

最近参加了2022约束求解基础与应用训练营,受益良多。感谢包括蔡少伟教授在内的全体组织者。将其中完成的一项作业发布到这里,做阶段小结的备查资料。
一、改进说明
本人阅读并了解 CDCL 求解器 microsat 的代码,按照课程作业要求将microsat改进为microsat_Scavel。
主要改进点如下:
1.改进之一:二值观察watcher对子句设置观察文字时,优先选择在样例本身较少出现变元。具体做法是:
(1)结构体struct solver增加统计个变元出现次数的数组myLitsNum,并在结构体初始化时将数组中各元素初始为0;
(2)在读写cnf文件模块函数体int parse(struct solver *S, char *filename)*中,先变量一遍cnf文件记录各个变元的出现次数;再遍历一遍cnf中学习子句部分字符,在读取到每个子句进入S->buffer之后,对子句中个文字的排列做出调整:按照数组myLitsNum存储的变元出现次数值由小到大排序。排序代码采用的是冒泡排序法。
(3)在int *addClause(struct solver *S, int *in, int size, int irr)函数中,二值观察设置观察文字时选择的子句位置处在0和1位置的文字自然就是在样例本身较少出现变元所对应的文字。
(4)说明1:在增加学习子句时,这样设置可以一定程度反映样例本身的统计学特征。
(5)说明2:我们也测试了将(2)中排序按照从大到小排列。与前者及不做排序相比测试反映出效果整体略差一些。
2.改进之二:增加了luby重启。具体做法是:
(1)luby重启是较为有效的静态序列用于重启的技术,在许多求解器中都有应用。我们移植了minisat中static double luby(double y, int x)函数,放在microsat.c代码的前部;
(2)在int solve(struct solver *S) 中调用luby函数时,我们设置y取2,x为已经重启的次数,并将其乘以100;
(3)我们保留原有的移动平均重启判别条件触发重启代码段,用于冲突次数nConflicts > 10000之后发生重启;新添加的luby重启技术只用于求解过程的前期(nConflicts <=10000).
(4)说明1:在求解过程前期采用luby重启策略,是现代求解器采用的通用方法,能使得求解一部分样例时求解过程显著加快。
(5)说明2:luby重启与原有的基于the fast and slow moving averages比较的重启策略切换时机我们没有进一步研究。代码中采用的冲突次数10000只是一个随意设置的值。
3.改进之三:增加基于子句lbd值的学习子句管理。具体做法是:
(1)每个子句在开辟空间是增加存储lbd的空间,其lbd初始化为-1;涉及将addClause函数改造为:int *addClause(struct solver *S, int *in, int size, int irr, int lbd_ );
(2)冲突分析得到****学习子句lbd值,通过新的addClause函数将子句的lbd值与子句其它属性一并保存;
(3)在学习子句管理时,原有的基于学习子句文字数的策略并列上基于子句lbd值小于4的条件:在函数void reduceDB(struct solver *S, int k) 中,做如下改动:
改动前
if (count < k)
addClause(S, S->DB + head, i - head, 0);
改动后
if ( (count < k) || ( (lbd < 4) && (lbd > 0) ) )
addClause(S, S->DB + head, i - head, 0, lbd);
(4)说明1:学习子句增加lbd属性在开辟子句空间以及操作(读写)空间对源代码多出改动,是一个难点;
(5)说明2:在(3)中lbd阀值设为4,这个值是本人基于一般现代求解器的经验随意给定的值,没有经过大量测试。
4.改进之四:增加了部分用于测试输出的代码。具体做法是:
(1)增加了用于记录时刻的函数static inline double cpuTime(void);
(2)在主函数main中求解起始和结束分别记录CPU时刻,进而得到求解样例以秒为单位的用时。
(3)增加了记录重启次数的数据量并改进了输出语句。
二、改进测试示例
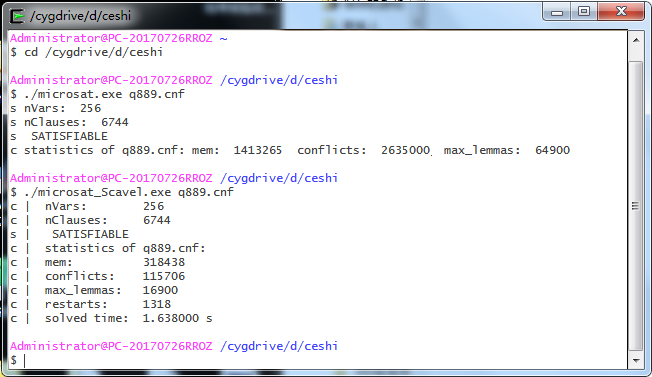
|
三、改进后源码


/**************************************************************[microsat.c] to [microsat_Scavel.c]**** The MIT License Copyright (c) 2014-2018 Marijn Heule Improved by Zhihui Li of Southwest Jiaotong University in May 2022. Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. The improvement measures by Zhihui Li mainly include three aspects: before the establishment of Tow_Watcher of every clause, the literals in clauses are sorted according to the frequency of the literals appearing in CNF; The luby restart policy is adopted for early restart; Add the learnd clause LBD attribute and use it for learned clause management. *******************************************************************************/ #include <stdio.h> #include <stdlib.h> #include <math.h> #include <sys/time.h> #include <sys/resource.h> #include <unistd.h> static double luby(double y, int x){ // Find the finite subsequence that contains index 'x', and the // size of that subsequence: int size, seq; for (size = 1, seq = 0; size < x+1; seq++, size = 2*size+1); while (size-1 != x){ size = (size-1)>>1; seq--; x = x % size; } return pow(y, seq); } static inline double cpuTime(void) { struct rusage ru; getrusage(RUSAGE_SELF, &ru); return (double)ru.ru_utime.tv_sec + (double)ru.ru_utime.tv_usec / 1000000; } enum { END = -9, UNSAT = 0, SAT = 1, MARK = 2, IMPLIED = 6 }; // The variables in the struct are described in the initCDCL procedure struct solver { int *DB, nVars, nClauses, mem_used, mem_fixed, mem_max, maxLemmas, nLemmas, *buffer, nConflicts, *model, *reason, *falseStack, *false, *first, *myLitsNum, nrestarts, nof_conflicts, *forced, *processed, *assigned, *next, *prev, head, res, fast, slow; }; // Unassign the literal void unassign(struct solver *S, int lit) { S->false[lit] = 0; } // Perform a restart (i.e., unassign all variables) void restart(struct solver *S) { S->nrestarts ++; // Remove all unforced false lits from falseStack while (S->assigned > S->forced) unassign(S, *(--S->assigned)); // Reset the processed pointer S->processed = S->forced; } // Make the first literal of the reason true void assign(struct solver *S, int *reason, int forced) { // Let lit be the first literal in the reason int lit = reason[0]; // Mark lit as true and IMPLIED if forced S->false[-lit] = forced ? IMPLIED : 1; // Push it on the assignment stack *(S->assigned++) = -lit; // Set the reason clause of lit S->reason[abs(lit)] = 1 + (int)((reason)-S->DB); // Mark the literal as true in the model S->model[abs(lit)] = (lit > 0); } // Add a watch pointer to a clause containing lit // By updating the database and the pointers void addWatch(struct solver *S, int lit, int mem) { S->DB[mem] = S->first[lit]; S->first[lit] = mem; } // Allocate memory of size mem_size int *getMemory(struct solver *S, int mem_size) { // In case the code is used within a code base if (S->mem_used + mem_size > S->mem_max) { printf("c out of memory\n"); exit(0); } // Compute a pointer to the new memory location int *store = (S->DB + S->mem_used); // Update the size of the used memory S->mem_used += mem_size; // Return the pointer return store; } // Adds a clause stored in *in of size size int *addClause(struct solver *S, int *in, int size, int irr, int lbd_ ) { // Store a pointer to the beginning of the clause int i, used = S->mem_used; // Allocate memory for the clause in the database int *clause = getMemory(S, size + 4) + 3; clause[-1] = lbd_; // If the clause is not unit, then add // Two watch pointers to the datastructure if (size > 1) { addWatch(S, in[0], used); addWatch(S, in[1], used + 1); } // Copy the clause from the buffer to the database for (i = 0; i < size; i++) clause[i] = in[i]; clause[i] = 0; // Update the statistics if (irr) S->mem_fixed = S->mem_used; else S->nLemmas++; // Return the pointer to the clause in the database return clause; } // Removes "less useful" lemmas from DB void reduceDB(struct solver *S, int k) { while (S->nLemmas > S->maxLemmas) { // Allow more lemmas in the future S->maxLemmas += 300; // Reset the number of lemmas S->nLemmas = 0; } int i; // Loop over the variables for (i = -S->nVars; i <= S->nVars; i++) { if (i == 0) continue; // Get the pointer to the first watched clause int *watch = &S->first[i]; // As long as there are watched clauses while (*watch != END) { // Remove the watch if it points to a lemma if (*watch < S->mem_fixed) watch = (S->DB + *watch); // Otherwise (meaning an input clause) go to next watch else *watch = S->DB[*watch]; } } int old_used = S->mem_used; S->mem_used = S->mem_fixed; // Virtually remove all lemmas // While the old memory contains lemmas //for (i = S->mem_fixed + 2; i < old_used; i += 3) { for (i = S->mem_fixed + 3; i < old_used; i += 4) { // Get the lemma to which the head is pointing int count = 0, head = i; int lbd = S->DB[i-1]; // Count the number of literals // That are satisfied by the current model while (S->DB[i]) { int lit = S->DB[i++]; if ((lit > 0) == S->model[abs(lit)]) count++; } // If the latter is smaller than k, add it back if ( (count < k) || ( (lbd < 4) && (lbd > 0) ) ) addClause(S, S->DB + head, i - head, 0, lbd); } } // Move the variable to the front of the decision list void bump(struct solver *S, int lit) { // MARK the literal as involved if not a top-level unit if (S->false[lit] != IMPLIED) { S->false[lit] = MARK; int var = abs(lit); // In case var is not already the head of the list if (var != S->head) { S->prev[S->next[var]] = S->prev[var]; // Update the prev link S->next[S->prev[var]] = S->next[var]; // Update the next link S->next[S->head] = var; // Add a next link to the head S->prev[var] = S->head; // Make var the new head S->head = var; } } } // Check if lit(eral) is implied by MARK literals int implied(struct solver *S, int lit) { // If checked before return old result if (S->false[lit] > MARK) return (S->false[lit] & MARK); // In case lit is a decision, it is not implied if (!S->reason[abs(lit)]) return 0; // Get the reason of lit(eral) int *p = (S->DB + S->reason[abs(lit)] - 1); // While there are literals in the reason while (*(++p)) // Recursively check if non-MARK literals are implied if ((S->false[*p] ^ MARK) && !implied(S, *p)) { // Mark and return not implied (denoted by IMPLIED - 1) S->false[lit] = IMPLIED - 1; return 0; } // Mark and return that the literal is implied S->false[lit] = IMPLIED; return 1; } // Compute a resolvent from falsified clause int *analyze(struct solver *S, int *clause) { // Bump restarts and update the statistic S->res++; S->nConflicts++; S->nof_conflicts--; // MARK all literals in the falsified clause while (*clause) bump(S, *(clause++)); // Loop on variables on falseStack // until the last decision while (S->reason[abs(*(--S->assigned))]) { // If the tail of the stack is MARK if (S->false[*S->assigned] == MARK) { // Pointer to check if first-UIP is reached int *check = S->assigned; // Check for a MARK literal before decision while (S->false[*(--check)] != MARK) // Otherwise it is the first-UIP so break if (!S->reason[abs(*check)]) goto build; // Get the reason and // ignore first literal clause = S->DB + S->reason[abs(*S->assigned)]; // MARK all literals in reason while (*clause) bump(S, *(clause++)); } // Unassign the tail of the stack unassign(S, *S->assigned); } build:; // Build conflict clause; Empty the clause buffer int size = 0, lbd = 0, flag = 0; int *p = S->processed = S->assigned; // Loop from tail to front while (p >= S->forced) { // Only literals on the stack can be MARKed // If MARKed and not implied if ((S->false[*p] == MARK) && !implied(S, *p)) { // Add literal to conflict clause buffer S->buffer[size++] = *p; flag = 1; } if (!S->reason[abs(*p)]) { // Increase LBD for a decision with a true flag lbd += flag; flag = 0; // And update the processed pointer if (size == 1) S->processed = p; } // Reset the MARK flag for all variables on the stack S->false[*(p--)] = 1; } // Update the fast moving average S->fast -= S->fast >> 5; S->fast += lbd << 15; // Update the slow moving average S->slow -= S->slow >> 15; S->slow += lbd << 5; // Loop over all unprocessed literals while (S->assigned > S->processed) // Unassign all lits between tail & head unassign(S, *(S->assigned--)); // Assigned now equal to processed unassign(S, *S->assigned); // Terminate the buffer (and potentially print clause) S->buffer[size] = 0; // Add new conflict clause to redundant DB return addClause(S, S->buffer, size, 0, lbd); } // Performs unit propagation int propagate(struct solver *S) { // Initialize forced flag int forced = S->reason[abs(*S->processed)]; // While unprocessed false literals while (S->processed < S->assigned) { // Get first unprocessed literal int lit = *(S->processed++); // Obtain the first watch pointer int *watch = &S->first[lit]; // While there are watched clauses (watched by lit) while (*watch != END) { // Let's assume that the clause is unit int i, unit = 1; // Get the clause from DB int *clause = (S->DB + *watch + 2);//int *clause = (S->DB + *watch + 1); // Set the pointer to the first literal in the clause if (clause[-3] == 0) clause++; // Ensure that the other watched literal is in front if (clause[0] == lit) clause[0] = clause[1]; // Scan the non-watched literals for (i = 2; unit && clause[i]; i++) // When clause[i] is not false, it is either true or unset if (!S->false[clause[i]]) { // Swap literals clause[1] = clause[i]; clause[i] = lit; // Store the old watch int store = *watch; unit = 0; // Remove the watch from the list of lit *watch = S->DB[*watch]; // Add the watch to the list of clause[1] addWatch(S, clause[1], store); } // If the clause is indeed unit if (unit) { // Place lit at clause[1] and update next watch clause[1] = lit; watch = (S->DB + *watch); // If the other watched literal is satisfied continue if (S->false[-clause[0]]) continue; // If the other watched literal is falsified, if (!S->false[clause[0]]) { // A unit clause is found, and the reason is set assign(S, clause, forced); } else { // Found a root level conflict -> UNSAT if (forced) return UNSAT; // Analyze the conflict return a conflict clause int *lemma = analyze(S, clause); // In case a unit clause is found, set forced flag if (!lemma[1]) forced = 1; // Assign the conflict clause as a unit assign(S, lemma, forced); break; } } } } // Set S->forced if applicable if (forced) S->forced = S->processed; // Finally, no conflict was found return SAT; } // Determine satisfiability int solve(struct solver *S) { // Initialize the solver int decision = S->head; S->res = 0; // Main solve loop for (;;) { // Store nLemmas to see whether propagate adds lemmas int old_nLemmas = S->nLemmas; // Propagation returns UNSAT for a root level conflict if (propagate(S) == UNSAT) return UNSAT; // If the last decision caused a conflict if (S->nLemmas > old_nLemmas) { // Reset the decision heuristic to head decision = S->head; if (S->nConflicts > 10000) { // If fast average is substantially larger than slow average if (S->fast > (S->slow / 100) * 125) { // printf("c restarting after %i conflicts (%i %i) %i\n", S->res, // S->fast, S->slow, S->nLemmas > S->maxLemmas); // Restart and update the averages S->res = 0; S->fast = (S->slow / 100) * 125; restart(S); // Reduce the DB when it contains too many lemmas if (S->nLemmas > S->maxLemmas) reduceDB(S, 6); } }else{ // the luby restart policy is adopted for early restart if (!S->nof_conflicts) { S->nof_conflicts = luby(2, S->nrestarts) * 100; restart(S); // Reduce the DB when it contains too many lemmas if (S->nLemmas > S->maxLemmas) reduceDB(S, 8); } } } // As long as the temporay decision is assigned while (S->false[decision] || S->false[-decision]) { // Replace it with the next variable in the decision list decision = S->prev[decision]; } // If the end of the list is reached, then a solution is found if (decision == 0) return SAT; // Otherwise, assign the decision variable based on the model decision = S->model[decision] ? decision : -decision; // Assign the decision literal to true (change to IMPLIED-1?) S->false[-decision] = 1; // And push it on the assigned stack *(S->assigned++) = -decision; // Decisions have no reason clauses decision = abs(decision); S->reason[decision] = 0; } } void initCDCL(struct solver *S, int n, int m) { // The code assumes that there is at least one variable if (n < 1) n = 1; // Set the number of variables S->nVars = n; // Set the number of clauses S->nClauses = m; // Set the initial maximum memory S->mem_max = 1 << 30; // The number of integers allocated in the DB S->mem_used = 0; // The number of learned clauses -- redundant means learned S->nLemmas = 0; // Number of conflicts used to update scores S->nConflicts = 0; // Initial maximum number of learned clauses S->maxLemmas = 10000; // Initialize the fast and slow moving averages S->fast = S->slow = 1 << 24; // Allocate the initial database S->DB = (int *)malloc(sizeof(int) * S->mem_max); // Full assignment of the (Boolean) variables (initially set to false) S->model = getMemory(S, n + 1); //get myLitsNum space S->myLitsNum = getMemory(S, n + 1); // Number of restarts S->nrestarts = 0; S->nof_conflicts = 100; // Next variable in the heuristic order S->next = getMemory(S, n + 1); // Previous variable in the heuristic order S->prev = getMemory(S, n + 1); // A buffer to store a temporary clause S->buffer = getMemory(S, n); // Array of clauses S->reason = getMemory(S, n + 1); // Stack of falsified literals -- this pointer is never changed S->falseStack = getMemory(S, n + 1); // Points inside *falseStack at first decision (unforced literal) S->forced = S->falseStack; // Points inside *falseStack at first unprocessed literal S->processed = S->falseStack; // Points inside *falseStack at last unprocessed literal S->assigned = S->falseStack; // Labels for variables, non-zero means false S->false = getMemory(S, 2 * n + 1); S->false += n; // Offset of the first watched clause S->first = getMemory(S, 2 * n + 1); S->first += n; // Make sure there is a 0 before the clauses are loaded. S->DB[S->mem_used++] = 0; int i; // Initialize the main datastructures: for (i = 1; i <= n; i++) { S->prev[i] = i - 1; // the double-linked list for variable-move-to-front, S->next[i - 1] = i; // the model (phase-saving), the false array, S->model[i] = S->false[-i] = S->false[i] = 0; S->myLitsNum[i] = 0; // and first (watch pointers). S->first[i] = S->first[-i] = END; } // Initialize the head of the double-linked list S->head = n; } static void read_until_new_line(FILE *input) { int ch; while ((ch = getc(input)) != '\n') if (ch == EOF) { printf("parse error: unexpected EOF"); exit(1); } } // Parse the formula and initialize int parse(struct solver *S, char *filename) { int tmp; // Read the CNF file FILE *input = fopen(filename, "r"); while ((tmp = getc(input)) == 'c') read_until_new_line(input); ungetc(tmp, input); do { // Find the first non-comment line tmp = fscanf(input, " p cnf %i %i \n", &S->nVars, &S->nClauses); printf("c | nVars: %i\n", S->nVars); printf("c | nClauses: %i\n", S->nClauses); // In case a commment line was found if (tmp > 0 && tmp != EOF) break; tmp = fscanf(input, "%*s\n"); } // Skip it and read next line while (tmp != 2 && tmp != EOF); // Allocate the main datastructures initCDCL(S, S->nVars, S->nClauses); // Initialize the number of clauses to read int nZeros = S->nClauses, size = 0; long moveSize = ftell(input); // While there are clauses in the file while (nZeros > 0) { int ch = getc(input); if (ch == ' ' || ch == '\n') continue; if (ch == 'c') { read_until_new_line(input); continue; } ungetc(ch, input); int lit = 0; // Read a literal. tmp = fscanf(input, " %i ", &lit); // If reaching the end of the clause if (!lit) { // Reset buffer size = 0; --nZeros; } else { // Add literal to buffer S->buffer[size++] = lit; S->myLitsNum[abs(lit)] ++; } } rewind(input); fseek(input, moveSize, 0); nZeros = S->nClauses, size = 0; // While there are clauses in the file while (nZeros > 0) { int ch = getc(input); if (ch == ' ' || ch == '\n') continue; if (ch == 'c') { read_until_new_line(input); continue; } ungetc(ch, input); int lit = 0; // Read a literal. tmp = fscanf(input, " %i ", &lit); // If reaching the end of the clause if (!lit) { // Then add the clause to data_base // bubble_sort for (int i = 1; i < size; ++i) { for (int j = 1; j < size - i - 1; ++j) { int litj = S->buffer[j]; int litjadd1 = S->buffer[j + 1]; //if (S->buffer[j] > S->buffer[j + 1]) { if (S->myLitsNum[abs(litj)] < S->myLitsNum[abs(litjadd1)]) { int tmp = S->buffer[j]; S->buffer[j] = S->buffer[j + 1]; S->buffer[j + 1] = tmp; } } } int *clause = addClause(S, S->buffer, size, 1, -1); // Check for empty clause or conflicting unit if (!size || ((size == 1) && S->false[clause[0]])) // If either is found return UNSAT return UNSAT; // Check for a new unit if ((size == 1) && !S->false[-clause[0]]) { // Directly assign new units (forced = 1) assign(S, clause, 1); } // Reset buffer size = 0; --nZeros; } else // Add literal to buffer S->buffer[size++] = lit; } // Close the formula file fclose(input); // Return that no conflict was observed return SAT; } // The main procedure for a STANDALONE solver int main(int argc, char **argv) { // Create the solver datastructure struct solver S; double initial_time = cpuTime(); // Parse the DIMACS file in argv[1] if (parse(&S, argv[1]) == UNSAT) printf("s | UNSATISFIABLE\n"); // Solve without limit (number of conflicts) else if (solve(&S) == UNSAT) printf("s | UNSATISFIABLE\n"); else // And print whether the formula has a solution printf("s | SATISFIABLE\n"); double solved_time = cpuTime(); printf("c | statistics of %s:\n" , argv[1]); printf("c | mem: %i\n", S.mem_used); printf("c | conflicts: %i\n", S.nConflicts); printf("c | max_lemmas: %i\n", S.maxLemmas); printf("c | restarts: %i\n", S.nrestarts); printf("c | solved time: %f s\n", solved_time - initial_time); return 60; }
