#安装scipy,numpy,sklearn包
import numpy as np
#从sklearn包自带的数据集中读出鸢尾花数据集data
from sklearn.datasets import load_iris
iris = load_iris()
#查看data类型,包含哪些数据
print(type(iris))
#取出鸢尾花特征和鸢尾花类别数据,查看其形状及数据类型
print(iris.keys())
print(iris['data'])

#取出所有花的花萼长度(cm)的数据
iris_len=np.array(list(len[0] for len in iris['data']))
print(iris_len)
#取出所有花的花瓣长度(cm)+花瓣宽度(cm)的数据
for len_width in iris['data']:
print(len_width[2],len_width[3])
#取出某朵花的四个特征及其类别。
print(iris['data'][0],iris['feature_names'][0])

#将所有花的特征和类别分成三组,每组50个
iris_a=[]
iris_b=[]
iris_c=[]
for i in range(0,150):
if iris['target'][i]==0:
data1=iris['data'][i].tolist()
data1.append('a')
iris_a.append(data1)
elif iris['target'][i]==1:
data1=iris['data'][i].tolist()
data1.append('b')
iris_b.append(data1)
else:
data1=iris['data'][i].tolist()
data1.append('c')
iris_c.append(data1)

#生成新的数组,每个元素包含四个特征+类别
datas=np.array([iris_a,iris_b,iris_c])
print(datas)
#计算鸢尾花花瓣长度的最大值,平均值,中值,均方差。
data_len=np.array(list(len[2] for len in iris['data']))
print(data_len)
print(np.max(data_len))
print(np.mean(data_len))
print(np.median(data_len))
print(np.std(data_len))

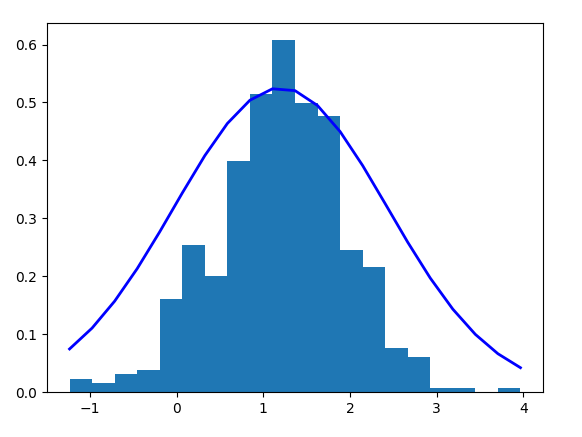
#显示鸢尾花花瓣长度的正态分布图
import numpy as np
import matplotlib.pyplot as plt
mu=np.mean(petal_length)
sigma=np.std(petal_length)
num=10000
rand_data = np.random.normal(mu, sigma, num)
count, bins, ignored = plt.hist(rand_data, 30, normed=True)
plt.plot(bins, 1 /(sigma * np.sqrt(2 * np.pi)) * np.exp(- (bins - mu) ** 2 / (2 * sigma ** 2)), linewidth = 2, color= "r")
plt.show()
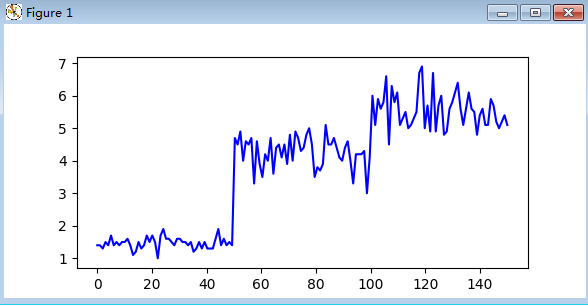
#显示鸢尾花某一特征的曲线图,散点图。
import matplotlib.pyplot as plt
plt.plot(np.linspace(0,150,num=150),data_len,'b') #花瓣曲线图
plt.show()
plt.scatter(np.linspace(0,150,num=150),data_len,marker='o')#花瓣图
plt.show()
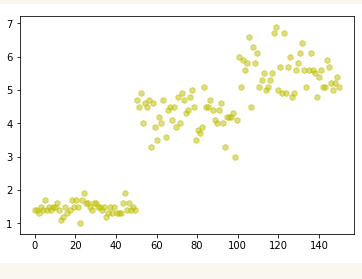
#显示鸢尾花花瓣长度的散点图
import numpy as np
import matplotlib.pyplot as plt
plt.scatter(np.linspace(0,150,num=150),petal_length,alpha=0.5,marker='h',color='y')
plt.show()