|
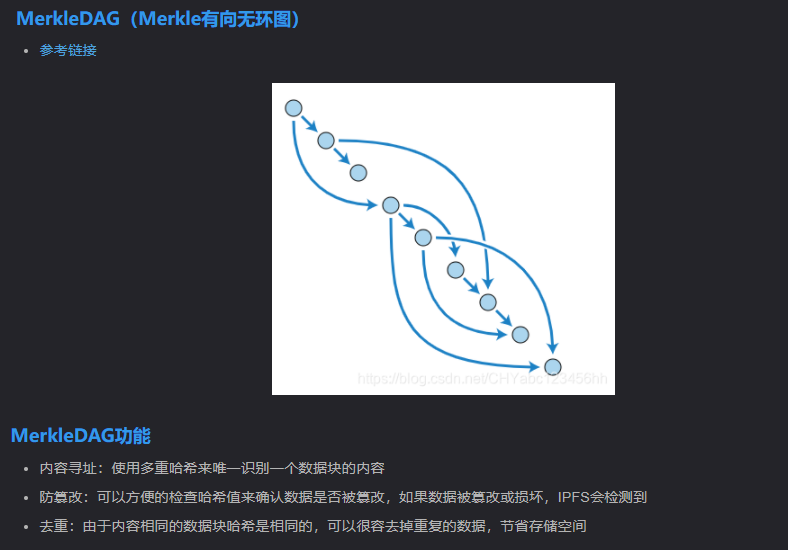
有向无环图(Directed Acyclic Graphs),简称为DAG.
|
|
|
用于SAT相关文献——查询 Directed Acyclic Graphs SAT 结果
|
|
|
MerkleDAG作为IPFS中的一种创新的数据结构,通过有向无环图的方式连接数据块,实现了高效的数据查找和验证。它具有数据的唯一性和完整性、高效的数据查找和良好的可扩展性等优势。在IPFS中,MerkleDAG被广泛应用于文件存储和传输、数据存储和传输等方面。尽管面临一些挑战,但MerkleDAG的发展前景广阔,有望推动分布式存储和数据交换的发展。
区块链研究中把DAG作为一种去中心化的压缩存储结构。相关资料网址: https://docs.ipfs.tech/ https://docs.ipfs.tech/concepts/merkle-dag/#further-resources
可以安装专门的APP: Install the IPFS Desktop App https://docs.ipfs.tech/install/ipfs-desktop/#windows IPFS桌面(打开新窗口)是IPFS的官方桌面客户端。它带有一个内置的IPFS节点,可以让你锁定文件,并给你一个共享文件的链接。这是开始将您的文件固定到IPFS的最简单的方法之一。
Measuring the IPFS networkhttps://docs.ipfs.tech/concepts/measuring/#kpis ProbeLab团队正在开发工具,以持续监控IPFS网络几个关键部分的性能。可以找到当前的工具集,以及详细的描述和链接。 |
|
|
merkle-dag专门知识:
Merkledag 关系和数据分开存储
在分布式存储系统中,Merkle DAG(Merkle-Dagorier)是一种数据结构,用于表示数据的分层图。在Merkle Dag中,节点被分为两类:数据节点和链接节点。数据节点包含数据块,而链接节点用于链接数据节点,创建一个DAG(有向无环图)。 在Merkle DAG中,关系和数据是分开存储的。每个数据节点包含数据本身及其Merkle哈希值,而链接节点仅包含链接信息和链接到的数据节点的Merkle哈希值。 以下是一个简单的Python示例,演示如何在Merkle DAG中存储和检索数据: 1 import hashlib 2 3 class MerkleNode: 4 def __init__(self, data): 5 self.data = data 6 self.hash = self.calc_hash(data) 7 self.links = [] 8 9 def calc_hash(self, data): 10 return hashlib.sha256(data.encode()).hexdigest() 11 12 def add_link(self, node): 13 self.links.append(node.hash) 14 15 def __repr__(self): 16 return f"MerkleNode(hash='{self.hash}', data='{self.data}', links={self.links})" 17 18 # 创建节点 19 node1 = MerkleNode("data1") 20 node2 = MerkleNode("data2") 21 node3 = MerkleNode("data3") 22 23 # 添加链接 24 node1.add_link(node2) 25 node1.add_link(node3) 26 27 # 打印节点信息 28 print(node1) 29 print(node2) 30 print(node3) 在这个例子中,每个 在实际的分布式存储系统中,这些节点可以被分布在不同的节点上,而每个节点只需要存储自己的数据和链接信息,不需要存储所有数据本身。这样的设计使得数据可以被高效地分布式存储和检索。
IPFS的数据结构——Merkle DAGhttps://www.jianshu.com/p/a1614566936f
|
|
|
DAG拓扑结构存储区块
在区块链技术中,DAG(有向无环图)是一种数据结构,通常用于比特币和以太坊的区块链中,以存储交易信息和区块引用。在这种结构中,每个块都可以指向一个或多个前驱块,但没有前驱可以指向它,因此形成了一个复杂的网络。 在Python中,可以使用字典来存储DAG拓扑结构,其中键是块的哈希值,值是一个列表,包含了所有直接前驱的哈希值。 以下是一个简单的示例,展示了如何在Python中创建和操作这样的DAG拓扑结构: 1 # 初始化一个空的DAG 2 dag = {} 3 4 # 添加块和它们的前驱 5 def add_block(block_hash, predecessors): 6 dag[block_hash] = predecessors 7 8 # 获取一个块的直接前驱 9 def get_predecessors(block_hash): 10 return dag.get(block_hash, []) 11 12 # 示例用法 13 add_block('block1', ['block0']) # block1有一个前驱block0 14 add_block('block2', ['block1', 'block3']) # block2有两个前驱block1和block3 15 add_block('block3', []) # block3没有前驱 16 17 # 打印出来看看 18 print(dag)
这个简单的代码段展示了如何初始化一个DAG,如何添加新的块和它们的前驱,以及如何检索给定块的前驱。在实际的区块链应用中,你可能还需要处理并发冲突、路径验证等问题,但这些都是在正确实现DAG数据结构的基础上进行的。
|
|
使用NetworkX绘制深度神经网络结构图(Python)https://blog.csdn.net/m0_38106923/article/details/88095710?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-88095710-blog-135422176.235^v43^pc_blog_bottom_relevance_base1&spm=1001.2101.3001.4242.1&utm_relevant_index=3 |
|
|
面向DAG任务的联合调度算法
在IT领域,特别是分布式计算和操作系统的设计中,调度算法扮演着至关重要的角色。本文将深入探讨标题和描述中提到的“federated scheduling”(联邦调度)以及它如何与并行性、DAG(有向无环图)任务、调度算法和操作系统相关联。 让我们了解“并行性”。并行性是指在同一时间处理多个任务或计算,以提高系统的效率和性能。在现代计算机系统中,这通常通过多核处理器、分布式计算集群或者GPU并行计算实现。并行性可以分为任务级并行性和数据级并行性。任务级并行性涉及将整个工作分解为独立的任务,而数据级并行性则涉及同时处理大量数据的不同部分。 DAG(有向无环图)是一种图形结构,用于表示任务之间的依赖关系。在DAG中,每个节点代表一个任务,边则指示任务的执行顺序。这种表示法非常适合于描述具有任务内并行性的任务,因为它们可以清晰地显示哪些任务可以并行运行,哪些必须在其他任务完成后才能开始。在分布式系统中,DAG被广泛应用于工作流管理和任务调度,以确保任务的正确执行顺序。 “面向DAG任务的联合调度算法”是解决这类任务调度问题的一种策略。联合调度,也称为全局调度,是一种在分布式环境中协调多个独立调度器的方法。在这种方法中,各个节点(或调度器)负责一部分任务,但它们协同工作以优化整体性能。联合调度的目标是有效地分配资源,减少任务等待时间和通信开销,同时确保任务的正确性和完成时间。 调度算法是实现这些目标的关键。针对DAG任务的调度算法需要考虑任务间的依赖关系、资源约束以及可能的并行性。一些常见的DAG调度算法包括:拓扑排序调度、优先级调度、基于延迟的调度和资源感知调度。 这些算法在决定任务的执行顺序时会综合考虑任务的依赖、资源需求、预期执行时间等因素。 在操作系统层面,调度器是内核的一部分,负责决定哪个进程或线程应该在何时获取CPU时间片。对于DAG任务,操作系统调度器需要扩展以理解任务间的依赖关系,并能够进行有效的资源分配和任务调度。例如,分布式操作系统可能包含特定的DAG调度组件,用于处理复杂的任务依赖和并行执行。 "federated scheduling"结合了并行性、DAG任务表示和调度算法,旨在优化分布式环境中的任务执行。 这种技术在大规模数据处理、科学计算、云计算服务等领域有着广泛的应用。通过智能地调度任务,可以最大化利用硬件资源,缩短总体计算时间,从而提高系统的效率和生产力。对这些概念的理解和应用是提升现代计算系统性能的关键。 |
|