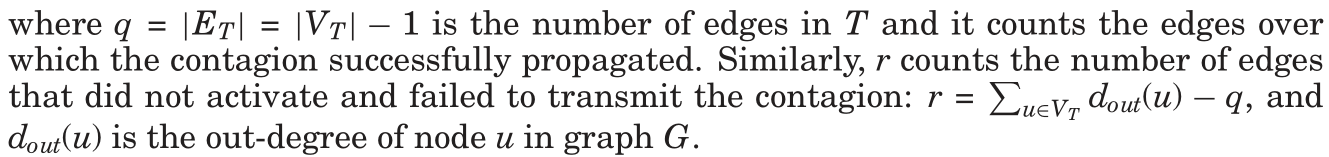- Authors:
-
 Manuel Gomez-Rodriguez,
Manuel Gomez-Rodriguez, -
 Jure Leskovec,
Jure Leskovec, -
Andreas Krause
-
Abstract |
|
|
Information diffusion and virus propagation are fundamental processes taking place in networks. While it is often possible to directly observe when nodes become infected with a virus or publish the information, observing individual transmissions (who infects whom, or who influences whom) is typically very difficult. 译文:信息扩散和病毒传播是发生在网络中的基本过程。虽然通常有可能直接观察节点何时感染病毒或发布信息,但观察个别传播(谁感染了谁,或谁影响了谁)通常非常困难。 Furthermore, in many applications, the underlying network over which the diffusions and propagations spread is actually unobserved. We tackle these challenges by developing a method for tracing paths of diffusion and influence through networks and inferring the networks over which contagions propagate. 译文:此外,在许多应用中,扩散和传播所经过的底层网络实际上是无法观察到的。我们通过开发一种方法来追踪通过网络传播和影响的路径,并推断传染传播的网络来应对这些挑战。 Given the times when nodes adopt pieces of information or become infected, we identify the optimal network that best explains the observed infection times. Since the optimization problem is NP-hard to solve exactly, we develop an efficient approximation algorithm that scales to large datasets and finds provably near-optimal networks. 译文:给定节点接收信息片段或被感染的时间,我们确定最优网络,最能解释观察到的感染时间。由于优化问题是np难以精确解决的,我们开发了一种有效的近似算法,可扩展到大型数据集并找到可证明的近最优网络。 We demonstrate the effectiveness of our approach by tracing information diffusion in a set of 170 million blogs and news articles over a one year period to infer how information flows through the online media space. 译文:我们通过追踪一年中1.7亿篇博客和新闻文章中的信息传播来推断信息如何在在线媒体空间中流动,从而证明了我们方法的有效性。 We find that the diffusion network of news for the top 1,000 media sites and blogs tends to have a core-periphery structure with a small set of core media sites that diffuse information to the rest of the Web. These sites tend to have stable circles of influence with more general news media sites acting as connectors between them. 译文:我们发现,前1000家媒体网站和博客的新闻传播网络倾向于具有核心-外围结构,其中一小部分核心媒体网站将信息传播到网络的其余部分。这些网站往往有稳定的影响圈,更多的一般新闻媒体网站充当它们之间的连接器。 |
|
|
Additional Key Words and Phrases:
|
|
| 1. INTRODUCTION | |
|
The dissemination of information, cascading behavior, diffusion and spreading of ideas,innovation, information, influence, viruses and diseases are ubiquitous in social and information networks. 译文:信息的传播、级联行为、思想的扩散和传播、创新、信息、影响、病毒和疾病在社会和信息网络中无处不在。 Such processes play a fundamental role in settings that include the spread of technological innovations [Rogers 1995; Strang and Soule 1998], word of mouth effects in marketing营销中的口碑效应 [Domingos and Richardson 2001; Kempe et al. 2003; Leskovec et al. 2006a], the spread of news and opinions新闻和观点的传播 [Adar et al. 2004; Gruhl et al. 2004; Leskovec et al. 2007c, 2009; Liben-Nowell and Kleinberg 2008], collective problem-solving集体问题解决 [Kearns et al. 2006], the spread of infectious diseases传染病的传播 [Anderson and May 2002; Bailey 1975; Hethcote 2000], and sampling methods for hidden populations隐藏总体的采样方法 [Goodman 1961; Heckathorn 1997].
In order to study network diffusion, there are two fundamental challenges one has to address. First, to be able to track cascading processes taking place in a network, one needs to identify the contagion (the idea, information, virus, disease) that is actually spreading and propagating over the edges of the network. Moreover, one then has to identify a way to successfully trace the contagion as it is diffusing through the network. For example, when tracing information diffusion, it is a nontrivial task to automatically and on a large scale, identify the phrases or memes that are spreading through the Web [Leskovec et al. 2009]. 译文:为了研究网络扩散,有两个基本的挑战必须解决。 译文:首先,为了能够跟踪网络中发生的级联过程,人们需要识别在网络边缘实际传播和传播的传染病(思想、信息、病毒、疾病)。 (需要刻画网络——节点、边、以及传播信息,以及设计节点和边使其包含信息的数据结构) 译文:例如,在跟踪信息扩散时,自动地、大规模地识别通过Web传播的短语或模因是一项非常重要的任务。
Second, we usually think of diffusion as a process that takes place on a network, where the contagion propagates over the edges of the underlying network from node to node like an epidemic. However, the network over which propagations take place is usually unknown and unobserved. Commonly, we only observe the times when particular nodes get infected but we do not observe who infected them. (后续举例3个)In the case of information propagation, as bloggers discover new information, they write about it without explicitly citing the source. Thus, we only observe the time when a blog gets infected with information, but not where it got infected from. Similarly, in virus propagation, we observe people getting sick without usually knowing who infected them. And, in a viral marketing setting, we observe people purchasing products or adopting particular behaviors without explicitly knowing who the influencer was that caused the adoption or the purchase. 译文:其次,我们通常认为扩散是一个发生在网络上的过程,传染像流行病一样在底层网络的边缘从一个节点传播到另一个节点。 译文:然而,传播发生的网络通常是未知的和未被观察到的。 译文:通常,我们只观察特定节点感染的时间,而不观察是谁感染了它们。
These challenges are especially pronounced in information diffusion on the Web. There have been relatively few large-scale studies of information propagation in large networks [Adar and Adamic 2005; Leskovec et al. 2006b, 2007c; Liben-Nowell and Kleinberg 2008]. In order to study paths of diffusion over networks, one essentially requires complete information about who influences whom, as a single missing link in a sequence of propagations can lead to wrong inferences [Sadikov et al. 2011]. Even if one collects near-complete large-scale diffusion data, it is a nontrivial task to identify textual fragments that propagate relatively intact through the Web without human supervision. And even then the question of how information diffuses through the network still remains. Thus, the questions are, what is the network over which the information propagates on the Web? What is the global structure of such a network? How do news media sites and blogs interact? What roles do different sites play in the diffusion process and how influential are they? 译文:关于大网络中信息传播的大规模研究相对较少。 译文:为了研究网络上的传播路径,人们本质上需要关于谁影响谁的完整信息,因为传播序列中的单个缺失环节可能导致错误的推断。 译文:即使收集了近乎完整的大规模传播数据,识别在没有人类监督的情况下通过Web相对完整地传播的文本片段也是一项重要的任务。即便如此,信息如何通过网络传播的问题仍然存在。 译文:因此,问题是,信息在Web上传播的网络是什么?这样一个网络的全球结构是什么?新闻媒体网站和博客是如何互动的?不同的地点在传播过程中扮演什么角色?它们的影响有多大?
Our approach to inferring networks of diffusion and influence. We address these questions by positing that there is some underlying unknown network over which information, viruses, or influence propagate. We assume that the underlying network is static and does not change over time. We then observe the times when nodes get infected by, or decide to adopt, a particular contagion (a particular piece of information, product, or a virus) but we do not observe where they got infected from. Thus, for each contagion, we only observe times when nodes got infected, and we are then interested in determining the paths the diffusion took through the unobserved network. Our goal is to reconstruct the network over which contagions propagate. Figure 1 gives an example. 译文:我们的方法来推断网络的扩散和影响。我们通过假设存在一些潜在的未知网络来解决这些问题,这些网络是信息、病毒或影响传播的基础。 译文:我们假设底层网络是静态的,不随时间变化。然后,我们观察节点被感染或决定采用特定传染(特定信息、产品或病毒)的时间,但我们不观察它们从哪里受到感染。因此,对于每个传染,我们只观察节点被感染的时间,然后我们感兴趣的是确定扩散在未被观察到的网络中所采取的路径。我们的目标是重建传染病传播的网络。
Edges in such networks of influence and diffusion have various interpretations.In virus or disease propagation, edges can be interpreted as who-infects-whom. In Inferring Networks of Diffusion and Influence information propagation, edges are who-adopts-information-from-whom or who-listens-to-whom. In a viral marketing setting, edges can be understood as who-influences-whom. 译文:这种影响和扩散网络的边缘有各种各样的解释。在病毒或疾病传播中,边缘可以解释为谁感染谁。在传播和影响信息传播的推断网络中,谁从谁那里接受信息或谁听谁的信息是边缘。在病毒式营销环境中,边缘可以理解为谁影响谁。 The main premise of our work is that by observing many different contagions spreading among the nodes, we can infer the edges of the underlying propagation 。 The concept of a set of contagions over a network is illustrated in Figure 2. As a contagion spreads over the underlying network it creates a trace, called a cascade. Nodes of the cascade are the nodes of the network that got infected by the contagion and 译文:图2说明了网络上的一组传染的概念。当传染在底层网络中蔓延时,它会产生一种被称为级联的痕迹。级联的节点是网络中被传染的节点,级联的边缘代表传染实际传播的网络边缘。 译文:在图2的顶部,显示了传染病传播的潜在真实网络。随后的每一层都描绘了一个由特定传染产生的级联。 译文:先验地,我们不知道底层真实网络的连通性,我们的目标是使用许多级联中节点的感染时间来推断这种连通性。(这与我们重启阶段传播蕴含图不同,我们已知子句中变元的链接关系,把他作为底层网络,)
We develop NETINF, a scalable algorithm for inferring networks of diffusion and influence. We first formulate a generative probabilistic model of how, on a fixed hypothetical network, contagions spread as directed trees (a node infects many other nodes) through the network. Since we only observe times when nodes get infected, there are many possible ways the contagion could have propagated through the network that are consistent with the observed data. In order to infer the network we have to consider all possible ways the contagion could spread through the network. Thus, naive computation of the model takes exponential time since there is a combinatorially large number of propagation trees. We show that, perhaps surprisingly, computations over this superexponential set of trees can be performed in polynomial (quadratic) time. However, with such a model, the network inference problem is still intractable. Thus, we introduce a tractable approximation, and show that the objective function can be both efficiently computed and efficiently optimized. By exploiting a diminishing returns property of the problem, we prove that NETINF infers near-optimal networks. We also speed-up NETINF by exploiting the local structure of the objective function and by using lazy evaluations [Leskovec et al. 2007b]. 译文:我们开发了NETINF,一个可扩展的算法,用于推断网络的扩散和影响。我们首先制定了一个生成概率模型,在一个固定的假设网络上,传染如何通过网络作为有向树传播(一个节点感染许多其他节点)。 译文:由于我们只观察节点被感染的时间,因此有许多可能的传染方式可以通过网络传播,这些方式与观察到的数据一致。为了推断这个网络,我们必须考虑传染通过网络传播的所有可能方式。 译文:因此,由于存在大量的传播树,模型的初始计算需要指数级的时间。我们表明,也许令人惊讶的是,在这个超指数树集上的计算可以在多项式(二次)时间内执行。
In a broader context, our work here is related to the network structure learning problem of probabilistic directed graphical models [Friedman et al. 1999; Getoor et al. 2003], where heuristic greedy hill-climbing or stochastic search, niether of which offer performance guarantees, are usually used in practice. In contrast, our work here provides a novel formulation and a tractable polynomial time algorithm for inferring directed networks together with an approximation guarantee that ensures the inferred networks will be of near-optimal quality. 译文:在更广泛的背景下,我们这里的工作与概率有向图模型的网络结构学习问题有关[Friedman et al. 1999;Getoor et al. 2003],其中启发式贪婪爬坡或随机搜索,两者都不提供性能保证,通常在实践中使用。相比之下,我们在这里的工作为推断有向网络提供了一个新的公式和一个易于处理的多项式时间算法,以及一个近似保证,确保推断的网络将具有接近最优的质量。 Our results on synthetic datasets show that we can reliably infer an underlying propagation and influence network, regardless of the overall network structure. Validation on real and synthetic datasets shows that NETINF outperforms a baseline heuristic by an order of magnitude and correctly discovers more than 90% of the edges. We apply our algorithm to a real Web information propagation dataset of 170 million blog and news articles over a one year period. Our results show that online news propagation networks tend to have a core-periphery structure with a small set of core blog and news media Web sites that diffuse information to the rest of the Web. News media Web sites tend to diffuse the news faster than blogs, and blogs keep discussing news for a longer time than media Web sites. 译文:我们在合成数据集上的结果表明,无论整体网络结构如何,我们都可以可靠地推断出潜在的传播和影响网络。 译文:在真实数据集和合成数据集上的验证表明,NETINF比基线启发式算法的性能要好一个数量级,并且正确发现了90%以上的边缘。 译文:我们将我们的算法应用于一个真实的Web信息传播数据集,该数据集包含一年中1.7亿篇博客和新闻文章。我们的研究结果表明,在线新闻传播网络倾向于具有核心-外围结构,其中一小部分核心博客和新闻媒体网站将信息传播到网络的其余部分。新闻媒体网站往往比博客更快地传播新闻,博客比媒体网站持续讨论新闻的时间更长。
Inferring how information or viruses propagate over networks is crucial for a better understanding of diffusion in networks. By modeling the structure of the propagation network, we can gain insight into positions and roles various nodes play in the diffusion process and assess the range of influence of nodes in the network. 译文:推断信息或病毒如何在网络上传播对于更好地理解网络扩散至关重要。通过对传播网络的结构进行建模,我们可以了解各个节点在传播过程中的位置和作用,并评估网络中节点的影响范围。
The rest of the article is organized as follows. Section 2 is devoted to the statement of the problem, the formulation of the model, and the optimization problem. In Section 3, an efficient reformulation of the optimization problem is proposed and its solution 译文:本文的其余部分组织如下。第2节致力于问题的陈述,模型的制定和优化问题。在第3节中,提出了优化问题的一个有效的重新表述,并给出了其解决方案。使用synthetic和MemeTracker数据的实验评估见第4节。我们在第5节结束相关工作,并在第6节讨论我们的结果。 |
|
| 2. DIFFUSION NETWORK INFERENCE PROBLEM 扩散网络推理问题 | |
|
We next formally describe the problem where contagions propagate over an unknown static directed network and create cascades. For each cascade we observe times when nodes got infected but not who infected them. The goal then is to infer the unknown network over which contagions originally propagated. In an information diffusion setting, each contagion corresponds to a different piece of information that spreads over the network and all we observe are the times when particular nodes adopted or mentioned particular information. The task then is to infer the network where a directed edge (u, v) carries the semantics that node v tends to get influenced by node u (mentions or adopts the information after node u does so as well). cascade 信息传递过程单元(级联) Implicit structure and the dynamics of propagation space 隐含结构和传播空间的动态 Recovering time-varying networks of dependencies in *** studies ***中恢复时变网络依赖 译文:接下来,我们将正式描述传染在未知的静态有向网络上传播并产生级联的问题。 译文:对于每个级联,我们观察节点被感染的时间,而不是谁感染了它们。然后,目标是推断出传染病最初传播的未知网络。 译文:在信息扩散的环境中,每一种传染都对应于在网络中传播的不同信息,我们所观察到的是特定节点采用或提到特定信息的时间。 译文:接下来的任务是推断有向边(u, v)携带节点v容易受到节点u影响的语义的网络(节点u也提到或采用了节点u之后的信息)。 |
|
|
2.1 Problem Statement 问题陈述 问题陈述:对一个问题或任务的详细描述,通常包括问题的背景、目标、限制条件等,以便于解决问题或完成任务。 |
|
|
从网络的视角,节点在当前传染病c流行情况下在tv时刻被感染;从cascade的角度,全体节点对应被感染的时刻集合构成一个向量tc。
|
|
| 2.2 Cascade Transmission Model | |
|
|
|
| 3. ALTERNATIVE FORMULATION AND THE NETINF ALGORITHM | |
|
The diffusion network inference problem defined in the previous section does not seem |
|
| 3.1 An Alternative Formulation | |
|
We use the same tree cascade formation model as in the previous section. However, we compute an approximation of the likelihood of a single cascade by considering only the most likely tree instead of all possible propagation trees. 译文:我们使用与前一节相同的树级联形成模型。然而,我们通过只考虑最可能的树而不是所有可能的传播树来计算单个级联可能性的近似值。 We show that this approximate likelihood is tractable to compute. Moreover, we also devise an algorithm that provably finds networks with near optimal approximate likelihood. In the remainder of this section, we informally write likelihood and log-likelihood even though they are approximations. However, all approximations are clearly indicated. 译文:我们证明了这种近似似然是易于计算的。此外,我们还设计了一种算法,可以证明找到具有接近最优近似似然的网络。在本节的其余部分中,我们将非正式地写为似然和对数似然,尽管它们是近似值。然而,所有的近似值都清楚地表明。
First we introduce the concept of ε-edges to account for the fact that nodes may get infected for reasons other than the network influence. For example, in online media, not all the information propagates via the network—some is pushed onto the network by the mass media [Katz and Lazarsfeld 1955; Watts and Dodds 2007] and thus a disconnected cascade can be created. Similarly, in viral marketing, a person may purchase a product due to the influence of peers (network effect) or for some other reason (e.g., seing a commercial on TV) [Leskovec et al. 2006a]. 译文:首先,我们引入ε-边的概念,以解释节点可能因网络影响以外的原因而受到感染的事实。
Modeling external influence via ε-edges. To account for such phenomena when a cascade jumps across the network we can think of creating an additional node x that represents an external influence and can infect any other node u with small probability. We then connect the external influence node x to every other node u with an ε-edge. Then every node u can get infected by the external source x with a very small probability ε. For example, in the case of information diffusion in the blogosphere, such a node x could model the effect of blogs getting infected by the mainstream media. 译文:利用ε-边对外部影响进行建模 译文:为了解释级联在网络上跳跃时的这种现象,我们可以考虑创建一个额外的节点x,它代表外部影响,并且可以以小概率感染任何其他节点u。然后,我们用ε-边将外部影响节点x连接到每个其他节点u。 译文:例如,在博客圈的信息传播情况下,这样的节点x可以模拟博客被主流媒体感染的影响。
译文:然而,如果我们采用这种方法并在数据中插入一个额外的外部影响节点x,我们还需要推断出指向x的边,这将使我们的问题变得更加困难。 译文:因此,为了捕捉外部影响的影响,我们引入了ε-edge的概念。如果网络中节点i和节点j之间不存在网络边,则增加一条ε边,则节点i可以以小概率ε感染节点j。
|
|