sklearn之学习曲线
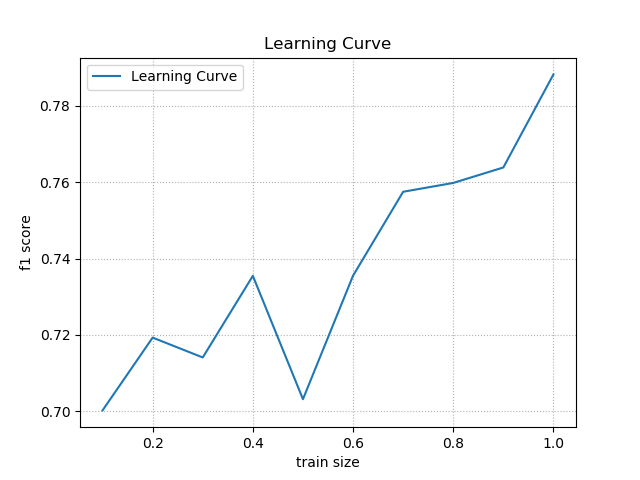
''' 学习曲线:模型性能 = f(训练集大小) 学习曲线所需API: _, train_scores, test_scores = ms.learning_curve( model, # 模型 输入集, 输出集, [0.9, 0.8, 0.7], # 训练集大小序列 cv=5 # 折叠数 ) 案例:在小汽车评级案例中使用学习曲线选择训练集大小最优参数。 ''' import numpy as np import matplotlib.pyplot as mp import sklearn.preprocessing as sp import sklearn.ensemble as se import sklearn.model_selection as ms import sklearn.metrics as sm import warnings warnings.filterwarnings('ignore') data = [] with open('./ml_data/car.txt', 'r') as f: for line in f.readlines(): sample = line[:-1].split(',') data.append(sample) data = np.array(data) # print(data.shape) # 整理好每一列的标签编码器encoders # 整理好训练输入集与输出集 data = data.T # print(data.shape) encoders = [] train_x, train_y = [], [] for row in range(len(data)): encoder = sp.LabelEncoder() if row < len(data) - 1: # 不是最后列 train_x.append(encoder.fit_transform(data[row])) else: # 是最后一列,作为输出集 train_y = encoder.fit_transform(data[row]) encoders.append(encoder) train_x = np.array(train_x).T # 训练随机森林分类器 model = se.RandomForestClassifier(max_depth=6, n_estimators=150, random_state=7) # 绘制学习曲线 train_sizes = np.linspace(0.1, 1, 10) _, train_scores, test_scores = ms.learning_curve(model, train_x, train_y, train_sizes=train_sizes, cv=5) print(test_scores) print(np.mean(test_scores,axis=1)) # 训练之前进行交叉验证 cv = ms.cross_val_score(model, train_x, train_y, cv=4, scoring='f1_weighted') print(cv.mean()) model.fit(train_x, train_y) # 自定义测试集,预测小汽车的等级 # 保证每个特征使用的标签编码器与训练时使用的标签编码器匹配 data = [ ['high', 'med', '5more', '4', 'big', 'low', 'unacc'], ['high', 'high', '4', '4', 'med', 'med', 'acc'], ['low', 'low', '2', '4', 'small', 'high', 'good'], ['low', 'med', '3', '4', 'med', 'high', 'vgood']] data = np.array(data).T test_x, test_y = [], [] for row in range(len(data)): encoder = encoders[row] # 每列对应的标签编码器 if row < len(data) - 1: test_x.append(encoder.transform(data[row])) # 这里需要训练了,直接转换 else: test_y = encoder.transform(data[row]) test_x = np.array(test_x).T pred_test_y = model.predict(test_x) print(pred_test_y) pred_test_y = encoders[-1].inverse_transform(pred_test_y) test_y = encoders[-1].inverse_transform(test_y) print(pred_test_y) print(test_y) # 画图显示学习曲线 mp.figure('Learning Curve', facecolor='lightgray') mp.title('Learning Curve') mp.xlabel('train size') mp.ylabel('f1 score') mp.grid(linestyle=":") mp.plot(train_sizes, np.mean(test_scores, axis=1), label='Learning Curve') mp.legend() mp.show() 输出结果: [[0.69942197 0.69942197 0.69942197 0.69942197 0.70348837] [0.67630058 0.79768786 0.69942197 0.71965318 0.70348837] [0.66184971 0.70231214 0.75433526 0.74855491 0.70348837] [0.71098266 0.78323699 0.74277457 0.73988439 0.7005814 ] [0.71387283 0.71965318 0.5982659 0.74277457 0.74127907] [0.71387283 0.76878613 0.70809249 0.74855491 0.73837209] [0.71387283 0.7716763 0.72254335 0.82080925 0.75872093] [0.71387283 0.76878613 0.72254335 0.83526012 0.75872093] [0.71387283 0.7716763 0.73121387 0.83526012 0.76744186] [0.73121387 0.76878613 0.72254335 0.8583815 0.86046512]] [0.70023525 0.71931039 0.71410808 0.735492 0.70316911 0.73553569 0.75752453 0.75983667 0.763893 0.78827799] 0.7477732938195376 [2 0 0 3] ['unacc' 'acc' 'acc' 'vgood'] ['unacc' 'acc' 'good' 'vgood']