MapRuduce编程实践——从WordCount(词频统计)到InvertedIndex(倒排索引)的源码改编
 与网上大量倒排索引代码不同,我们仅需要统计文档名,无需统计索引次数,因此不需要进行所谓的两次reduce操作下面,我们在WordCount的基础上进行改编
与网上大量倒排索引代码不同,我们仅需要统计文档名,无需统计索引次数,因此不需要进行所谓的两次reduce操作下面,我们在WordCount的基础上进行改编
上一节Ubuntu16.04 MapReduce WordCount代码详解与eclipse运行方式中我们对WordCount的源码进行了解读,并使用Eclipse进行了运行,下面我们挑战MapReduce的另一个经典应用——倒排索引
所谓倒排索引,是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。 它主要是用来存储某个单词(或词组) 在一个文档或一组文档中的存储位置的映射,即提 供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进 行相反的操作,因而称为倒排索引( Inverted Index),如下图所示
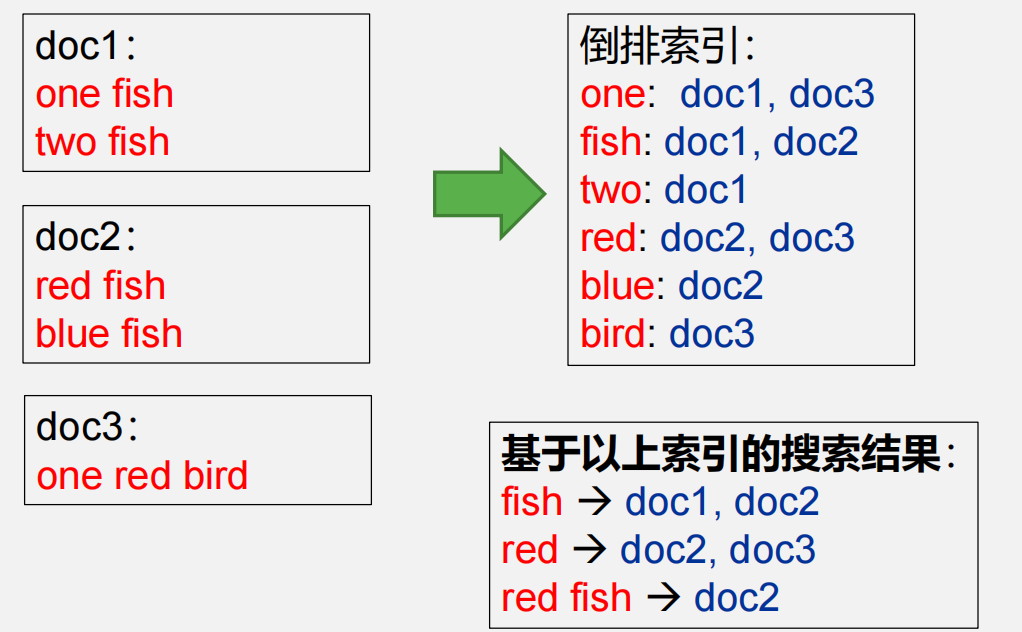
与网上大量代码不同,我们仅需要统计文档名,无需统计索引次数,因此不需要进行所谓的两次reduce操作下面,我们在WordCount的基础上进行改编
swap空间扩充

由于从本实验开始将对很大的数据集进行处理,因此需要对swap内存空间进行扩充,若swap分区没有空间,会出现无法分配内存而导致MapReduce失败的情况
打开终端,首先创建swap分区的文件
$ dd if=/dev/zero of=swapfile bs=1M count=2048

然后格式化分区文件

提高权限,打开swap分区文件
$ sudo su # swapon swapfile

添加开机自启
修改/etc/fstab这个文件,添加或者修改这一行:swapfile swap swap defaults 0 0
# vim /etc/fstab
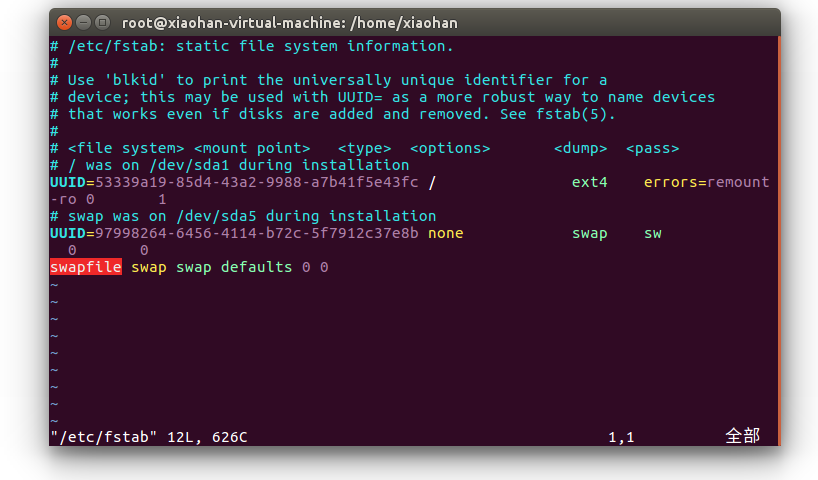
按Ins,可以插入,修改好后,按Esc,键入:wq保存退出
现在再查看内存,哇,扩大了三倍多

上传输入数据
一定先开启服务!!!!!!!!!
$ /usr/local/hadoop/sbin/start-all.sh
将需要进行倒排索引的文件放入data文件夹,将此文件夹置于 /home/xiaohan/文档 文件夹下
data共465篇文档,共46.7M
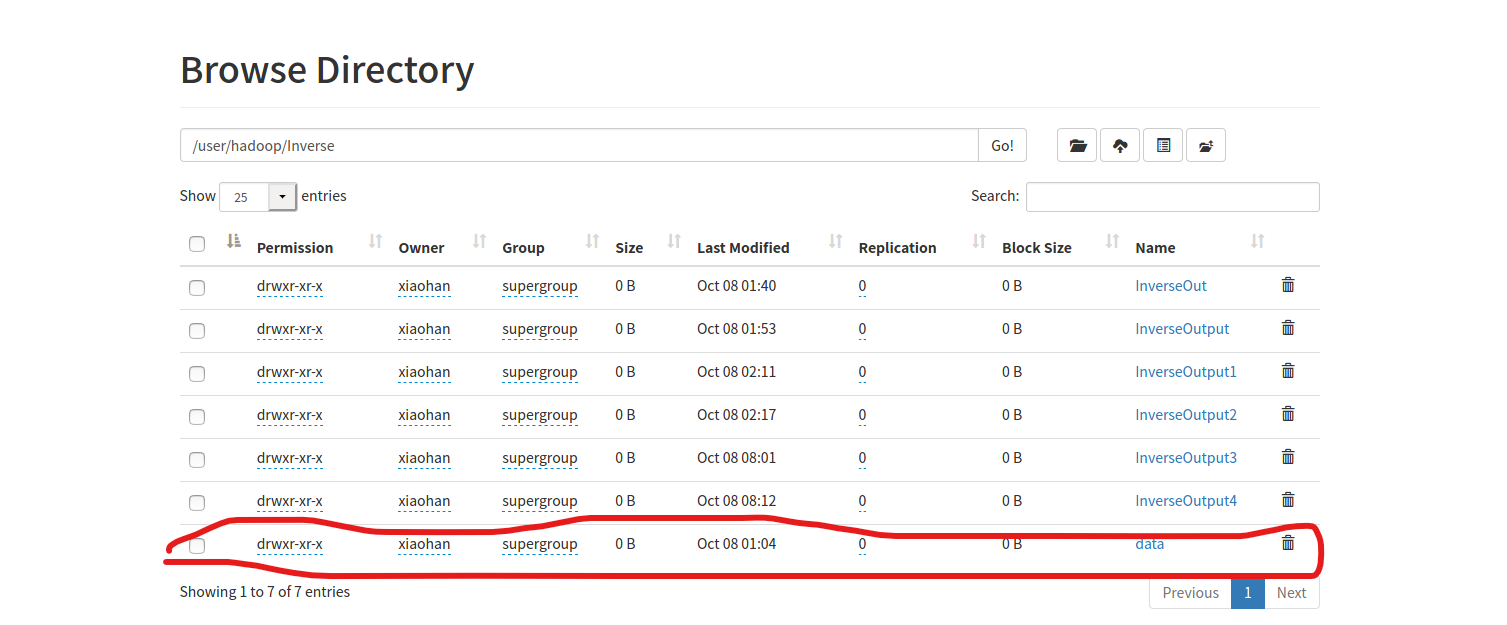
在hdfs上建立本项目的块(我在之前已经建立/user/hadoop目录),并上传data
$ hdfs dfs -mkdir /user/hadoop/Inverse $ hdfs dfs -put /home/xiaohan/文档/data /user/hadoop/Inverse
在localhost:9870上,我们可以看到上传输入数据成功
Map改编方法
下面正式进入WordCount到倒排索引的改编
首先,对照WordCount的Map部分,我们要知道哪里发生变化

WordCount输入的是一个文档的单词,而倒排索引的输入既包括文档内容,也包括文件名,仅此相比于WordCount,我们还需要获取文件名并存储
因此需要增加下面语句获取文件名
FileSplit filesplit=(FileSplit) context.getInputSplit(); String filename =filesplit.getPath().getName();//获取文件名 Text fileName_lineOffset = new Text(filename);
并且在存储时将文件名写入存储
for(;itr.hasMoreTokens();)
{
word.set(itr.nextToken());//返回当前位置到下一个分隔符之间的字符串
context.write(word,fileName_lineOffset);//将word和文件名存到容器
}
Reduce改编方法

在WordCount中,Reduce部分主要是做求和运算,而倒排索引显然不是这样子的,因此Reduce需要进行大的改动,来实现拼接操作
Iterator<Text> it = values.iterator();//调用集合的方法iterator()获取出Iterator接口的实现类的对象
StringBuilder word = new StringBuilder();//StringBuilder是一个可变的字符串类,我们可以把它看成是一个容器,这里的可变指的是StringBuilder对象中的内容是可变的
if(it.hasNext())//判断集合是否有元素
{ word.append(it.next().toString());//调用方法next()取出集合中的元素
//for(;it.hasNext();) {
word.append("@");
word.append(it.next().toString());
}
context.write(key,new Text( word.toString()));//输出结果到hdfs
}
Main改编方法
基本不变,注意将类名进行修改即可
需要注意的是,由于输入的文件为多个,原来的单一输入路径需要修改
for (int i = 0; i < otherArgs.length - 1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));//确定每个输入文件的路径
}
完整代码展示
倒排索引结果
参照WordCount的运行方法进行操作得到结果
为200M的结果文件
