解析表达式的类分而治之。
在左侧inner class structure设计中,大量使用接口、继承和多态来统一抽象管理不同的子模块,大大降低了代码复杂度,同时也增强了工程的可迭代性。
整体自上而下地抽象为Expression、Term和Factor三个关键类,而底层丰富的细节由Factor这个父类进行统一管理。Constant、Power和Expression三个子类继承自Factor(没有使用接口主要是考虑到因子解析时以及求导后符号管理的问题,父类保留了一个略冗余的boolean: negative)。
Power类带有两个属性:Base: base与BigInteger: exp。exp代表指数,而base代表底数。是的,笔者自作聪明地自行抽象了指数型函数,而没有按指导书所给幂函数与三角函数的平行设计。笔者认为,这两种因子使用相同的求导规则,具有非常相似的结构。更何况,如果在第三次作业中要求表达式也能作为底数,那么何妨预先设计指数型函数这样的类型呢?(后来实际并没有提出这样的需求,假预言家)
底数Base类作为接口,管理着三角底数Trig与X,抽象出求导diff、判断等价equal、输出字符串toString的三个方法。
在Parsing的一边,是伟大的递归下降算法。通过递归下降算法,将复杂的解析过程完全抽离成层次化的结构,极大地简化了代码复杂度,而且就像红莲哥斯拉秒杀基多拉一样秒杀了各种套娃结构。在parsing中,每一个解析函数只需要管理好自己那一层的解析方法即可,若遇到下一层的成分,则直接调用下一层对应的解析函数即可。
-
度量分析
Class CBO DIT LCOM NOC RFC WMC Expression 4 2 2 0 20 14 Term 5 1 1 0 37 44 Factor 8 1 3 3 6 4 Constant 4 2 3 0 15 9 Power 9 2 2 0 36 19 Base 4 Trig 3 1 2 0 8 9 X 3 1 3 0 7 5 Parsing 7 1 1 0 22 26 MainProgress 2 1 1 0 8 1 Total 137 Average 4.70 1.30 2.40 0.30 15.55 13.70 通过对度量值分析可以看出,在工程复杂度大大增加的背景下,RFC均值不升反降,WMC也保持较低水平,各度量值整体处于合理区间。
-
核心功能设计分析
在第一次作业中,对表达式的解析完全耦合在表达式各层类的构造函数中,其复杂度相当高,可维护性极差。重构之后,表达式解析部分几乎完全与存储部分分开,不同功能模块耦合度大大降低。递归下降算法也大大简化了解析过程,使其条理清晰,可迭代性好。
通过对表达式高度地层次化整理,求导时只需调用顶层表达式对象的求导方法,其可自动调用下一层的求导方法,层层调用,最终返回新的表达式结构。
简化部分实际仍然高度耦合于构建表达式与toString的过程中,在构建的过程中程序会识别同类项并进行合并,输出时会检查系数、指数等参数和是否去括号来缩短字符串长度。所以我通过求导前后多次解析、输出来达到化简的目的,效果甚佳,应该说是一个懒办法。这个办法给第三次作业埋了雷。
-
Bug分析
事实上,本次作业的优化代码出现了严重且经典的Bug,导致强测掉了两个点、互测被hack一次。这个Bug就是多个引用指向同一个地址空间。
在多因子相乘的项中,若有表达式因子且括号里只有一项,优化算法要去括号、提取系数。这是合理的事。然而求导后,一个项裂解成多项,但其中很多项的表达式因子未导而保持不变。雷就埋在这里:笔者的程序直接copy了引用,相当于求导后的多个表达式因子引用都指向同一个地址空间。在化简过程中,将其中一项的系数置一后,其余关联部分系数也均置1。通过深拷贝可以修复这个Bug。
由于强测掉2个点,进入非顶级房间,hack 20+人次。由于房间等级较低,Bug数较多,依靠本地测评机Auto Data模式即揪出大量Bug。
四、 第三次作业
-
整体感受
在经历了第二次作业重构的痛苦挣扎后,第三次作业真的有爽到。针对三角函数内部可填充因子的新需求,只稍微调整了Parsing类与Trig类即完成要求;针对Wrong Format判定要求,只在Parsing类中添加了一些捕获异常的代码即完成要求。
在完成了第二次作业的编写后,笔者对递归下降的理解又加深了一层,且出于判WF的需要,笔者迭代优化了parsing类,使其使用更少的正则表达式,加深了递归的层次,从Factor层深入到Power的底数和指数层。
第三次作业合计耗时三个小时。
-
类的设计架构
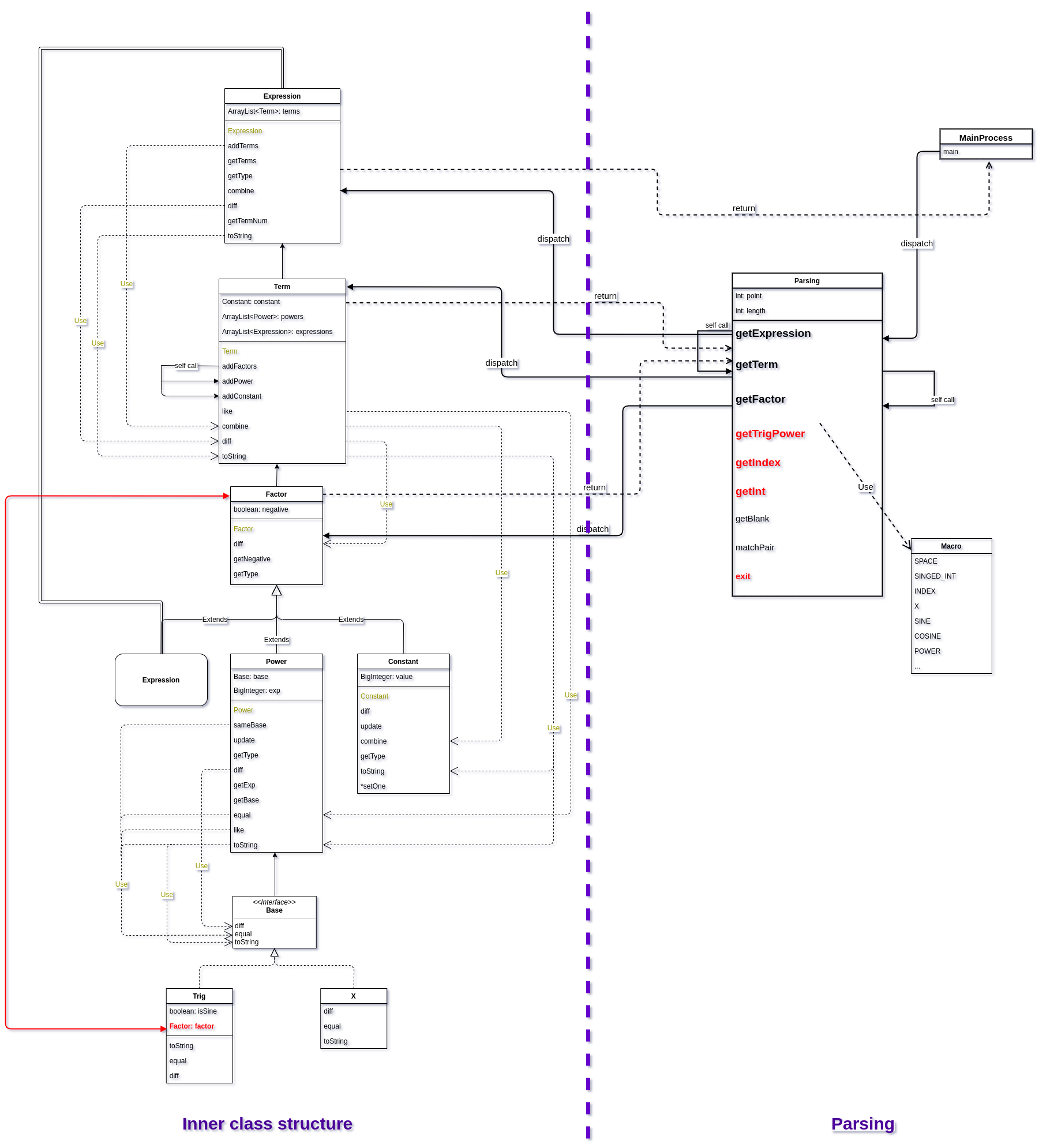
上图红色的部分即为第三次作业较第二次作业增添的部分(一些细节性的修改略过不计)。可以看出,整体架构基本没有任何修改,也从侧面证明了之前设计的合理性。
-
度量分析
| Class | CBO | DIT | LCOM | NOC | RFC | WMC |
|---|---|---|---|---|---|---|
| Expression | 5 | 2 | 2 | 0 | 20 | 15 |
| Term | 6 | 1 | 1 | 0 | 36 | 45 |
| Factor | 7 | 1 | 4 | 3 | 8 | 6 |
| Constant | 5 | 2 | 3 | 0 | 13 | 7 |
| Power | 7 | 2 | 2 | 0 | 27 | 16 |
| Base | 4 | |||||
| Trig | 7 | 1 | 3 | 0 | 15 | 15 |
| X | 4 | 1 | 3 | 0 | 7 | 5 |
| Parsing | 9 | 1 | 1 | 0 | 32 | 41 |
| MainProgress | 2 | 1 | 1 | 0 | 8 | 1 |
| Macro | 1 | 1 | 6 | 0 | 8 | 6 |
| Total | 157 | |||||
| Average | 5.30 | 1.30 | 2.60 | 0.30 | 16.18 | 15.70 |
可以看到,本次作业度量值与第二次作业基本接近,保持在合理区间。
-
核心功能分析
解析、求导与化简输出逻辑基本沿袭第二次作业。主要增量在于添加了WF功能。概括来说,由于递归下降算法严格依照形式化定义设计,若各级成功返回结果,则认为形式正确;若某一级不能返回正确结果,则判WF,exit code 0。
鉴于第二次作业优化导致强测崩溃,心态也有点炸裂,所以第三次作业笔者只做了基础的优化,没有作更多尝试,以稳为主。
-
Bug分析
第二次作业有提到通过多次解析和输出来达到优化的目的,笔者试图将这种方法也应用于第三次作业中。得益于同学提醒,本次作业对指数范围有非常严格的限制,若使用多次解析,负值边界的指数会引发错误的WF报告,遂作罢。
强测互测未被hack,hack 2人次。Bug点十分奇妙,被Hack者的代码会认为cos(9)和cos(7)完全相同。笔者观测认为,这是hash的数据结构没有组织好的缘故。
五、 总结思考
三次作业结束,个人认为收获很大,主要体现在以下一些方面:
-
对类和对象及其属性与方法有了更深入的理解,在同步进行的冯如杯项目中“现学现卖”,运用了面向对象的方法。
-
对面向对象的编程思维有了新的认识。封装、继承、多态、接口、父类与子类、设计模式等概念有了真切的体会和使用的经验。
-
与朋友搭伙完成了第一单元测评机的开发和维护,对自查、互测有非常大的帮助。同时第一次体会到根据自己的需求,而非课程要求,设计程序的快感。
-
增长了管理几个乃至十几个文件(类)的经验。虽然计组也曾有管理十几个文件的较大工程的经历,但毕竟是偏向硬件和设计模式较为固定的编码,与这样开放程度大的纯软件开发经验是处在不同维度的。
-
对未来可能需求的预判十分重要。第一次作业完全没有考虑后期的迭代开发问题,两次痛苦的重构与第二三次作业的完美衔接形成了鲜明的对比。虽然第二次作业所预判的表达式底数没有用上,但并不影响功能的正常运行,且抽象程度更高,管理基本功能更方便。
2021-03-28

