
A Problem Meta-Data Library for Research in SAT
•Published: March 15, 2019
Abstract
Experimental data and benchmarks play a crucial role in developing new algorithms and implementations of SAT solvers. Besides comparing and evaluating solvers, they provide the basis for all kinds of experiments, for setting up hypothesis and for testing them. Currently – even though some initiatives for setting up benchmark databases have been undertaken, and the SAT Competitions provide a “standardized” collection of instances – it is hard to assemble benchmark sets with prescribed properties. Moreover, the origin of SAT instances is often not clear, and benchmark collections might contain duplicates. In this paper we suggest an approach to store meta-data information about SAT instances, and present an implementation that is capable of collecting, assessing and distributing benchmark meta-data.
Keyphrases: experiments, meta-data library, problem fingerprinting
In: Daniel Le Berre and Matti Järvisalo (editors). Proceedings of Pragmatics of SAT 2015 and 2018, vol 59, pages 144--152
| Links: | https://easychair.org/publications/paper/jQXv |
| https://doi.org/10.29007/gdbb |
|
Abstract: Experimental data and benchmarks play a crucial role in developing new algorithms and implementations of SAT solvers. Besides comparing and evaluating solvers, they provide the basis for all kinds of experiments, for setting up hypothesis and for testing them. Currently – even though some initiatives for setting up benchmark databases have been undertaken, and the SAT Competitions provide a “standardized” collection of instances – it is hard to assemble benchmark sets with prescribed properties. Moreover, the origin of SAT instances is often not clear, and benchmark collections might contain duplicates. In this paper we suggest an approach to store meta-data information about SAT instances, and present an implementation that is capable of collecting, assessing and distributing benchmark meta-data. 译文:在本文中,我们提出了一种存储SAT实例元数据信息的方法,并提出了一种能够收集、评估和分发基准元数据的实现。 |
|
| 1 Introduction | |
|
The experiment is the core sources of knowledge in science. It is the vital source of data in a feedback loop between hypothesis formation and theory falsification. Algorithm engineers use experiments to evaluate their methods. Runtime experiments are often based on publicly available sets of benchmark problems. A set of characteristics or meta-data can be associated with each benchmark problem. 译文:可以将一组特征或元数据与每个基准测试问题相关联。
Benchmark meta-data can be used for benchmark classification and for differentiated analysis of algorithmic methods. It is very common that a certain algorithmic method or heuristic configuration works well on a specific type of problems but not so on others. Such correlations between the feature space of our benchmarks and the configuration space (or even fundamental algorithms) are of great interest. Disclosure and analysis of such correlations can lead to better hypotheses and thus more solid theories. 译文:基准元数据可用于基准分类和算法方法的差异化分析。 译文:很常见的是,某种算法方法或启发式配置在特定类型的问题上工作得很好,但在其他类型的问题上则不然。 译文:我们的基准测试的特征空间和配置空间(甚至是基本算法)之间的这种相关性是非常有趣的。揭示和分析这种相关性可以产生更好的假设,从而产生更可靠的理论。
Recent approaches in SAT solver development show that automatic feature extraction and algorithm selection or heuristic configuration through machine learning are crucial to state-ofthe-art solver performance [4, 3]. Increasing the number of automatically extracted problem features can improve predictions made by machine learning. But problem meta-data is not only useful for the training of machine models, it can also help improve the interpretation of experimental results. And if problem meta-data is used like this, there is no restriction to data that can be automatically and efficiently extracted from the problem.
译文:最近的SAT求解器开发方法表明,通过机器学习进行自动特征提取和算法选择或启发式配置对于最先进的求解器性能至关重要[4,3]。 译文:增加自动提取问题特征的数量可以改进机器学习的预测。但是问题元数据不仅对机器模型的训练有用,它还可以帮助改进对实验结果的解释。
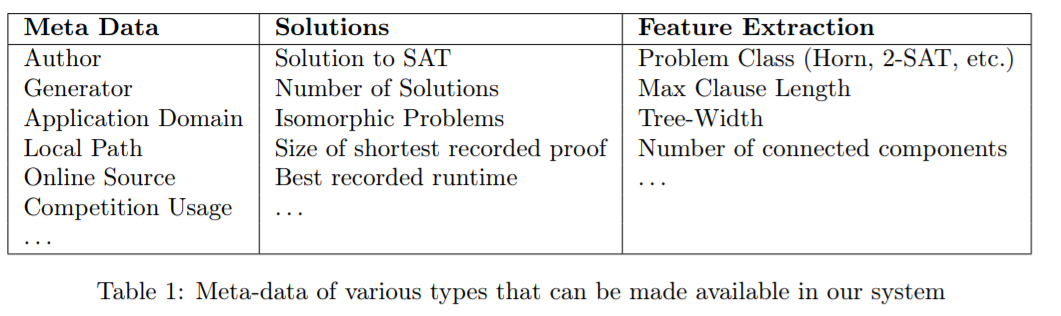
表1:系统中可用的各种类型的元数据 Attempts to provide organized sets of benchmarks have been realized e.g. by Hoos et al. with SATLib [6, 5]. The organizers of the bi-anual SAT Competition [2] assemble sets of benchmarks that are sufficiently hard but not too hard for state-of-the-art solvers. Unfortunately, problem meta-data is very diverse and is, like the problems themselves, distributed over multiple sources, and usually it has to be manually gathered by the experimenter. Given a set of anonymous SAT problems (e.g. from SAT competition), some information is hard to get (e.g. problem origin), and some types of data are computationally hard to calculate (e.g. solution, number of solutions). 译文:已经实现了提供有组织的基准集的尝试,例如Hoos等人使用SATLib[6,5]。两年一次的SAT竞赛的组织者[2]汇集了一系列的基准,这些基准对于最先进的解算者来说足够难,但又不会太难。不幸的是,问题元数据非常多样化,就像问题本身一样,分布在多个来源上,通常必须由实验人员手动收集。
The main goal of the presented tool is to easily gather and exchange meta-information about benchmark problems. Databases of benchmark meta-data should be easily maintainable and be distributed to researchers around the world. Meta information shall be collected from different sources and users should be able to easily add their knowledge to the pool.
The paper is structured as follows. In section 2 we will present some use-cases for the presented tool. In section 3 we will explain the structure of the database and the reasons for the choice or benefits of the chosen structure. Section 4 will provide insights into the implementation and usage of our tool. In section 5 we present some early experience with our tool and possibilities for future extensions. 译文: 在第2节中,我们将介绍所介绍的工具的一些用例。 在第3节中,我们将解释数据库的结构以及选择这种结构的原因或优点。 第4节将深入介绍我们的工具的实现和使用。 在第5节中,我们介绍了使用该工具的一些早期经验和将来扩展的可能性。 |
|
| 2 Use Cases | |
|
In order to create exchangeable collections of meta-data in a decentralized manner, the benchmark to data association has to be established via benchmark fingerprinting, i.e. well defined hash values of benchmark problems. As meta-data is associated with hash values of benchmark problems, it is easy to exchange meta-data with colleagues (see section 2.1). 译文:为了以分散的方式创建可交换的元数据集合,必须通过基准指纹来建立基准到数据的关联,即基准问题的定义良好的哈希值。由于元数据与基准问题的哈希值相关联,因此很容易与同事交换元数据(参见2.1节)。
Our system can be used to find duplicate problems (2.2) in competition sets or own collections of problems. It can be used to find correlations (2.3) that are particularly suitable for algorithm selection and interpretation of results. 译文:我们的系统可以用来在竞争集或自己的问题集合中找到重复的问题(2.2)。它可以用来寻找特别适合于算法选择和结果解释的相关性(2.3)。
The database can contain collections of metrics (e.g. “tree-width” or “number of connected components”). Also information about the source of the problem might be helpful, e.g. urls of a benchmark repository, problem author and application name. 译文:数据库可以包含度量的集合(例如“树宽度”或“连接组件的数量”)。此外,有关问题来源的信息可能会有所帮助,例如基准库的url、问题作者和应用程序名称。
Even algorithmic results that are hard to calculate, such as the solution to the SAT problem, the solution to the #SAT problem (i.e. number of solutions) or the solution to an isomorphism check can be exposed. It might also contain the shortest known proof for an unsatisfiable problem or just its size. Reporting and comparison of runtime results can easily be accomplished with our tool. Table 1 summarizes several types of data that can be made available in our system. 译文:即使是难以计算的算法结果,如SAT问题的解、#SAT问题的解(即解的数量)或同构检查的解也可以公开。它也可能包含一个不可满足问题的已知最短证明,或者只是它的大小。使用我们的工具可以轻松地完成运行时结果的报告和比较。表1总结了系统中可用的几种类型的数据。
|
|
|
2.1 Global repository for SAT meta-data Collections of SAT benchmarks can take up a large amount of storage. Also filenames can be ambiguous and the same problem might occur with different names in several collections of benchmark problems. Thus, a meta-data database should only reference benchmark problems via their fingerprints in the form of hash values and not the benchmark problem itself.
This is beneficial as researchers around the world can easily exchange benchmark attributes without the need to care about benchmark identification. The system solves the identification problems automatically via hash values.
2.2 Finding Duplicates Benchmark collections tend to contain duplicate benchmarks. For example the benchmark collections that are regularly compiled for the annual SAT Competition often contain benchmarks that are used in previous collections. We even found that some benchmarks are present with different filenames in the same benchmark collection multiple times.
Our system detects simple duplicates (those with an empty diff) directly, as they carry equal fingerprints or hash-values. However there are also duplicates, like isomorphic problems through variable renaming and clause reordering, which are not that easy to detect. Checks for isomorphism in benchmark problems impose hard algorithmic problems. It is beneficial to store and exchange this information. Our system assigns ids of equivalence classes to each benchmark. Once an isomorphism has been detected by one researcher, this information can be exposed via our systems equivalence-class table.
2.3 Finding Correlations Most new algorithms or heuristic configurations under test are unsuccessful in improving general solver performance. They might be beneficial for a specific subset of the benchmarks but catastrophic on another. Many such outcomes are considered being inconclusive.
Given a huge collection of meta-data, correlations of solver behavior and attributes that the experimenter might not even have thought of might be revealed. Experimental results that would otherwise be classified as being inconclusive might expose new coherences and lead to conclusions and even new theoretic models. 译文:考虑到大量的元数据,解决者的行为和属性之间的相关性可能会被揭示出来,而实验者甚至可能没有想到这一点。否则被归类为不确定的实验结果可能会揭示新的一致性,并导致结论甚至新的理论模型。 |
|
|
3 Database Layout The database should be small enough to be distributed quickly. Furthermore the data model should be extensible, without changes to the meta model, i.e. it should be possible to add new types of meta data without changing the software. The tool should be able to access different sources of data; for example a local database (e.g., for own experiments) and a global database (for the SAT community). Researchers can share their individual database with a collection of certain metrics in the web. 该工具应该能够访问不同的数据源;例如,一个本地数据库(例如,用于自己的实验)和一个全球数据库(用于SAT社区)。研究人员可以在网络上与特定指标的集合共享他们的个人数据库。
3.1 Hashing Benchmarks In order to keep the database small, the benchmarks themselves should not be part of the database. The same benchmark problem can come with different filenames. Anyway the identification of a specific problem must be possible. Therefore we use hash values to identify a benchmark. 译文:为了保持数据库较小,基准测试本身不应该是数据库的一部分。相同的基准测试问题可能伴随着不同的文件名。无论如何,特定问题的识别必须是可能的。因此,我们使用散列值来识别基准。
Our system creates an md5-hash for the unpacked and normalized benchmark. Unpacking ensures that the hash value is invariant to benchmark compression. Normalization includes removal of comment-lines and leading or duplicate whitespace characters. Also the line-separator characters are normalized and replaced by unix-style line-separators. The hash value is created such, that a call to md5sum on an already unpacked and normalized DIMACS-file would create the same hash-value. 译文:我们的系统为解压缩和规范化的基准创建一个md5哈希值。解包确保哈希值对于基准压缩是不变的。规范化包括删除注释行和前导或重复的空白字符。此外,行分隔符也被标准化并替换为unix风格的行分隔符。哈希值的创建是这样的,在已经解压缩和规范化的dimac文件上调用md5sum将创建相同的哈希值。
During an initial local bootstrapping process, a local benchmark table is created that maps the hash values to local paths where the actual problems reside. The system treats the such recorded local path like a specific type of meta information that is attached to each hash-value. However, the benchmark table has a special meaning, as it is used to resolve problem hashes against actual paths in the local filesystem.
3.2 Attribute Groups Problem attributes are organized in groups. For each attribute group, our system uses a two column table to store hash and value pairs. By default, attribute groups store strings such that queries run a substring search on the attribute group. Numeric types are supported as well, in which case queries can also use “less than” or “greater than” constraints.
Furthermore, attributes of a certain group can be constrained to be unique (i.e. attach at most one value to each problem) or have a default value (e.g. SAT, UNSAT and the default value UNKNOWN). If an attribute group is configured to have a default value and to be unique, our system ensures that there is always exactly one value stored for each locally available benchmark problem. |
|
|
4 Technology and Implementation We developed the system GBD (Global Benchmark Database) which is maintained in a publicly available GIT repository [1]. The database is stored in a SQLite file and is created and maintained by a set of Python scripts. The GBD Command-line Interface is organized into six basic commands: init, reflect, group, tag, query and resolve. Figure 1 shows the help page of GBD. Each individual command has its own help page that can be studied for further reference. In the following we give an overview on the usage and parameters of the most important commands.
The init command (section 4.1) provides access to bootstrapping and other initialization functionality, whereas the reflect command (section 4.4) provides reflection related functionality, such as gathering information about existing groups and their properties.
The group command (section 4.3) provides access to group creation and modification functionality. The tag command (section 4.5) can be used to associate attributes with benchmarks. With the query command (section 4.6) attributes and groups can be used to search for sets of hashes and to combine them using set operations. Using the resolve command (section 4.7) a query resultset of benchmark hashes can be translated to benchmark paths in the filesystem.
Note that, in order to simplify usability, most commands use the parameters -n to specify a group name and -v to specify an attribute value. In general hash values of benchmarks are printed line-wise to stdout and read line-wise from stdin, i.e. usage of pipe functionality is encouraged. 4.1 Initialization 4.2 Database Selection 4.3 Creation of Groups 4.4 Reflection on Groups 4.5 Association of Attributes with Benchmarks
4.6 Query
The query command provides methods to find benchmarks that match the specified attributes. A set of hash values is printed line-wise. Table 4 summarizes the parameters of the query command. Several queries can be combined via pipe operations. The parameter -o is used to specify how the hashes of the current query shall be combined with previous queries.
4.6.1 Example: The following query will return all hashes that contain the string 2017 in their path: gdb query -n benchmarks -v 2017
4.6.2 Example: The following sequence of commands will create the intersection of two queries. The first query returns all problems that carry the attribute “2017” in the group “competition”. The second query returns all problems with the attribute “sat” in the group “solution”: gdb query -n competition -v 2017 | gdb query -o intersection -n solution -v sat
4.7 Resolve As the query command only returns hashes of problems, in order to obtain the paths to the problems, the resolve command is used to resolve these hashes against the paths in the local benchmark table. The local benchmark table was created by the bootstrapping procedure as described in section 4.1.
As many problems occur in multiple publicly available compilations, it is not uncommon that resolve finds multiple representatives of one hash-value on the disk. Therefore the resolve command can be used with additional parameters. The parameter -c (collapse) is used to print only one representative per hash, that is usually the first in the list. Similarly, the -p [str] command constrains the returned path to contain the given substring. Both parameters can be used in combination in order to prefer resolution against a specific problem compilation.
4.7.1 Example: The query returns all problems that carry the attribute “2017” in the group “competition”. Then it is resolved against the local benchmark table. So the command returns a set of paths to problems that are locally available and fit the given query. gdb query -n competition -v 2017 | gbd resolve
4.7.2 Example: Like in the previous example, the query returns all problems that carry the attribute “2017” in the group “competition”. Then it is resolved against the local benchmark table. The resolve command has additional constraints to return only one path per hash, and to return only paths that contain the substring “folder1”. So the command returns a set of paths to unique problems that are locally available (e.g. in “folder1”) and fit the given query. gdb query -n competition -v 2017 | gbd resolve -c -p folder1 |
|
| 5 First Results and Future Work | |
|
Initializing the database with benchmarks from the agile set of SAT Competition 2017 showed that more than half of them are duplicates of one another. This could easily be detected, as only less than 50% unique hashes have been generated and the resolve command often returned multiple candidates for the same hash within the agile set of benchmark problems. There is no problem with the hash function, a quick check with the diff command showed that in fact the problems are identical. 译文:使用2017年敏捷SAT竞赛的基准初始化数据库显示,其中一半以上是彼此重复的。这可以很容易地检测到,因为只生成了不到50%的唯一哈希值,并且resolve命令经常在敏捷基准问题集中返回相同哈希值的多个候选值。 译文:哈希函数没有问题,使用diff命令快速检查后发现,实际上问题是相同的
In addition to present database selection, which requires physical exchange of files, new methods to setup a REST web-service for database-exposure are currently under development. Setup of a directory service where sources of benchmarks together with their meta-information can be publicly collected might be a future step of our work, or even a community effort. 译文:除了目前需要物理交换文件的数据库选择之外,目前正在开发为数据库公开设置REST web服务的新方法。 译文:建立一个目录服务,可以公开收集基准源代码及其元信息,这可能是我们未来的工作步骤,甚至是社区的努力。
Functions to import and merge tables from another database are currently under development. Future work includes functionality to automatically extract meta-information from benchmark files. This could include meta-data from specially formatted comments, but also the automatic execution of specialized algorithms. 译文:未来的工作包括从基准文件中自动提取元信息的功能。这可能包括来自特殊格式注释的元数据,也可能包括专门算法的自动执行。 Currently, only the most basic ideas of decentralized meta-data collection are implemented. The implementation of specific use-cases on top of basic meta-data collection and distribution is considered future work. Such use-cases include automatic detection of correlations between solver performance and other meta-data and automatic solver comparison. 译文:目前,只实现了分散元数据收集的最基本思想。在基本元数据收集和分发的基础上实现特定的用例被认为是未来的工作。 译文:这些用例包括自动检测求解器性能与其他元数据之间的相关性,以及自动求解器比较。 |
|
|
参考文献: References [1] GBD public repository. https://github.com/Udopia/gbd. Accessed: 2019-01-15. [2] SAT competitions. http://satcompetition.org/. Accessed: 2017-04-17. [3] Tomás Balyo, Armin Biere, Markus Iser, and Carsten Sinz. SAT Race 2015. Artif. Intell., 241:45–65, 2016. [4] Bernd Bischl, Pascal Kerschke, Lars Kotthoff, Marius Thomas Lindauer, Yuri Malitsky, Alexandre Fréchette, Holger H. Hoos, Frank Hutter, Kevin Leyton-Brown, Kevin Tierney, and Joaquin Vanschoren. Aslib: A benchmark library for algorithm selection. Artif. Intell., 237:41–58, 2016. [5] Holger Hoos and Thomas Stützle. Satlib. http://www.cs.ubc.ca/~hoos/SATLIB/index-ubc.html. Accessed: 2017-04-17. [6] Holger Hoos and Thomas Stützle. SATLIB: An online resource for research on SAT. 2000. |
|


 浙公网安备 33010602011771号
浙公网安备 33010602011771号