windows口令加密复现与PCFG算法还原
 1.利用相关工具抓取本机的windows口令文件,调用OpenSSL中的算法生成口令hash,验证两者的一致性。
2.利用PCFG算法和部分泄露的口令库生成一个口令集,测试一下是否能还原Windows登录密码?
1.利用相关工具抓取本机的windows口令文件,调用OpenSSL中的算法生成口令hash,验证两者的一致性。
2.利用PCFG算法和部分泄露的口令库生成一个口令集,测试一下是否能还原Windows登录密码?
这里所说的相关工具选择mimikatz,给出其下载链接
http://www.ddooo.com/softdown/133908.htm
我们的实验环境为Win7虚拟机环境
对其口令进行抓取
mimikatz # log
mimikatz # privilege::debug
mimikatz # sekurlsa::logonpasswords
可以得到
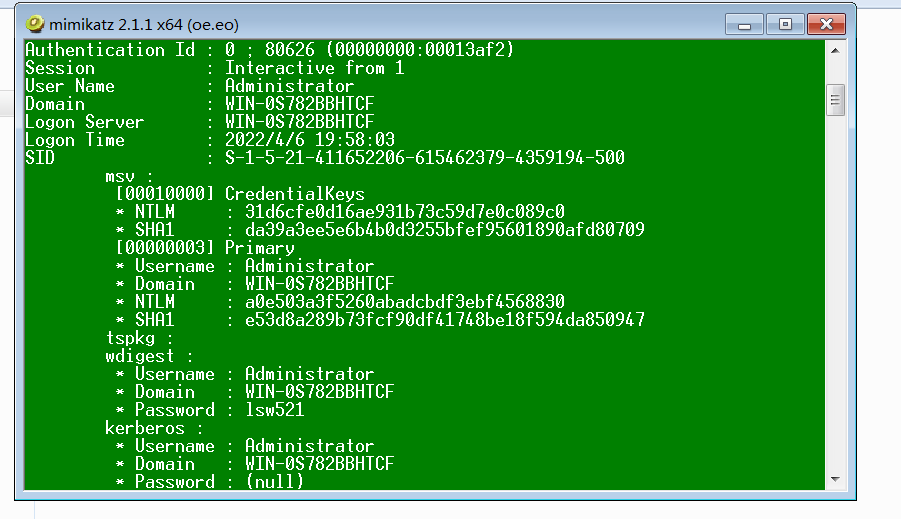
LM-Hash
第一步 将明文口令转换为其大写形式
lsw521->LSW521
第二步 将字符串大写后转换为16进制字符串
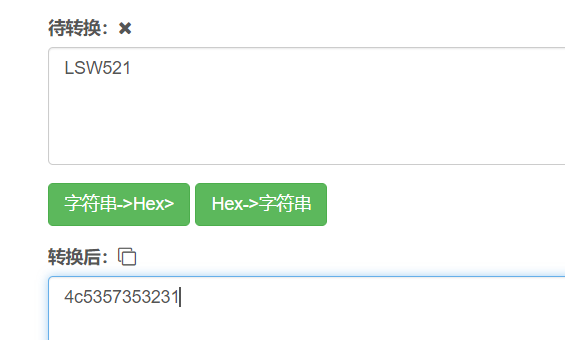
第三步 密码不足14字节要求用0补全
4C53573532310000000000000000
第四步 将上述编码分成2组7字节(56bits=14*4)的数据
4C535735323100 和 00000000000000
第五步 将每一组7字节的十六进制转换为二进制,每7bit一组末尾加0,再转换成十六进制组成得到2组8字节的编码
第一组:
1001100001010010101010101100110010100110001000101000100000000000
9852aacca6228800
第二组:
0000000000000000
第六步 以上步骤得到的两组8字节编码,分别作为DES加密key为魔术字符串“KGS!@#$% ”进行加密
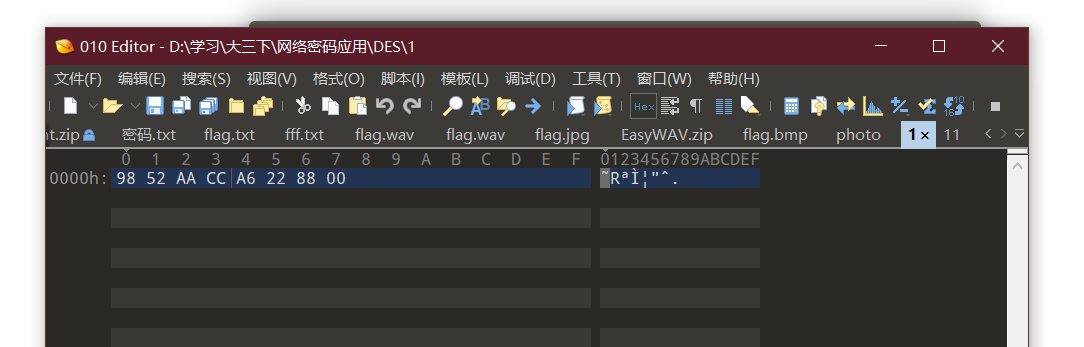
将其openssl加密
OpenSSL> des -k KGS!@#$% -in 1 -out 11
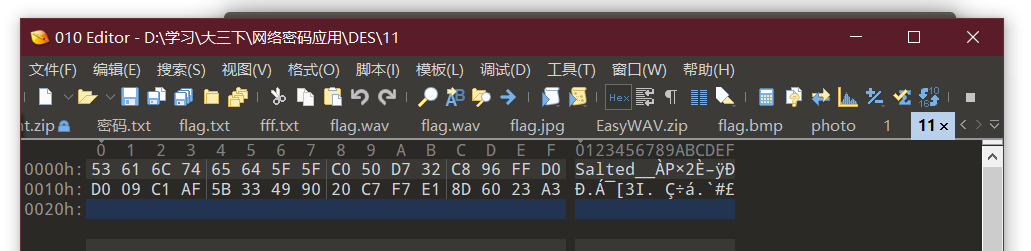
后者同理
在这时我想比对的时候才发现,LM已经没有了,无法比对呜呜呜呜呜呜呜
NTLM-Hash
第一步 ASCII转Unicode

第二步 MD4单向加密
OpenSSL> dgst -md4 uni
MD4(uni)= a0e503a3f5260abadcbdf3ebf4568830

与上面得到的系统得到结果比较
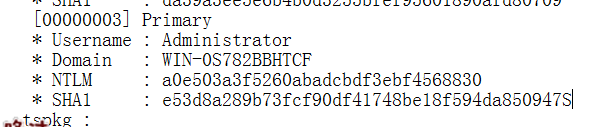
完全一致!!!
2.利用PCFG算法和部分泄露的口令库生成一个口令集,测试一下是否能还原Windows登录密码?
2.1 数据预处理
打开老师给的口令集,发现里面既有账号又有密码,而且两组数据集给出的格式还不一样,因此第一步要提取密码 对于人人网的数据集
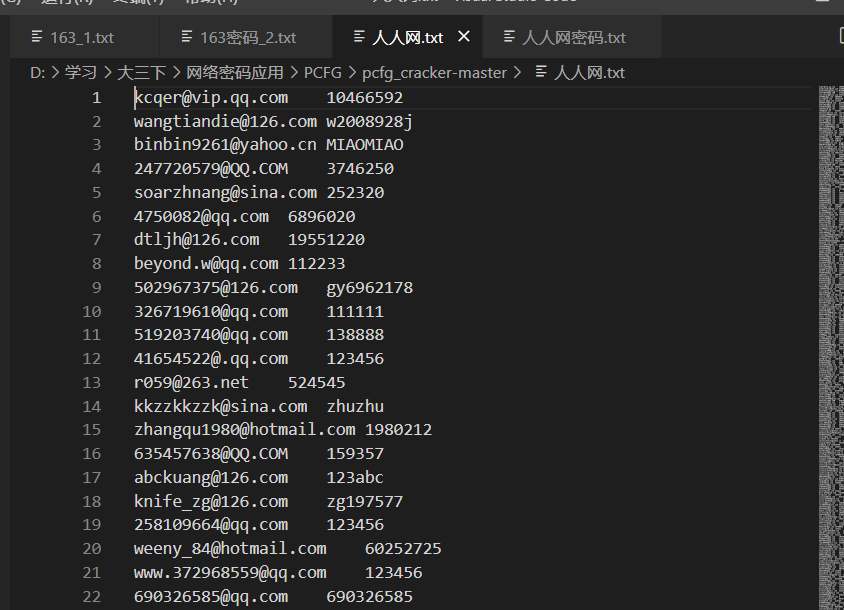
其密码由tab键相隔,因此取tab键之间的部分就可以
# 导入 re 模块
import re
f = open('人人网.txt','r',encoding='latin1')
line = f.readlines()
f.close()
f = open('人人网密码.txt','w+',encoding='latin1')
for j in range(0,len(line)):
for i in range(0,len(line[j])):
if(line[j][i]=='\t'and i<len(line[j])):
password=line[j][i+1:len(line[j])-2]
ti=password+'\n'
f.write(ti)
print("Finish 人人网")
f.close()
f = open('163.txt','r',encoding='latin1')
line = f.readlines()
f.close()
f = open('163密码.txt','w+',encoding='latin1')
for j in range(0,len(line)):
li=re.findall('----([0-9]*[a-z]*[A-Z]*[\x00-\xff]*)----',line[j])
f.write(li)
print("Finish 人人网")
f.close()
生成密码集为
对于163的数据,其包含两种类型:
第一种是用户名+密码+邮箱
第二种是邮箱+密码
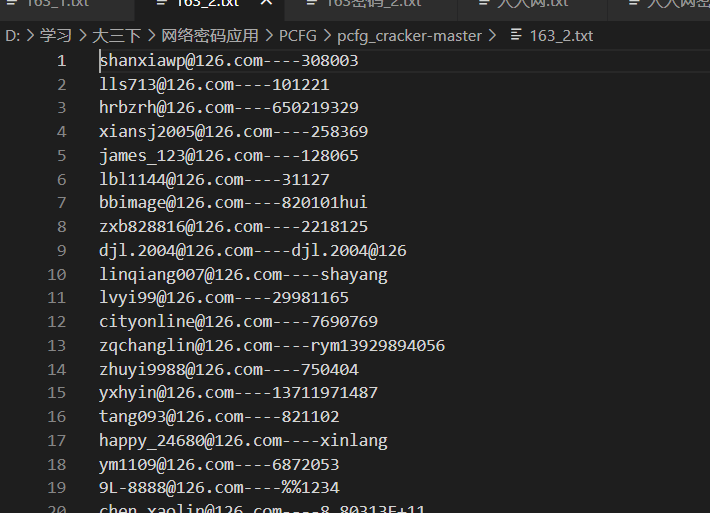
分别对其用正则表达式解决:
import re
f = open('163_2.txt','r',encoding='latin1')
line = f.readlines()
f.close()
f = open('163密码_2.txt','w+',encoding='latin1')
for j in range(0,len(line)):
a=str(line[j])
li=re.findall('----([0-9]*[a-z]*[A-Z]*[\x00-\x80]*)\n',a)
lit=str(li)[2:len(li)-3]+"\n"
f.write(lit)
print("Finish 163_2")
f.close()
f = open('163_1.txt','r',encoding='latin1')
line = f.readlines()
f.close()
f = open('163密码_1.txt','w+',encoding='latin1')
for j in range(0,len(line)):
a=str(line[j])
li=re.findall('----([0-9]*[a-z]*[A-Z]*[\x00-\x80]*)----',a)
lit=str(li)[2:len(li)-3]+"\n"
f.write(lit)
print("Finish 163_1")
f.close()
得到结果
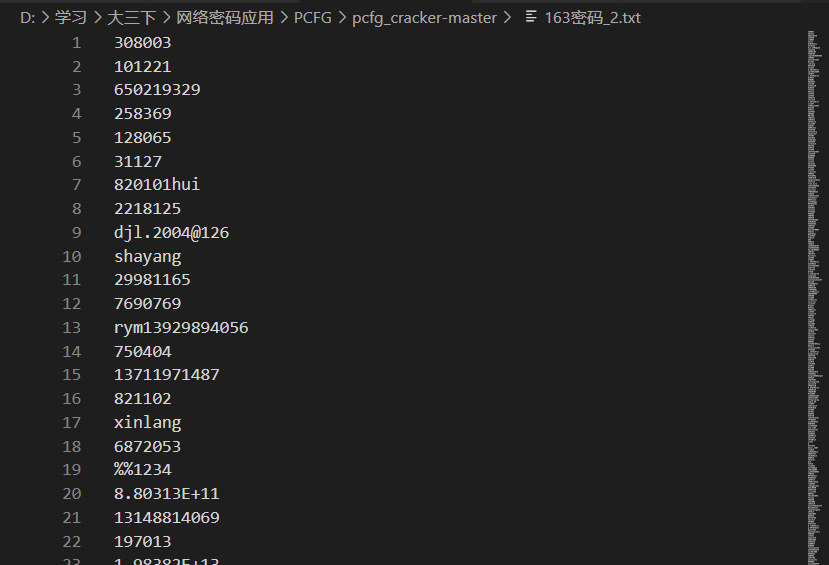
最后将人人网和163的字典合并
2.2 生成规则集
下载得到PCFG源码,并将字典导入
打开spyder,运行trainer.py
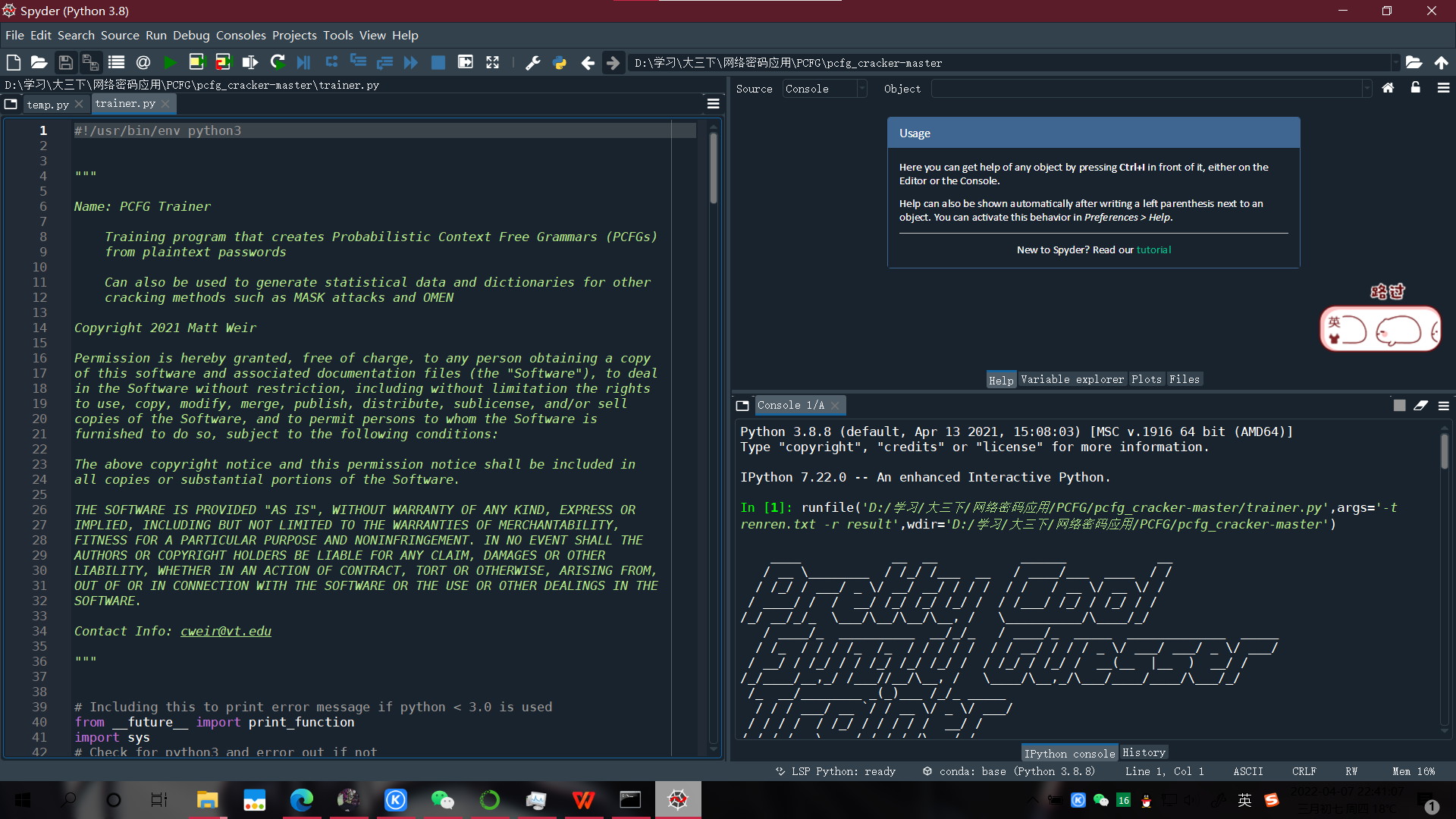
In [7]: runfile('D:/学习/大三下/网络密码应用/PCFG/pcfg_cracker-master/trainer.py',args='-t train.txt -r result',wdir='D:/学习/大三下/网络密码应用/PCFG/pcfg_cracker-master')
____ __ __ ______ __
/ __ \________ / /_/ /___ __ / ____/___ ____ / /
/ /_/ / ___/ _ \/ __/ __/ / / / / / / __ \/ __ \/ /
/ ____/ / / __/ /_/ /_/ /_/ / / /___/ /_/ / /_/ / /
/_/ __/_/_ \___/\__/\__/\__, / \__________/\____/_/
/ ____/_ __________ __/_/_ / ____/_ _____ _____________ _____
/ /_ / / / /_ /_ / / / / / / / __/ / / / _ \/ ___/ ___/ _ \/ ___/
/ __/ / /_/ / / /_/ /_/ /_/ / / /_/ / /_/ / __(__ |__ ) __/ /
/_/____/__,_/ /___//__/\__, / \____/\__,_/\___/____/____/\___/_/
/_ __/________ _(_)___ /_/_ _____
/ / / ___/ __ `/ / __ \/ _ \/ ___/
/ / / / / /_/ / / / / / __/ /
/_/ /_/ \__,_/_/_/ /_/\___/_/
Version: 4.3
-----------------------------------------------------------------
Attempting to autodetect file encoding of the training passwords
-----------------------------------------------------------------
File Encoding Detected: utf-8
Confidence for file encoding: 0.938125
If you think another file encoding might have been used please
manually specify the file encoding and run the training program again
-------------------------------------------------
Performing the first pass on the training passwords
What we are learning:
A) Identify words for use in multiword detection
B) Identify alphabet for Markov chains
C) Duplicate password detection, (duplicates are good!)
-------------------------------------------------
Printing out status after every million passwords parsed
------------
1 Million
2 Million
Number of Valid Passwords: 2253866
Number of Encoding Errors Found in Training Set: 0
-------------------------------------------------
Performing the second pass on the training passwords
What we are learning:
A) Learning Markov (OMEN) NGRAMS
B) Training the core PCFG grammar
-------------------------------------------------
Printing out status after every million passwords parsed
------------
1 Million
2 Million
-------------------------------------------------
Calculating Markov (OMEN) probabilities and keyspace
This may take a few minutes
-------------------------------------------------
OMEN Keyspace for Level : 1 : 436
OMEN Keyspace for Level : 2 : 4540
OMEN Keyspace for Level : 3 : 41678
OMEN Keyspace for Level : 4 : 305908
OMEN Keyspace for Level : 5 : 1818836
OMEN Keyspace for Level : 6 : 9407907
OMEN Keyspace for Level : 7 : 42976466
OMEN Keyspace for Level : 8 : 176582831
OMEN Keyspace for Level : 9 : 699890971
OMEN Keyspace for Level : 10 : 2578401879
OMEN Keyspace for Level : 11 : 8816523722
-------------------------------------------------
Performing third pass on the training passwords
What we are learning:
A) What Markov (OMEN) probabilities the training passwords would be created at
-------------------------------------------------
1 Million
2 Million
-------------------------------------------------
Top 5 e-mail providers
-------------------------------------------------
126.com : 246
qq.com : 35
163.com : 9
sina.com : 6
sohu.com : 4
-------------------------------------------------
Top 5 URL domains
-------------------------------------------------
6.com : 33
126.com : 15
q.com : 13
dospy.com : 11
123.com : 8
-------------------------------------------------
Top 10 Years found
-------------------------------------------------
2008 : 1363
2009 : 1148
1987 : 1063
1988 : 917
1986 : 831
1989 : 788
1985 : 648
1984 : 597
1990 : 510
1983 : 507