
数据预处理之清洗
''' 数据的清洗 1.检测与处理重复值 2.检测与处理缺失值 3.检测与处理异常值 ''' import numpy as np import pandas as pd # 去重:按照A列去重,同时保留第一个数据且在原表去重 data = pd.DataFrame({'A': [1, 1, 2, 2], 'B': ['a', 'b', 'a', 'b']}) print(data) # 对A列去重 # data.drop_duplicates('A', 'first', inplace=True) # print(data) # 对所有列去重 # data.drop_duplicates('first',inplace=True) # print(data) # 检测重复值:默认按照行 duplicates = data.duplicated() print(duplicates) # 检测重复值:按照列 duplicates = data.duplicated(['A']) print(duplicates) # 处理缺失值 # 删除法 dates = pd.date_range('20130101', periods=6) df = pd.DataFrame(np.arange(24).reshape((6, 4)), index=dates, columns=['A', 'B', 'C', 'D']) df.iloc[0, 1] = np.nan df.iloc[1, 2] = np.nan print(df) df1 = df.dropna(axis=0, how='any', inplace=False) print(df1) # 替换法 df2 = df.fillna(value=0) print(df2) # 判断是否有缺失值 df3 = df.isnull() print(df3) # 统计数据中一共出现多少缺失值 print(df3.sum()) # 每一列缺失值个数(默认形式) print(df3.sum(axis=1)) # 每一行缺失值个数 print(df3.sum().sum()) # 数据整体出现缺失值个数 # 判断整个数据中是否存在缺失数据 df4 = np.any(df.isnull()) == True print(df4) 输出结果 A B 0 1 a 1 1 b 2 2 a 3 2 b 0 False 1 False 2 False 3 False dtype: bool 0 False 1 True 2 False 3 True dtype: bool A B C D 2013-01-01 0 NaN 2.0 3 2013-01-02 4 5.0 NaN 7 2013-01-03 8 9.0 10.0 11 2013-01-04 12 13.0 14.0 15 2013-01-05 16 17.0 18.0 19 2013-01-06 20 21.0 22.0 23 A B C D 2013-01-03 8 9.0 10.0 11 2013-01-04 12 13.0 14.0 15 2013-01-05 16 17.0 18.0 19 2013-01-06 20 21.0 22.0 23 A B C D 2013-01-01 0 0.0 2.0 3 2013-01-02 4 5.0 0.0 7 2013-01-03 8 9.0 10.0 11 2013-01-04 12 13.0 14.0 15 2013-01-05 16 17.0 18.0 19 2013-01-06 20 21.0 22.0 23 A B C D 2013-01-01 False True False False 2013-01-02 False False True False 2013-01-03 False False False False 2013-01-04 False False False False 2013-01-05 False False False False 2013-01-06 False False False False A 0 B 1 C 1 D 0 dtype: int64 2013-01-01 1 2013-01-02 1 2013-01-03 0 2013-01-04 0 2013-01-05 0 2013-01-06 0 Freq: D, dtype: int64 2 True
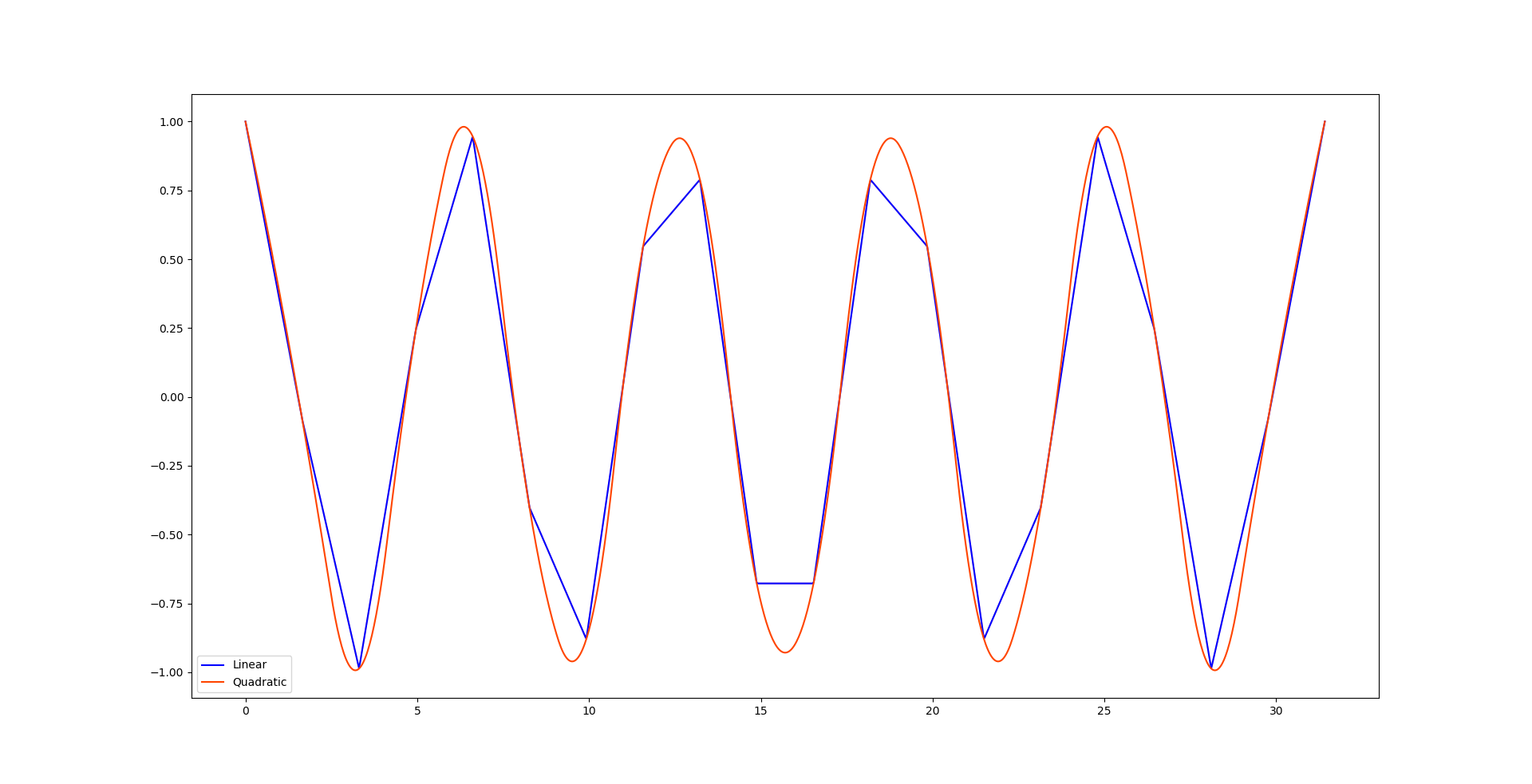
''' 数据清洗之缺失值插值法 ''' import numpy as np from scipy.interpolate import interp1d import matplotlib.pyplot as mp # 创建待插值的数据 x = np.linspace(0, 10 * np.pi, 20) y = np.cos(x) # 分别使用linear和quadratic插值 f1 = interp1d(x, y, kind='linear') fq = interp1d(x, y, kind='quadratic') # 设置x的最大值和最小值以防止插值数据越界 xint = np.linspace(x.min(), x.max(), 1000) yint1 = f1(xint) yintq = fq(xint) # 线性插值和二阶插值效果 mp.plot(x, y, color='pink') mp.plot(xint, yint1, color='blue', label='Linear') mp.plot(xint, yintq, color='orangered', label='Quadratic') mp.legend() mp.show()
''' 数据清洗---异常值处理 ''' import numpy as np import pandas as pd df = pd.DataFrame(np.random.randn(4, 4) * 4 + 3) print(df) # 离差标准化 df_norm = (df - df.min()) / (df.max() - df.min()) print(df_norm) # 标准差标准化 df_norm = (df - df.mean()) / df.std() print(df_norm) 输出结果: 0 1 2 3 0 5.163514 1.087991 11.144715 -1.082642 1 0.932404 2.191543 7.219776 3.437653 2 9.983589 0.218654 6.576483 0.321555 3 5.253907 3.771512 8.672818 4.734098 0 1 2 3 0 0.467465 0.244687 1.000000 0.000000 1 0.000000 0.555296 0.140819 0.777118 2 1.000000 0.000000 0.000000 0.241406 3 0.477452 1.000000 0.458894 1.000000 0 1 2 3 0 -0.045926 -0.475946 1.352387 -1.089516 1 -1.190051 0.244107 -0.583957 0.588309 2 1.257460 -1.043177 -0.901322 -0.568312 3 -0.021483 1.275017 0.132892 1.069518

