随便写的python爬虫(有空就一直更新)
1 漫画爬虫
当时觉得漫画不错
然后写了一个爬虫把漫画爬下来明天找时间看完
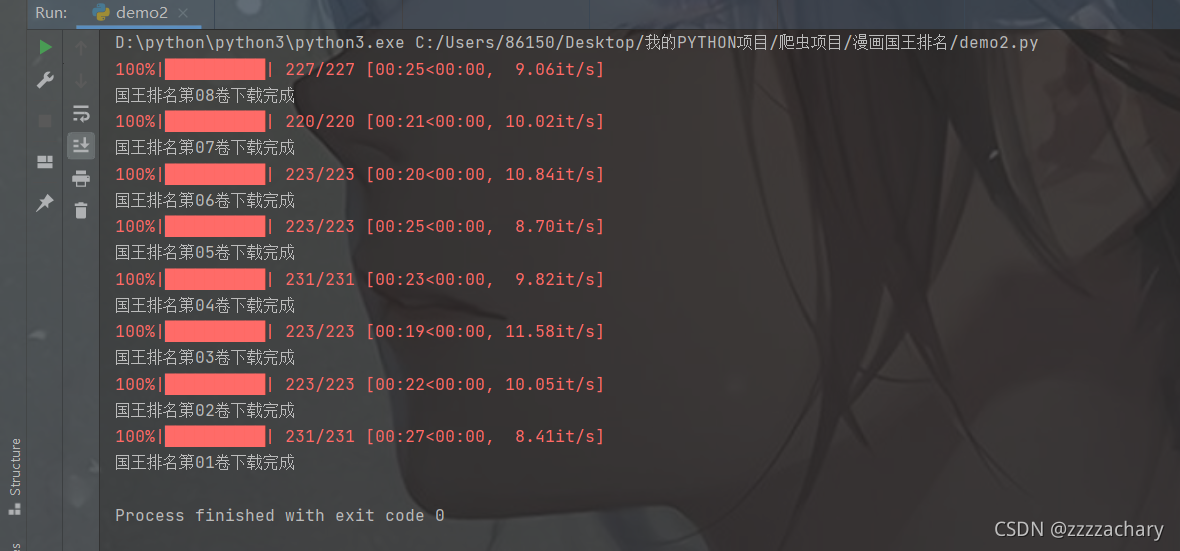

分享一下代码:
import requests
from bs4 import BeautifulSoup
import re
import os
from contextlib import closing
from tqdm import tqdm
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36"
,"Referer": "https://manhua.dmzj.com/guowangpaiming/116550.shtml"
}
def get_imgurl(url0,url1): #url0是该章节的首页 url1是该章节的第一个图片的地址
rsp = requests.get(url=url0, headers=header)
rsp.encoding = 'utf-8'
bs = BeautifulSoup(rsp.text, 'lxml')
script_info = bs.script
# 利用正则将script其中的图片页数提取出来
nums = re.findall('\|(\d{4})', str(script_info))
nums.sort(reverse=True)
urls = []
for num in nums:
urls.insert(0,url1[:-8] + num + ".jpg")
#返回一个章节的图片地址数组
return urls
def get_chapers(url0): #url0是该漫画的首页地址
change_ref(url0)
rsp = requests.get(url=url0, headers=header)
rsp.encoding = 'utf-8'
bshtml = BeautifulSoup(rsp.text, 'lxml')
chaperlist = bshtml.find('div', class_="cartoon_online_border")
chapers = chaperlist.find_all('a')
chaperurls = []
chapernames = []
for chaper in chapers:
chaperurls.insert(0, "https://manhua.dmzj.com/" + chaper.get('href'))
chapernames.insert(0, "国王排名" + chaper.text)
#返回漫画的所有章节首地址和章节名(数)
return chapernames,chaperurls
def get_firstimgurl(chapernum): #chapernum是该章节的章节数
url = "https://images.dmzj.com/g/%E5%9B%BD%E7%8E%8B%E6%8E%92%E5%90%8D/%E7%AC%AC"+chapernum+"%E5%8D%B7/0000.jpg"
#返回某章节第一个图片地址
return url
#该方法是因为我发现第一张的url不是卷编码 而是话编码,所以给第一章用这个函数
def get_firstimgurl1():
return "https://images.dmzj.com/g/%E5%9B%BD%E7%8E%8B%E6%8E%92%E5%90%8D/%E7%AC%AC01%E8%AF%9D/0000.jpg"
def down_img(url,num,dirname): #url是图片地址 ,num是图片编号,chapername是文件夹名
with closing(requests.get(url, headers=header, stream=True)) as response:
chunk_size = 1024
if response.status_code == 200:
with open(dirname+'/'+num+'.jpg', "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
else:
print('链接异常')
def change_ref(chaperurl):
global header
header['Referer'] = chaperurl
#url0是漫画首页
url0 = "https://manhua.dmzj.com/guowangpaiming"
#chapername是每一章的名字,chaperurl是每一章的首页
chapernames,chaperurls = get_chapers(url0)
for i in range(len(chaperurls)):
chapernum = chapernames[i][-3:-1]
chapername= chapernames[i]
chaperurl = chaperurls[i]
firstimgurl = get_firstimgurl(chapernum) if i<len(chaperurls)-1 else get_firstimgurl1()
imgurls = get_imgurl(chaperurl,firstimgurl)
os.mkdir(chapername)
for imgurl in tqdm(imgurls):
down_img(imgurl,imgurl[-8:-4],chapername)
print(chapername+"下载完成")
2 B站视频弹幕爬虫
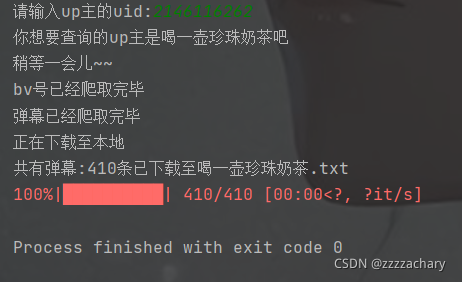
如果只是想获取弹幕文件呢,用之前的代码就浪费太多时间了。
所以用B站官方的api做了一点改进。(没有查到除了b站官方api之外的其他方便的下载弹幕的方法)
效果如下:

代码如下:
import requests
import json
from tqdm import tqdm
from bs4 import BeautifulSoup
from xml.dom.minidom import parseString
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36"}
def get_resp_text(url):
rsp = requests.get(url,headers=headers)
rsp.encoding = 'utf-8'
return rsp.text
def get_upname(mid):
global upname
rsp = requests.get('https://space.bilibili.com/'+mid)
rsp.encoding = 'utf-8'
html = rsp.text
bss = BeautifulSoup(html, 'lxml')
return (bss.find('title').text[:-len('的个人空间_哔哩哔哩_Bilibili')])
def get_bvid(mid):
i = 1
bvid = []
while i != 0:
url0 = 'https://api.bilibili.com/x/space/arc/search?mid=' + str(
mid) + '&ps=30&tid=0&pn=&keyword=&order=pubdate&jsonp=jsonp'
url0 = url0[:-len('&keyword=&order=pubdate&jsonp=jsonp')] + str(
i) + '&keyword=&order=pubdate&jsonp=jsonp'
i += 1
rsp = requests.get(url0, headers=headers)
rsp.encoding = 'utf-8'
html = rsp.text
dict = json.loads(html.replace('\n', ''))
datadict = dict['data']
listdict = datadict['list']
vlist = listdict['vlist']
if len(vlist) == 0:
i = 0
elif len(vlist) != 0:
for _ in range(len(vlist)):
bvid.insert(0, vlist[_]['bvid'])
print("bv号已经爬取完毕")
return bvid
def get_cid_url(bvid):
cid_url = []
for bid in bvid:
cid_url.insert(0,'https://api.bilibili.com/x/player/pagelist?bvid=' + str(bid) + '&jsonp=jsonp')
return cid_url
def get_cids(cid_urls):
cids = []
for cid_url in cid_urls:
str = get_resp_text(cid_url)
jsonstr = json.loads(str)
jsrdata = jsonstr['data']
jsrdict = jsrdata[0]
cids.insert(0,jsrdict['cid'])
return cids
def get_xml_url(cids):
xml_urls = []
for cid in cids:
xml_urls.insert(0,'https://api.bilibili.com/x/v1/dm/list.so?oid='+str(cid))
return xml_urls
def get_xmls(xml_urls):
xmls = []
for xml_url in xml_urls:
xmls.insert(0,get_resp_text(xml_url))
return xmls
def get_danmus(xmls):
danmus = []
for xml in xmls:
tanmus = parseString(xml).documentElement.getElementsByTagName('d')
for tanmu in tanmus:
tanmu = tanmu.childNodes[0].data
danmus.insert(0, tanmu)
print("弹幕已经爬取完毕"+'\n正在下载至本地')
return danmus
def save_danmus(upname,danmus):
with open(upname+".txt",'w',encoding='utf-8') as f:
for danmu in tqdm(danmus):
f.write(danmu+"\n")
print("共有弹幕:" + str(len(danmus)) + "条已下载至"+upname+".txt")
if __name__ =='__main__':
uid = input("请输入up主的uid:")
upname = get_upname(uid)
print("你想要查询的up主是" + upname + "吧" + "\n稍等一会儿~~")
bvid = get_bvid(uid)
cid_urls = get_cid_url(bvid)
cids = get_cids(cid_urls)
xml_urls = get_xml_url(cids)
xmls = get_xmls(xml_urls)
danmus = get_danmus(xmls)
save_danmus(upname, danmus)
3 微博热搜爬虫
import requests
import re
from bs4 import BeautifulSoup
#headers能帮助我们过反爬虫机制
headers = {
'cookie': 'SINAGLOBAL=4619433481639.479.1605711663593; SUB=_2AkMVT4KQf8NxqwJRmfsXy27naoh1ywvEieKjE3NLJRMxHRl-yT8XqhQctRB6Ps-sf8H874GXYTVL_t7H5WTQ3vmbkDCV; _s_tentry=-; Apache=7183559745320.718.1646900490938; ULV=1646900490954:18:1:1:7183559745320.718.1646900490938:1642686548027; UOR=,,www.jianshu.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.36',
}
def get_hotsearch():
url = 'https://s.weibo.com/top/summary'
res = requests.get(url=url,headers=headers)
r = BeautifulSoup(res.text,'html.parser')
s = r.find_all('a',attrs={'target':'_blank'}) #热搜的字符串内容都放在了a标签中
result = []
for i in range(1,len(s)-10): #这里第0条是最近上升,所以i从1开始
print(s[i])
pattern = '>(.*)</a>'
text = re.search(pattern,str(s[i])) #得到正则匹配的字符串对象 例:<re.Match object; span=(145, 160), match='>吉林农业科技学院疫情</a>'>
result.append(text.group(1)+str(50-i))
return result
print(get_hotsearch())
4 对我校发布期刊的数据统计
# -*- coding:utf-8 -*-
import os #引用os系统库
import tkinter.filedialog as tf #引用Pyhon内置的文件对话框模块
import re #引用内置的正则表达式模块
import pandas as pd #引用用于数据处理统计分析的pandas库
import numpy as np #引用numpy库
import matplotlib.pyplot as plt #引用matplotlib.pyplot模块用于作图
import wordcloud #word云
cpath = tf.askdirectory() #这一步选择excel所在的文件夹
os.chdir(cpath) #将cpath设置当前目录
weipufile = tf.askopenfilename() #这一步选择Excel文件
dwp = pd.read_excel(weipufile) #利用pandas的read_excel方法来读取我们选择的Excel
dwp.rename(columns=dict(zip(dwp.columns,[re.sub('\s','',x) for x in dwp.columns])),inplace=True) #使用正则,调整字段名称格式,去掉其中的空白字符
dwp1=dwp.query('机构.str.contains("成都信息工程")') #筛选机构字段包含“成都信息工程”的数据
print("数据记录的总数量为:%d"%len(dwp1)) #查看数据记录的数量
# print(dwp1.年)
# print(dwp1['年'].value_counts()) #用value_counts方法统计
# print(dwp1['年'].apply(lambda x:str(x)+'年').value_counts()) #为了符合使用习惯,在年度数据后面加上“年”
print(dwp1['年'].apply(lambda x:str(x)+'年').value_counts().sort_index()) #将统计结果按索引排序——即按年度排序
tjjg_year=dwp1['年'].apply(lambda x:str(x)+'年').value_counts().sort_index()#将年度统计结果赋值给变量tjjg_year
# tjjg_year.to_excel('year1.xlsx') #将年度统计结果保存到当前目录
# tjjg_year1 = tjjg_year.reset_index().rename(columns={'index':'年','年':'发文数量'}) #调整统计结果的结构和字段名称 赋值给变量tjjg_year1
# tjjg_year1.to_excel('year2.xlsx') #保存到Excel
def show(x,choose):
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', '黑体'] # 正常显示中文标签
plt.rcParams.update({'figure.autolayout': True}) # 自动适应布局
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
#柱状图
if choose == 1:
plt.bar(x.index, x.values)
plt.title('本校2017年以来中文期刊论文数量情况')
for x, y in zip(np.arange(len(x)), tjjg_year.values, ):
plt.text(x + 0.05, y + 0.05, '%d' % y, ha='center', va='bottom')
#条形图
elif choose == 2:
plt.barh(np.arange(len(x)), left=0, height=0.5, width=x.values, tick_label=x.index)
for x, y in zip(x.values, np.arange(len(x))):
plt.text(x + 25, y + 0.05, '%d' % x, ha='center', va='bottom')
plt.title('本校2017年以来中文期刊论文数量情况')
#饼状图
elif choose == 3:
plt.pie(x.values, labels=x.index, autopct='%1.1f%%', ) # 做饼图
plt.title('本校2017年以来中文期刊论文占比情况') # 设置标题
#折线图
elif choose == 4:
plt.plot(np.arange(len(tjjg_year)), tjjg_year.values, c='r', ls='-.', marker='o', label=tjjg_year.name)
for x, y, z in zip(np.arange(len(tjjg_year)), tjjg_year.values, tjjg_year.index):
plt.text(x + 0.05, y + 0.05, '%s\n%d' % (z, y), ha='center', va='bottom')
# 添加节点文字
plt.ylim(0, max(tjjg_year.values) + 100) # 增加Y轴上限
plt.title('本校2017年以来中文期刊论文数量情况') # 显示标题
plt.legend() # 显示图例
else:
print("输入错误!")
return 0
return plt
def guanjianci_yuntu(dwp):
gjc = dwp.关键词.dropna().apply(lambda x: re.sub('\[.*?\]', '', x)) # 清楚空白行,替换[*]为空
gjc1 = gjc.apply(lambda x: [y.strip() for y in x.split(';') if y.strip()])
gjc2 = gjc1.apply(pd.value_counts)
gjc3 = gjc2.unstack().dropna().reset_index().groupby(by='level_0').count().reset_index().rename(
columns={'level_0': '关键词', 'level_1': '频次'}).sort_values(by='频次')
gjc3.to_excel('关键词.xlsx')
wc = wordcloud.WordCloud(font_path='simhei.ttf', background_color='white', scale=5)
wc.generate_from_frequencies(dict(zip(gjc3.关键词, gjc3.频次)))
fig = plt.figure(figsize=(8, 8))
fig.suptitle('本校2017年以来中文期刊论文关键词词云图', fontsize=26)
plt.axis('off') # 隐藏坐标轴
plt.imshow(wc) # 生成词云图
plt.show() # 显示图片
return 0
def guanjianci_zhexian(dwp):
ngjc = dwp[['年', '关键词']] # 筛选“关键词”、“年”字段
ngjc1 = ngjc.astype('str').query('关键词.str.contains("青藏高原|气象学|气候变化|降水|时空分布|教学改革")') # 筛选包含指定关键词的数据
ngjc1.关键词 = ngjc1.关键词.dropna().apply(lambda x: re.sub('\[.*?\]', '', x)) # 清楚空白行,替换[*]为空
ngjc1.关键词 = ngjc1.关键词.apply(lambda x: [y.strip() for y in x.split(';') if y.strip()]) # 关键词以分号(;)分割
ngjc_qzgy = ngjc1.关键词.apply(pd.value_counts).set_index(ngjc1.年).unstack().dropna().loc['青藏高原'].groupby(
by='年').count().sort_index() # 指定关键词统计
ngjc_qxx = ngjc1.关键词.apply(pd.value_counts).set_index(ngjc1.年).unstack().dropna().loc['气象学'].groupby(
by='年').count().sort_index()
ngjc_qhbh = ngjc1.关键词.apply(pd.value_counts).set_index(ngjc1.年).unstack().dropna().loc['气候变化'].groupby(
by='年').count().sort_index()
ngjc_js = ngjc1.关键词.apply(pd.value_counts).set_index(ngjc1.年).unstack().dropna().loc['降水'].groupby(
by='年').count().sort_index()
ngjc_skfb = ngjc1.关键词.apply(pd.value_counts).set_index(ngjc1.年).unstack().dropna().loc['时空分布'].groupby(
by='年').count().sort_index()
ngjc_jxgg = ngjc1.关键词.apply(pd.value_counts).set_index(ngjc1.年).unstack().dropna().loc['教学改革'].groupby(
by='年').count().sort_index()
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', '黑体'] # 正常显示中文标签
plt.rcParams.update({'figure.autolayout': True}) # 自动适应布局
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
plt.plot(np.arange(len(ngjc_qzgy)), ngjc_qzgy.values, ls='-.', marker='o', label='青藏高原') # 做折线图
plt.plot(np.arange(len(ngjc_qxx)), ngjc_qxx.values, ls='-.', marker='o', label='气象学')
plt.plot(np.arange(len(ngjc_qhbh)), ngjc_qhbh.values, ls='-.', marker='o', label='气候变化')
plt.plot(np.arange(len(ngjc_js)), ngjc_js.values, ls='-.', marker='o', label='降水')
plt.plot(np.arange(len(ngjc_skfb)), ngjc_skfb.values, ls='-.', marker='o', label='时空分布')
plt.plot(np.arange(len(ngjc_jxgg)), ngjc_jxgg.values, ls='-.', marker='o', label='教学改革')
plt.xticks(np.arange(len(ngjc_qzgy)), labels=ngjc_qzgy.index)
plt.legend()
plt.title('本校2017年以来中文期刊论文高频关键词年度趋势')
plt.show()
return 0
show(tjjg_year,int(input("选择图形(1,2,3,4 --即柱形,条形,饼状,折线):\n"))).show()
#guanjianci_zhexian(dwp=dwp)
# guanjianci_yuntu(dwp=dwp)




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现