


Distributed Constrained Combinatorial Optimization leveraging Hypergraph Neural Networks
|
Abstract Scalable addressing of high dimensional constrained combinatorial optimization problems is a challenge that arises in several science and engineering disciplines. Recent work introduced novel application of graph neural networks for solving quadratic-cost combinatorial optimization problems. 高维约束组合优化问题的可扩展求解是多个科学和工程学科中出现的挑战。最近的工作介绍了图神经网络在求解二次成本组合优化问题方面的新应用。 However, effective utilization of models such as graph neural networks to address general problems with higher order constraints is an unresolved challenge. 然而,有效利用图神经网络等模型来解决具有高阶约束的一般问题是一个尚未解决的挑战。
This paper presents a framework, HypOp, which advances the state of the art for solving combinatorial optimization problems in several aspects: (i) it generalizes the prior results to higher order constrained problems with arbitrary cost functions by leveraging hypergraph neural networks; (ii) enables scalability to larger problems by introducing a new distributed and parallel training architecture; (iii) demonstrates generalizability across different problem formulations by transferring knowledge within the same hypergraph; (iv) substantially boosts the solution accuracy compared with the prior art by suggesting a fine-tuning step using simulated annealing; (v) shows a remarkable progress on numerous benchmark examples, including hypergraph MaxCut, satisfiability, and resource allocation problems, with notable run time improvements using a combination of fine-tuning and distributed training techniques. 本文提出了一个框架HypOp,该框架在几个方面推进了解决组合优化问题的最新技术: (i)通过利用超图神经网络,将先前的结果推广到具有任意成本函数的高阶约束问题; (ii) 通过引入新的分布式和并行训练架构,实现对更大问题的可扩展性; (iii) 通过在同一超图中转移知识,证明不同问题表述的可推广性; (iv)与现有技术相比,通过建议使用模拟退火进行微调步骤,大大提高了解决方案的精度; (v) 在许多基准示例上取得了显着进展,包括超图 MaxCut、满足性和资源分配问题,使用微调和分布式训练技术的组合,运行时得到了显着改进。 We showcase the application of HypOp in scientific discovery by solving a hypergraph MaxCut problem on NDC drug-substance hypergraph. Through extensive experimentation on various optimization problems, HypOp demonstrates superiority over existing unsupervised learning-based solvers and generic optimization methods. 我们通过求解NDC药物-物质超图上的超图MaxCut问题,展示了HypOp在科学发现中的应用。通过对各种优化问题的广泛实验,HypOp 证明了优于现有的基于无监督学习的求解器和通用优化方法。 |
|
|
I. INTRODUCTION Combinatorial optimization is ubiquitous across science and industry. Scientists often need to make decisions about how to allocate resources, design experiments, schedule tasks, or select the most efficient pathways among numerous choices. Combinatorial optimization techniques can help in these situations by finding the optimal or near-optimal solutions, thus aiding in the decision-making process. 组合优化在科学和工业中无处不在。科学家经常需要决定如何分配资源、设计实验、安排任务或在众多选择中选择最有效的途径。在这些情况下,组合优化技术可以通过找到最优或接近最优的解决方案来帮助决策过程。
Furthermore, the integration of artificial intelligence (AI) into the field of scientific discovery is growing increasingly fluid, providing means to enhance and accelerate research [1]. An approach to integrate AI into scientific discovery involves leveraging machine learning (ML) methods to expedite and improve the combinatorial optimization techniques to solve extremely challenging optimization tasks. 此外,人工智能 (AI) 与科学发现领域的整合正变得越来越流畅,为增强和加速研究提供了手段 [1]。将人工智能集成到科学发现的一种方法涉及利用机器学习 (ML) 方法来加速和改进组合优化技术,以解决极具挑战性的优化任务。
Several combinatorial optimization problems are proved to be NP-hard, rendering most existing solvers non-scalable. Moreover, the continually expanding size of today’s datasets makes existing optimization methods inadequate for addressing constrained optimization problems on such vast scales. To facilitate the development of scalable and rapid optimization algorithms, various learning-based approaches have been proposed in the literature [2], [3]. 一些组合优化问题被证明是NP困难的,使得大多数现有的求解器不可扩展。此外,当今数据集规模的不断扩大使得现有的优化方法不足以解决如此大规模的约束优化问题。为了促进可扩展和快速优化算法的开发,文献[2],[3]中提出了各种基于学习的方法。
------------------------------ Learning-based optimization methods can be classified into three main categories: supervised learning, unsuper vised learning, and reinforcement learning (RL). Supervised learning methods [4], [5], [6], [7], [8] train a model to address the given problems using a dataset of solved problem instances. 基于学习的优化方法可以分为三大类:监督学习、非监督学习和强化学习(RL)。监督学习方法 [4]、[5]、[6]、[7]、[8] 使用已解决问题实例的数据集训练模型以解决给定的问题。
However, these approaches exhibit limitations in terms of generalizability to problem types not present in the training dataset and tend to perform poorly on larger problem sizes. Unsupervised learning approaches [2], [9], [10] do not rely on datasets of solved instances. Instead, they train ML models using optimization objectives as their loss functions. Unsupervised methods offer several advantages over supervised ones, including enhanced generalizability and eliminating the need for datasets containing solved problem instances, which can be challenging to acquire. 然而,这些方法在对训练数据集中不存在的问题类型的可推广性方面表现出局限性,并且在较大的问题规模上往往表现不佳。无监督学习方法[2]、[9]、[10]不依赖于已解决实例的数据集。取而代之的是,他们使用优化目标作为损失函数来训练 ML 模型。与监督方法相比,无监督方法具有多项优势,包括增强的可推广性,并消除了对包含已解决问题实例的数据集的需求,而这些数据集可能难以获取。
RL-based methods [11], [12],[13], [14] hold promise for specific optimization problems, provided that lengthy training and fine-tuning times can be accommodated. 基于RL的方法[11]、[12]、[13],[14]对特定的优化问题有希望,只要可以适应长时间的训练和微调时间。
---------------------------------------
Unsupervised learning based optimization methods can be conceptualized as a fusion of gradient descent-based optimization techniques with learnable transformation functions. In particular, in an unsupervised learning-based optimization algorithm, the optimization variables are computed through an ML model, and the objective function is optimized by applying gradient descent over the parameters of this model. In other words, instead of conducting gradient descent directly on the optimization variables, it is applied to the parameters of the ML model responsible for generating them. The goal is to establish more efficient optimization paths compared to conventional direct gradient descent. 基于无监督学习的优化方法可以概念化为基于梯度下降的优化技术与可学习的变换函数的融合。特别是,在基于无监督学习的优化算法中,通过ML模型计算优化变量,并通过对该模型的参数应用梯度下降来优化目标函数。换言之,它不是直接对优化变量进行梯度下降,而是应用于负责生成这些变量的 ML 模型的参数。目标是建立比传统的直接梯度下降更有效的优化路径。
This approach can potentially facilitate better escapes from subpar local optima. Various transformation functions are utilized in the optimization literature to render the optimization problems tractable. For example, there are numerous techniques to linearize or convexify an optimization problem by employing transformation functions that are often lossy [15]. We believe that adopting ML-based transformation functions for optimization offers a substantial capability to train customized transformation functions that best suit the specific optimization task. 这种方法可能有助于更好地摆脱低于标准的局部最优条件。优化文献中使用了各种变换函数,使优化问题易于处理。例如,有许多技术可以通过使用通常是有损的变换函数来线性化或凸化优化问题[15]。我们认为,采用基于ML的转换函数进行优化,可以很好地训练最适合特定优化任务的自定义转换函数。
-----------------------------------------
For combinatorial optimization problems over graphs, graph neural networks are frequently employed as the learnable transformation functions [2], [9], [10]. However, when dealing with complex systems with higher order interactions and constraints, graphs fall short of modeling such relations. When intricate relationships among multiple entities extend beyond basic pairwise connections, hypergraphs emerge as invaluable tools for representing a diverse array of scientific phenomena. They have been utilized in various areas including biology and bioinformatics [16], [17], social network analysis [18], chemical and material science [19], image and data processing [20]. Hypergraph neural networks (HyperGNN) [21] have also been commonly used for certain learning tasks such as image and visual object classification [21], and material removal rate prediction [19]. It is anticipated that HyperGNNs may serve as valuable tools for addressing combinatorial optimization problems with higher-order constraints. 对于图的组合优化问题,图神经网络经常被用作可学习的变换函数[2]、[9]、[10]。然而,在处理具有高阶交互和约束的复杂系统时,图无法对这种关系进行建模。当多个实体之间的复杂关系超出基本的成对连接时,超图就成为表示各种科学现象的宝贵工具。它们已被用于各个领域,包括生物学和生物信息学 [16]、[17]、社交网络分析 [18]、化学和材料科学 [19]、图像和数据处理 [20]。超图神经网络(HyperGNN)[21]也常用于某些学习任务,如图像和视觉对象分类[21],以及材料去除率预测[19]。预计 HyperGNN 可以作为解决具有高阶约束的组合优化问题的宝贵工具。
-------------------------------------------
While unsupervised learning approaches for solving combinatorial optimization problems offer numerous ad vantages, they may face challenges, including susceptibility to getting trapped in suboptimal local solutions and scalability issues. In a recent work [22], the authors argue that for certain well-known combinatorial optimization problems, unsupervised learning optimization methods may exhibit inferior performance compared to straightforward heuristics. However, it is crucial to recognize that these unsupervised methods possess a notable advantage in their generic applicability. Generic solvers like gradient-based techniques (such as SGD and ADAM), as well as simulated annealing (SA), may not be able to compete with customized heuristics that are meticulously crafted for specific problems. Nonetheless, they serve as invaluable tools for addressing less-known problems lacking effective heuristics. Consequently, the strategic utilization of unsupervised learning-based optimization methods can enhance and extend the capabilities of existing generic solvers, leading to the development of efficient tools for addressing a diverse range of optimization problems. 虽然用于解决组合优化问题的无监督学习方法提供了许多优势,但它们可能面临挑战,包括容易陷入次优局部解决方案和可伸缩性问题。在最近的一项工作[22]中,作者认为,对于某些众所周知的组合优化问题,与直接启发式相比,无监督学习优化方法可能表现出较差的性能。然而,重要的是要认识到这些无监督方法在其通用适用性方面具有显着优势。基于梯度的技术(如 SGD 和 ADAM)以及模拟退火 (SA) 等通用求解器可能无法与针对特定问题精心设计的定制启发式方法竞争。尽管如此,它们仍然是解决缺乏有效启发式的鲜为人知问题的宝贵工具。因此,战略性地利用基于无监督学习的优化方法可以增强和扩展现有通用求解器的能力,从而开发用于解决各种优化问题的高效工具。
----------------------------------------------
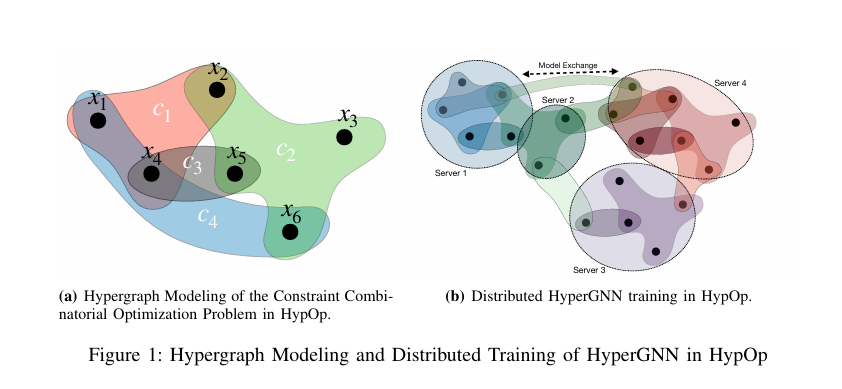
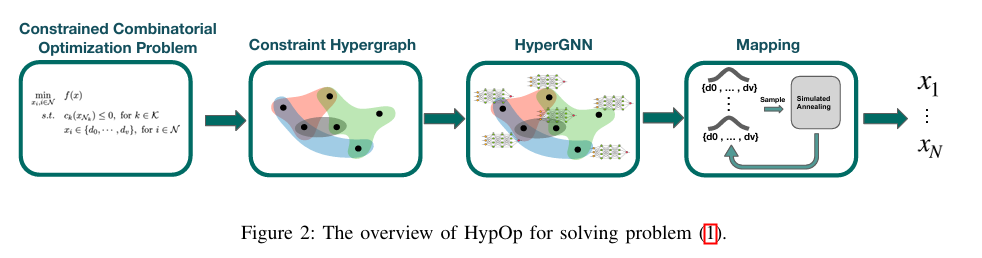
In this study, we build upon the unsupervised learning-based optimization method for quadratic-cost combinatorial optimization problems on graphs introduced in [2], and present HypOp, a new scalable solver for a wide range of constrained combinatorial optimization problems with arbitrary cost functions. Our approach is applicable to problems with higher-order constraints by adopting hypergraph modeling for such problems (Fig.1(a)); HypOp subsequently utilizes hypergraph neural networks in the training process, a generalization of the graph neural networks employed in [2]. HypOp further combines unsupervised HyperGNNs with another generic optimization method, simulated annealing [23] to boost its performance. Incorporating SA with HyperGNN can help with mitigation of the potential subpar local optima that may arise from HyperGNN training. 在这项研究中,我们基于无监督学习的优化方法,用于解决[2]中介绍的图上的二次成本组合优化问题,并提出了HypOp,一种新的可扩展求解器,用于解决具有任意成本函数的各种约束组合优化问题。我们的方法适用于具有高阶约束的问题,对此类问题采用超图建模(图1(a));HypOp随后在训练过程中利用超图神经网络,这是对[2]中采用的图神经网络的推广。HypOp进一步将无监督HyperGNN与另一种通用优化方法(模拟退火[23])相结合,以提高其性能。将 SA 与 HyperGNN 相结合有助于缓解 HyperGNN 训练可能产生的潜在低于标准的局部最优值。
To establish a scalable solver and expedite the optimization process, HypOp proposes two algorithms for parallel and distributed training of HyperGNN. First, it develops a distributed training algorithm in which, the hypergraph is distributed across a number of servers and each server only has a local view of the hypergraph. We develop a collaborative distributed algorithm to train the HyperGNN and solve the optimization problem (See Fig.1(b)). Second, HypOp proposes a parallel HyperGNN training approach where the costs associated to constraints are computed in a scalable manner. We further exhibit the transferability of our models, highlighting their efficacy in solving different optimization problems on the same hypergraph through transfer learning. 为了建立一个可扩展的求解器并加快优化过程,HypOp提出了两种算法,用于HyperGNN的并行和分布式训练。首先,它开发了一种分布式训练算法,其中超图分布在多个服务器上,每个服务器只有超图的本地视图。我们开发了一种协作分布式算法来训练HyperGNN并求解优化问题(见图1(b))。其次,HypOp 提出了一种并行的 HyperGNN 训练方法,其中以可扩展的方式计算与约束相关的成本。我们进一步展示了模型的可转移性,突出了它们通过迁移学习解决同一超图上不同优化问题的有效性。
This not only shows the generalizability of HypOp but also considerably accelerates the optimization process. HypOp is tested by comprehensive experiments, thoughtfully designed to provide insights into unsupervised learning-based optimization algorithms and their effectiveness across diverse problem types. We validate the scalability of HypOp by testing it on huge graphs, showcasing how parallel and distributed training can yield high-quality solutions even on such massive graphs. In summary, our contributions are as follows. 这不仅显示了HypOp的通用性,而且大大加快了优化过程。HypOp 通过全面的实验进行测试,经过深思熟虑的设计,旨在深入了解基于无监督学习的优化算法及其在各种问题类型中的有效性。我们通过在巨大的图形上测试HypOp来验证它的可扩展性,展示了并行和分布式训练如何在如此巨大的图形上产生高质量的解决方案。总而言之,我们的贡献如下。 • Presenting HypOp, a scalable unsupervised learning-based optimization method for addressing a wide spec trum of constrained combinatorial optimization problems with arbitrary cost functions. Notably, we pioneer the application of hypergraph neural networks within the realm of learning-based optimization for general combinatorial optimization problems with higher order constraints. • Enabling scalability to much larger problems by introducing a new distributed and parallel architecture for hypergraph neural network training. • Demonstrating generalizability to other problem formulations, by knowledge transfer from the learned experi ence of addressing one set of cost/constraints to another set for the same hypergraph. • Substantially boosting the solution accuracy and improving run time using a combination of fine-tuning (simulated annealing) and distributed training techniques. • Demonstrating superiority of HypOp over existing unsupervised learning-based solvers and generic optimization methods through extensive experimentation on a variety of combinatorial optimization problems. We address a novel set of scientific problems including hypergraph MaxCut problem, satisfiability problems (3SAT), and resource allocation. • Showcasing the application of HypOp in scientific discovery by solving a hypergraph MaxCut problem on the NDC drug-substance hypergraph • 介绍HypOp,一种可扩展的基于无监督学习的优化方法,用于解决具有任意成本函数的约束组合优化问题的广泛规格。值得注意的是,我们率先在基于学习的优化领域内应用超图神经网络,以解决具有高阶约束的一般组合优化问题。 • 通过引入新的分布式和并行架构进行超图神经网络训练,实现对更大问题的可扩展性。 • 通过将知识从解决一组成本/约束的学习经验转移到同一超图的另一组知识,证明对其他问题表述的可推广性。 • 通过微调(模拟退火)和分布式训练技术的组合,大幅提高求解精度并缩短运行时间。 • 通过对各种组合优化问题的广泛实验,证明 HypOp 优于现有的基于无监督学习的求解器和通用优化方法。我们解决了一系列新的科学问题,包括超图MaxCut问题、满足性问题(3SAT)和资源分配。• 通过求解NDC原料药超图上的超图MaxCut问题,展示HypOp在科学发现中的应用
A. Paper Structure The remainder of this paper is structured as follows. We provide the problem statement in Section II. The HypOp method is presented in Section III. We describe two algorithms for distributed and scalable training of HypOp in Section IV. Our experimental results are provided in Section V. We showcase the possibility of transfer learning in HypOp in Section VI. The applications of HypOp in scientific discovery is discussed in Section VII. We conclude by a discussion in Section VIII. Supplementary information including, related work, preliminaries, extra details on the experimental setup and results, and the limitations are provided in the Supplementary Information section. A. 论文结构 本文的其余部分结构如下。我们在第二节中提供了问题陈述。HypOp 方法在第 III 节中介绍。我们在第四节中描述了两种用于HypOp分布式和可扩展训练的算法。我们的实验结果在第五节中提供。我们将在第六节中展示HypOp中迁移学习的可能性。HypOp在科学发现中的应用将在第七节中讨论。最后,我们将在第八节进行讨论。补充信息,包括相关工作、初步信息、有关实验设置和结果的额外详细信息以及限制,在补充信息部分提供。 |
|
|
II. PROBLEM STATEMENT
Solving the above optimization problem can be challenging, potentially falling into the category of NP-hard problems. This complexity arises from the presence of discrete optimization variables, as well as the potentially non-convex and non-linear objective and constraint functions. Consequently, efficiently solving this problem is a complex task. Additionally, the discreteness of optimization variables implies that the objective function is not continuous, making gradient descent-based approaches impractical. To address this, a common strategy involves relaxing the state space into continuous spaces, solving the continuous problem, and then mapping the optimized continuous values back to discrete ones. While this approach may not guarantee globally optimal solutions due to the relaxation and potential convergence to suboptimal local optima, it remains a prevalent practice due to the availability and efficiency of the gradient descent-based solvers. Such solvers, such as ADAM [24], are widely developed and used as the main optimization method for ML tasks. The relaxed version of the optimization problem (1) is given below. 解决上述优化问题可能具有挑战性,可能属于NP难题的范畴。这种复杂性源于离散优化变量的存在,以及潜在的非凸和非线性目标和约束函数。因此,有效地解决这个问题是一项复杂的任务。此外,优化变量的离散性意味着目标函数不是连续的,这使得基于梯度下降的方法不切实际。为了解决这个问题,一种常见的策略是将状态空间放宽为连续空间,求解连续问题,然后将优化的连续值映射回离散的连续值。虽然由于松弛和潜在收敛到次优局部最优,这种方法可能无法保证全局最优解,但由于基于梯度下降的求解器的可用性和效率,它仍然是一种普遍的做法。ADAM [24]等此类求解器被广泛开发并用作ML任务的主要优化方法。优化问题(1)的宽松版本如下。
|
|
|
References
|
|
|
Code availabilityThe code has been made publicly available at ref. 32. We used Python v.3.8 together with the following packages: torch v.2.1.1, tqdm v.4.66.1, h5py v.3.10.0, matplotlib v.3.8.2, networkx v.3.2.1, numpy v.1.21.6, pandas v.2.0.3, scipy v.1.11.4 and sklearn v.0.0. We used PyCharm v.2023.1.2 and Visual Studio Code v.1.83.1 software. |
|

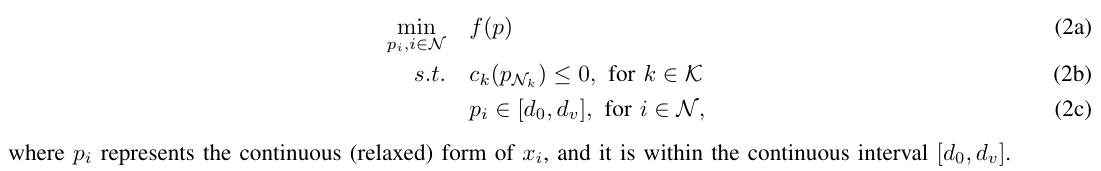
上面文章的参考文献2:
Combinatorial Optimization with Physics-Inspired Graph Neural NetworksMartin
|
Despite remarkable advancesin both algorithms and computing power, significant yetgeneric improvements have remained elusive, generatingan increased interest in new optimization approachesthat are broadly applicable and radically different fromtraditional operations research tools. 尽管在算法和计算能力方面都取得了显着进步,但重大的通用改进仍然难以捉摸,这引起了人们对新优化方法的兴趣,这些方法具有广泛的适用性,与传统的运筹学工具截然不同。 |
|
| quantum annealing 量子退火 | |
|
本文的主要技术路线:
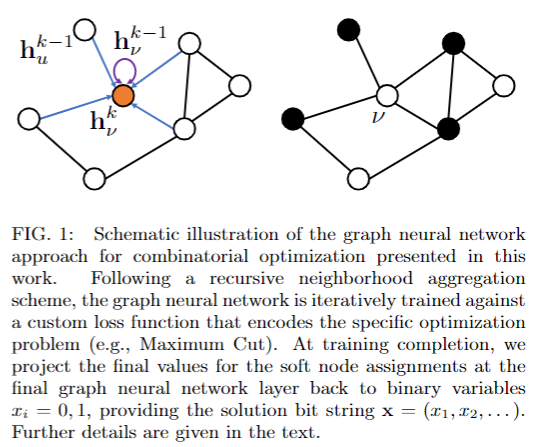
遵循递归邻域聚合方案,图神经网络针对编码特定优化问题的自定义损失函数(例如,最大切割)进行迭代训练。 训练完成后,我们将最终图神经网络层的软节点赋值的最终值投影回二进制变量 xi= 0,1,提供解位字符串 x= (x1,x2,...)。文中提供了更多细节。 ------------------------------------------------------------------------ 图神经网络的构建:1-4步 In this work we present a highly-scalable GNN-based solver to (approximately) solve combinatorialoptimization problems with up to millions of variables.The approach is schematically depicted in Fig. 1, andworks as follows:
1. 首先,我们确定根据二元决策变量xν∈ {0,1 }对优化问题进行编码的哈密尔顿函数(成本函数)h,并且我们将该变量与顶点ν∈V关联起来,对于无向图G= (V,E),顶点集V={1,2,...,n }和边集={(i,j) :i,j∈V }捕获决策变量之间的交互。
2. We then apply a relaxation strategy to the problemHamiltonian to generate a differentiable loss functionwith which we perform unsupervised training on thenode representations of the GNN。 然后,我们将松弛策略应用于问题哈密顿量,以生成一个可微损失函数,通过该函数,我们对 GNN 的节点表示进行无监督训练。
3. GNN遵循标准递归邻域聚合方案[42,43],其中每个节点ν= 1,2,...,n收集其邻居的信息(编码为特征向量)以在layerk=0,1,...,k。
4. 在k轮操作之后,节点通过其变换的特征向量hkν来表示,该向量捕获节点的sk-hop邻域内的结构信息[27]。 对于二进制分类任务,我们通常使用卷积聚合步骤,然后应用非线性softmax激活函数,将最终嵌入的hKν缩减为一维软(概率)节点分配。最后,一旦非监督训练过程完成,我们应用投影启发式算法将这些软分配映射回整数变量xν∈ {0,1 },例如使用xν=int(pν)。
5. 我们用数值展示了我们的方法,以及典型NP硬优化问题的结果,如最大切割(MaxCut)和最大独立集(MIS),表明我们基于GNN的方法可以与现有的成熟求解器相当甚至更好,同时广泛适用于一大类优化问题。 此外,我们方法的可扩展性开辟了在机器集群上以小批量方式利用分布式训练时研究具有数亿个节点的前所未有的问题规模的可能性,正如最近在参考文献[44]中所证明的那样。
|
|
|
图神经网络的应用介绍: In essence, GNNs are deepneural network architectures specifically designed forgraph structure data, with the ability to learn effective feature representations of nodes, edges, or even entiregraphs. Prime examples of GNN applications includeclassification of users in social networks [30, 31], theprediction of future interactions in recommender systems[32], and the prediction of certain properties of moleculargraphs [33, 34]. 从本质上讲,GNN 是专门为图结构数据设计的深度神经网络架构,能够学习节点、边甚至整体图的有效特征表示。GNN应用的主要例子包括社交网络中的用户分类[30,31],推荐系统中未来交互的预测[32],以及分子图的某些特性的预测[33,34]。
As a convenient and general frameworkto model a variety of real-world complex structuraldata, GNNs have successfully been applied to a broadset of problems, including recommender systems insocial media and e-commerce [35, 36], the detectionof misinformation (fake news) in social media [37],and various domains of natural sciences including eventclassification in particle physics [38, 39], to name a few.While several specific implementations of GNNs exist [28,40, 41], at their core typically GNNs iteratively updatethe features of the nodes of a graph by aggregating theinformation from their neighbors (often referred to asmessage passing[42]) thereby iteratively making localupdates to the graph structure as the training of thenetwork progresses. Because of their scalability andinherent graph-based design, GNNs present an alternateplatform to build large-scale combinatorial heuristics. GNNs是一个方便和通用的框架,可以对各种现实世界的复杂结构数据进行建模,GNNs已经成功地应用于广泛的问题,包括社交媒体和电子商务中的推荐系统[35,36],社交媒体中的错误信息(假新闻)的检测[37],以及自然科学的各个领域,包括粒子物理学中的事件分类[38,39],仅举几例。虽然GNN有几种具体的实现[28,40,41],但其核心通常是GNN通过聚合来自其邻居的信息来迭代更新图节点的特征(通常称为消息传递[42]),从而随着网络训练的进展迭代地对图结构进行局部更新。由于其可伸缩性和固有的基于图的设计,GNN 提供了一个替代平台来构建大规模组合启发式方法。
|
|
|
图神经网络如何表示学习信息 在高层次上,gnn是一个神经网络家族,能够学习如何聚集图形中的信息以用于表示学习。 一个典型GNN层有三项功能组成: I)消息传递功能,允许边上节点之间的信息交换; (ii)聚合功能,将接收到的消息集合组合成单个固定长度的表示; (iii )(通常是非线性的)更新激活函数,其在给定前一层表示和聚集信息的情况下产生节点级表示。 虽然单层GNN通过堆叠多层来封装基于其直接或一跳邻域的节点特征,但是该模型可以通过中间节点来传播每个节点的特征,这类似于在卷积神经网络的下游层中拓宽感受域。 形式上,atlayerk= 0,每个节点ν∈由某个初始表示h0ν∈Rd0表示,通常从节点的标签或给定的维数为d0的输入特征导出[67]。 在递归邻域聚合方案之后,GNN迭代地更新每个节点的表示,通常由一些参数函数fkθ来描述,可以表示为:公式(3)
总层数通常作为一个超参数由经验确定,中间表示维数dk也是如此。
两者都可以在外部循环中优化。虽然越来越多的GNN架构的可能实现[29]存在,这里我们使用一个图卷积网络(GCN) [28],其中方程。(3)明确读作公式(4).
wk and kbk是(共享的)可训练权重矩阵,分母| N(ν)|用作归一化因子(也可以有其他选择),σ()是某种(按分量)非线性激活函数,如sigmoid或ReLU。
虽然神经网络可以用于各种预测任务(包括节点分类、链接预测、社区检测、网络相似性或图形分类),但这里我们关注节点分类,其中通常最后(第K)层的输出用于预测每个节点ν∈ V的标签ν。为此,我们将(参数化的)最终节点嵌入zν=hKν(θ)输入到特定问题的损失函数中,并运行随机梯度下降来训练权重参数 |
|
|
第三章 介绍了运用GNN解决优化问题的一个实例方法——solve combinatorialoptimization problems
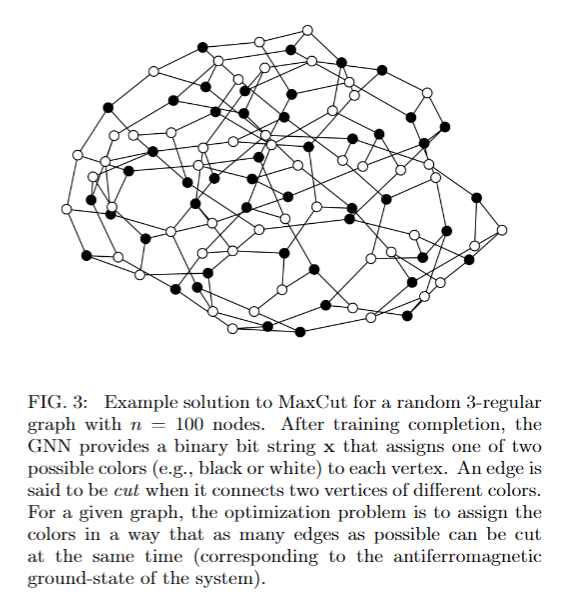
For illustration, an example solution to thearchetypal MaxCut problem (as implemented with thisAnsatz) for a3-regular graph withn= 100verticesis shown in Fig. 3. Here, the cut size achieved withour GNN method amounts to132. Further details areprovided below |
|
|
GNN研究平台和软件 Our GNN-based approach can be readily implementedwith open-source libraries such as PyTorch Geometric [68] or the Deep Graph Library [69]. The core of thecorresponding code is displayed in Listing 1 for a GCNwith two layers and a loss function for any QUBOproblem. 我们基于GNN的方法可以很容易地通过开源库实现,如PyTorch Geometric [68]或Deep Graph Library [69]。相应代码的核心显示在清单 1 中,该 GCN 具有两层,并且对于任何 QUBO问题都有一个损失函数。
|
|



3. 其它相关文献
|
Corso, G., Stark, H., Jegelka, S. et al. Graph neural networks. Nat Rev Methods Primers 4, 17 (2024). https://doi.org/10.1038/s43586-024-00294-7 图形神经网络(GNNs)是可以通过图形学习函数的数学模型,是在图形结构数据上构建预测模型的主要方法。这种结合使GNNs能够在许多学科中推进最先进的技术,从发现新的抗生素和确定药物用途候选人到模拟物理系统和产生新的分子。这本初级读本提供了一个实用的和可访问的GNNs介绍,描述了它们的属性和生命和物理科学的应用。重点放在关键理论限制的实际影响,解决这些挑战的新想法和在新任务中使用GNNs时的重要考虑。 |
|
|
|
|

