1.
Community and LBD-Based Clause Sharing Policy for Parallel SAT Solving
Vallade V., Le Frioux L., Baarir S., Sopena J., Ganesh V., Kordon F. (2020) Community and LBD-Based Clause Sharing Policy for Parallel SAT Solving. In: Pulina L., Seidl M. (eds) Theory and Applications of Satisfiability Testing – SAT 2020. SAT 2020. Lecture Notes in Computer Science, vol 12178. Springer, Cham. https://doi.org/10.1007/978-3-030-51825-7_2
Abstract
|
Modern parallel SAT solvers rely heavily on effective clause sharing policies for their performance. The core problem being addressed by these policies can be succinctly stated as “the problem of identifying high-quality learnt clauses”. These clauses, when shared between the worker nodes of parallel solvers, should lead to better performance. The term “high-quality clauses” is often defined in terms of metrics that solver designers have identified over years of empirical study. Some of the more well-known metrics to identify high-quality clauses for sharing include clause length, literal block distance (LBD), and clause usage in propagation. In this paper, we propose a new metric aimed at identifying high-quality learnt clauses and a concomitant clause-sharing policy based on a combination of LBD and community structure of Boolean formulas. 译文:我们提出了一种新的度量方法,旨在识别高质量的学习子句。 译文:一种基于LBD和布尔公式社区结构相结合的伴随条款共享策略。
The concept of community structure has been proposed as a possible explanation for the extraordinary performance of SAT solvers in industrial instances. Hence, it is a natural candidate as a basis for a metric to identify high-quality clauses.译文:因此,它自然可以作为识别高质量子句的度量标准的基础。 To be more precise, our metric( 度量标准) identifies clauses that have low LBD and low community number as ones that are high-quality for applications such as verification and testing. The community number of a clause C measures the number of different communities of a formula that the variables in C span.译文:一个C子句的社区数量衡量了不同社区的数量,一个公式的变量在C跨度。 We perform extensive empirical analysis of our metric and clause-sharing policy, and show that our method significantly outperforms state-of-the-art techniques on the benchmark from the parallel track of the last four SAT competitions.译文:我们对我们的度量标准和条款共享政策进行了大量的实证分析,结果表明,我们的方法在基准测试中显著优于最近四届SAT竞赛的最新技术。 |
|
文献学习笔记
|
What makes SAT solving applicable to large real-world problems is the conflict-driven clause learning (CDCL) paradigm译文:使SAT解决方案适用于大型现实问题的是冲突驱动子句学习(CDCL)范式。
There exist two main classes of parallel SAT strategies:译文:并行SAT策略主要有两类: a cooperative one called divide-and-conquer [32] and a competitive one called portfolio [15]. 译文:合作型的叫做分治型[32]竞争型的叫做投资组合[15]。
Both rely on the use of underlying sequential worker solvers that might share their respective learnt clauses. Each of these sequential solvers has a copy of the formula and manages its own learnt clause database. Hence, not all the learnt clauses can be shared and a careful selection must be made in order for the solvers to be efficient. In state-of-the-art parallel solvers this filtering is usually based on the LBD metric. The problem with LBD is its locality, indeed a clause does not necessarily have the same LBD value within the different sequential solvers’ context. LBD的问题在于它的位置,实际上,在不同的顺序求解程序的上下文中,一个子句不一定具有相同的LBD值。
In this work we explore the use of a more global quality measure based on the community structure of each instance.译文:在本研究中,我们探讨了基于每个实例的社区结构的更全局质量度量的使用。 It is well-known that SAT instances encoding real-world problems expose some form of modular structure which is implicitly exploited by modern CDCL SAT solvers.译文:众所周知,编码现实问题的SAT实例暴露了某种形式的模块化结构,现代CDCL SAT求解器隐含地利用了这种结构。 A recurring property of industrial instances (as opposed to randomly-generated ones) is that some variables are more constraint together (linked by more clauses). 译文:工业实例(相对于随机生成的实例)的一个反复出现的特性是,一些变量在一起有更多的约束(由更多的子句链接)。 We say that a group of variables that have strong link with each other and few links with the rest of the problem form a community (a type of cluster over the variable-incidence graph of Boolean formulas). 译文:我们说,一组相互之间有很强联系而与问题的其他部分很少联系的变量构成一个共同体(布尔公式的变量关联图上的一种聚类)。 A SAT instance may contain tens to thousand of communities. we study the relationship between LBD and community, and we analyse the efficacy of LBD and community as predictive metrics of the usefulness of newly learnt clauses. 分析了LBD和社区作为新学习句子有用性预测指标的有效性。
Based on this preliminary analysis, we propose to combine both metrics to form a new one and to use it to implement a learnt clause sharing policy in the parallel SAT solving context.
We implement our new sharing strategy in the solver (P-MCOMSPS [22]) winner of the last parallel SAT competition in 2018, and evaluate our solver on the benchmark from the SAT competition 2016, 2017, 2018, and 2019. We show that our solver significantly outperforms competing solvers over this large and comprehensive benchmark of industrial application instances.译文:我们在2018年平行SAT比赛的求解器(P-MCOMSPS[22])冠军中实施了我们新的共享策略,并以2016年、2017年、2018年和2019年SAT比赛的基准对我们的求解器进行评估。我们展示了我们的求解器在这个大型且全面的工业应用程序实例基准测试中显著优于其他求解器。
2.3 CommunityIt is well admitted that real-life SAT formulas exhibit notable “structures”, explaining why some heuristics such as VSIDS [27] or phase saving [30], for example, work well. 译文:众所周知,现实生活中的SAT公式具有显著的“结构”,这解释了为什么一些启发式方法,例如VSIDS[27]或相位节省[30],能够很好地工作。
样例结构采用的仍然是文献:Ansótegui, C., Giráldez-Cru, J., Levy, J.: The community structure of SAT formulas. In: Cimatti, A., Sebastiani, R. (eds.) SAT 2012. LNCS, vol. 7317, pp. 410–423. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-31612-8_31
A structure of interest in this paper is the so-called community structure [1].
Computing the modularity of a graph is an NP-hard problem [11]. However, there exists greedy and efficient algorithms, returning an approximated lower bound for the modularity of a graph, such as the Louvain method [10].
In the remaining of the paper we use the Louvain method (with a precision ϵ=10−7) to compute communities. Graphs we consider are VIG of formulas already simplified by the SatElite [13] preprocessor.
Community Value of a Clause. We call COM the number of communities on which a clause span: we work on the VIG of the problem, so we consider communities of variables. Each variable belongs to a unique community (determined by the Louvain algorithm). To compute the COM of a clause, we consider the variables corresponding to the literals of the clause and we count the number of distinct communities represented by these variables.译文:为了计算子句的COM,我们考虑对应于子句字面量的变量,并计算由这些变量表示的不同群体的数量。
3 Measures and IntuitionP-MCOMSPS, a portfolio SAT solver, winner of the parallel track of the SAT competition 2018, is used as a reference. It implements a sharing strategy based on incremental values for LBD [22]. 译文:它为LBD实现了基于增量值的共享策略。
4 Combining LBD and Community for Parallel SAT SolvingAs previously stated, we need a metric independent of the local state of a particular solver engine. Structural information about the instance to be solved can be useful. For instance, in a portfolio solver, structural information can be shared among the solvers working on the same formula.译文:如前所述,我们需要一个独立于特定求解器引擎的本地状态的度量。关于要解决的实例的结构信息可能很有用。例如,在一个投资组合求解器中,结构信息可以在使用相同公式的求解器之间共享。
In this paper, we focus on the community structure exhibited by (industrial) SAT instances. The metrics (COM, defined in Sect. 2.3) derived from this structure has been proven to be linked with the LBD in [29]. Besides, it has been used to improve the performances of sequential SAT solving via a preprocessing approach in [2]. 译文:我们关注的是(工业)SAT实例所展示的群落结构。从该结构衍生出来的指标(COM,在2.3节中定义)已被证明与[29]中的LBD相关联。此外,该算法还通过[2]中的预处理方法提高了序列SAT求解的性能。
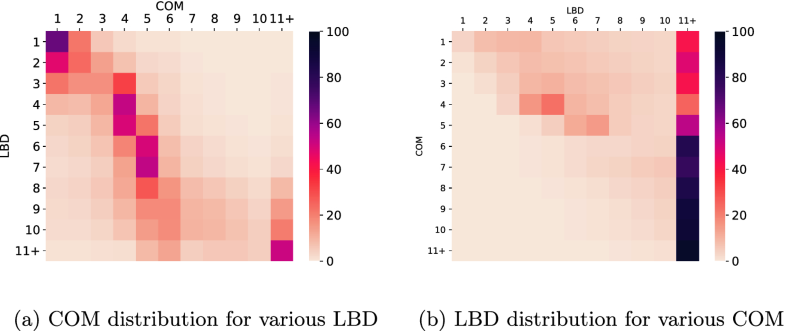
Heatmap showing the distribution between COM and LBD
4.1 LBD Versus Communitiesthe relationship between LBD and COM values thanks to two heatmaps。 From these figures, we can conclude two important statements:
4.2 Composing LBD and Communities译文:此外,L4C2和L4C3的传播利用率的中位数(分别为6.0和6.5)是整个LBD = 4和LBD = 5框的平均值的两倍大(等于2.9,并在两个图中用虚线表示)。 4.3 Community Based FilteringFrom this study, we can conclude that we can use the community structure as a filter for those clauses that have been already selected using an LBD threshold.译文:从这项研究中,我们可以得出结论,我们可以使用社区结构作为那些已经通过LBD阈值选择的子句的过滤器。
最终的结论:Practically, we propose the following strategy: sharing all the clauses with an LBD ≤3 (without any community limit) as well as those with an LBD ≤4 and a COM ≤3. Indeed, the former set of clauses is small while being very useful. Whereas, to select the clauses with COM =3 among the set of clauses with LBD =4 should allow a higher usage ratio while keeping the sharing at a reasonable ratio.
6 Related WorksBesides, multiple works present metrics to improve clause sharing for parallel SAT solving. Penelope [3] implements the progress saving based quality measure (psm). The psm of a clause is the size of the intersection between the clause and the phase saving of the solvers. The greater is the psm the more likely the clause will be satisfied. While receiving learnt clauses, a worker can decide to keep them or not. The drawback is that clauses are exchanged and then filtered which can induce some overhead, and an a priori criteria such as LBD is often used as a balance. 译文:Penelope[3]实现了基于进度节约的质量度量(psm)。子句的psm是子句与求解器的相位节省的交集的大小。 FootnotesReferences
|
|
2.
Simplifying CDCL Clause Database Reduction
Abstract
|
CDCL SAT solvers generate many “learned” clauses, so effective clause database reduction strategies are important to performance. Over time reduction strategies have become complex, increasing the difficulty of evaluating particular factors or introducing new refinements. At the same time, it has been unclear if the complexity is necessary. We introduce a simple online clause reduction scheme, which involves no sorting. We instantiate(举例说明) this scheme with simple mechanisms for taking into account clause activity and LBD within the winning solver from the 2018 SAT Solver Competition, obtaining performance comparable to the original. We also present empirical data on the effects of simple measures of clause age, activity and LBD on performance. 译文:我们还提供了关于条款年龄、活动量和LBD等简单措施对绩效的影响的实证数据。 |
|
学习笔记
|
In particular, most learned clauses must be deleted to keep the clause database of practical size, and the clause database reduction scheme is one of a small number of key heuristic mechanisms in a CDCL solver[3, 14]. 译文:特别是,为了保持子句数据库的实际大小,必须删除大多数学习过的子句,而子句数据库约简方案是CDCL求解器中为数不多的关键启发式机制之一。
The quality measure is typically a combination of size, age, literal block distance (LBD) and some measure of usage or activity [3, 8, 9, 10, 11, 14, 15]. 译文:质量度量通常是大小、年龄、文字块距离(LBD)和一些使用或活动的度量[3,8,9,10,11,14,15]的组合。
There are two main aspects to a clause deletion strategy. 译文:子句删除策略有两个主要方面。
Thus, fast heuristics are desired. One scheme, which we call Delete-Half, is to periodically sort the clauses of Local and delete the half with lowest quality.译文:一种称为delete - half的方案是周期性地对Local子句进行排序,然后删除质量最低的那一半子句。 While some solvers use other schemes (e.g., [4, 16]), we think much more investigation is justified.译文:虽然有些求解者使用其他方案(如[4,16]),但我们认为更多的研究是合理的。
Regarding clause quality, we expect a very good clause quality measure to involve a combination of many factors.译文:关于条款质量,我们期望一个很好的条款质量措施是多方面因素的结合。 The dominant current quality measure uses VSIDS-like clause “activities”. Unfortunately, the way activities are computed and maintained in practice makes it hard to combine activity with other measures of quality in a simple and meaningful way.译文:不幸的是,在实践中计算和维护活动的方式很难以简单而有意义的方式将活动与其他质量度量结合起来。 The goal of this work is to identify simple methods that might largely account for effectiveness of the best current schemes. We make the following contributions. 说明目前最佳方案有效性的简单方法。我们做出了以下贡献。
|
|
2 Online Clause DeletionOur online clause deletion scheme is as follows.
译文:Local的子句维护在一个循环列表L中,该列表L的索引变量i按一个方向遍历该列表。 译文:索引标识当前的“删除候选项”Li。我们有一个子句质量度量Q,和一些阈值质量值q。 译文:当学习到的新子句C需要存储在Local中时,我们选择列表中的“低质量”子句,通过顺序搜索用C替换。 译文:必须选择子句质量度量阈值,以便列表中总是有足够多的“低质量”子句。译文:有一些算法方法可以确保这一点(例如,使用反馈控制机制),但如果没有它们,也不难获得良好的实际性能。
Relating Delete-Half and Online Deletion. Consider a Delete-Half scheme with a sort-and-reduce phase every k conflicts. Roughly speaking (ignoring some details for simplicity) each clause is inspected every k conflicts, deleted if its quality is below the median of the current clauses in Local. 译文:粗略地说(为了简单起见,忽略一些细节)每个子句都会检查每一个k冲突,如果其质量低于当前子句的中位数,就删除。If we instantiate our online scheme with S=2k, and keep q sufficiently close to the median, we expect each clause to be inspected every k conflicts and deleted if its quality is below the median of the current clauses in Local. 译文:我们希望每一个k冲突的条款,如果质量低于Local当前条款的中位数,都要进行检查并删除。In this sense, the two schemes can be made quite close: we trade off sorting for dynamically estimating the median. In doing so, we get a clause database of uniform size, rather than one that significantly grows and shrinks.译文:通过这样做,我们得到了一个大小一致的子句数据库,而不是一个显著增长和收缩的子句数据库。
Age-Based Deletion. A trivially implemented version of our scheme assumes Q(C)<q for every clause C. This results in a pure age-based scheme: Each new learned clause replaces the oldest clause in Local. This very low-cost scheme works surprisingly well. 译文:我们的方案的一个普通实现版本假设每个子句C的Q(C)< Q,这导致了一个纯粹基于年龄的方案:译文:每个新的learned子句替换Local中最老的子句。这个非常低成本的方案出奇地好。
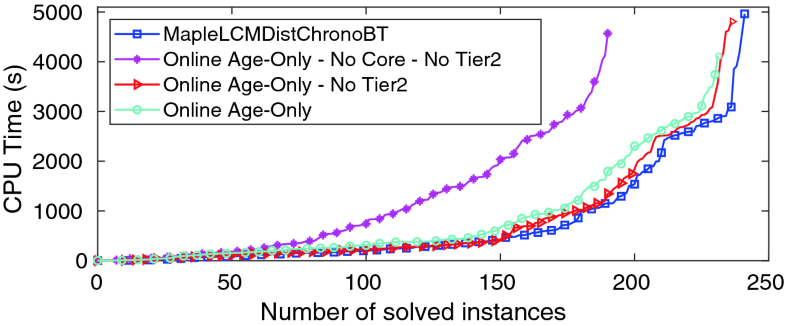
Figure 1 shows a “cactus-plot” comparison of default MapleLCMDistChronoBT with 3 variants using online deletion. (The Local size limit is set to 80,000 clauses in all solvers using online deletion reported here.)
译文:图1显示了核心和Tier2对MapleLCMDistChronoBT的性能非常重要。它还表明,在核心和第2层存在的情况下,一个简单的纯粹基于年龄的本地删除方案提供了相当好的性能。
We make two observations regarding this second point: 译文:关于第二点,我们有两点看法: First, in online deletion with Local of size S, if the probability of saving a clause is as most 0.5 (see Fig. 4), then every learned clause is kept for at least S / 2 conflicts, giving it substantial time to be used. Delete-Half schemes generally do not ensure this. 译文:首先,在本地大小为S的在线删除中,如果保存子句的概率最多为0.5(见图4),那么每个已学习的子句至少会被保留到S / 2冲突中,给它足够的时间来使用。删除一半方案通常不能保证这一点。
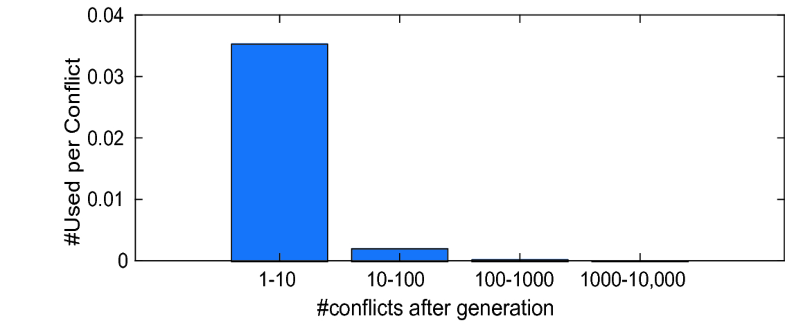
Second, age is highly correlated with usage rate, and can account for a large fraction of decisions that would be made based on clause activities. 译文:年龄与使用率高度相关,并且可以解释很大一部分基于从句活动而做出的决定。 This is illustrated by Fig. 2, which shows the average usage rates of clauses that have been in Local for at least 10K conflicts, at different ages. The usage rate of most clauses drops very quickly.译文:大多数从句的使用率下降很快。
Fig. 2. Rate of use of clauses in Local at different ages.
|
|
3 Clause UsageMiniSAT and many of its successors, including MapleLCMDistChronoBT, use clause “activity” scores in their clause deletion schemes [8, 11, 15]. If a clause is used in conflict analysis, its activity is “bumped”, meaning it’s activity score is increased by a reward value. The reward is initialized to 1 and divided by 0.999 (the decay factor) at each conflict, to similate decay of activities. To prevent activity overflow, when the activity of any clause reaches 1e20, all activity values and the reward value are divided by 1e−20 [5, 8].
This scheme, with many variations, has been widely used, but it also has inconvenient aspects as discussed above.译文:这种方案有许多变体,已被广泛使用,但正如上面所讨论的,它也有一些不方便的方面。 We anticipated that, in the presence of Core, much simpler usage measures might be effective. Here we report two that we have considered. Both are extremely simple to implement.译文:我们预期,在存在核心的情况下,更简单的使用方法可能是有效的。这里我们报告两个我们考虑过的问题。两者都非常容易实现。 We follow their descriptions with reports of three experiments that may shed light on the performance of the RU measures.
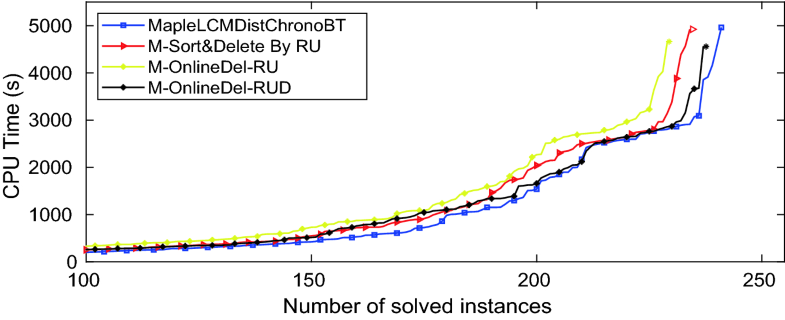
Fig. 3. Online deletion with recent usage
Figure 3 shows the performance of M-OnlineDel-RU with threshold RU = 2 and M-OnlineDel-RUD with RU = 2 and Decay constant 4. Both versions perform quite well, the decay version being almost as good as MapleLCMDistChronoBT. This suggests that online deletion using simple measures might compete effectively with Delete-Half using traditional activities.
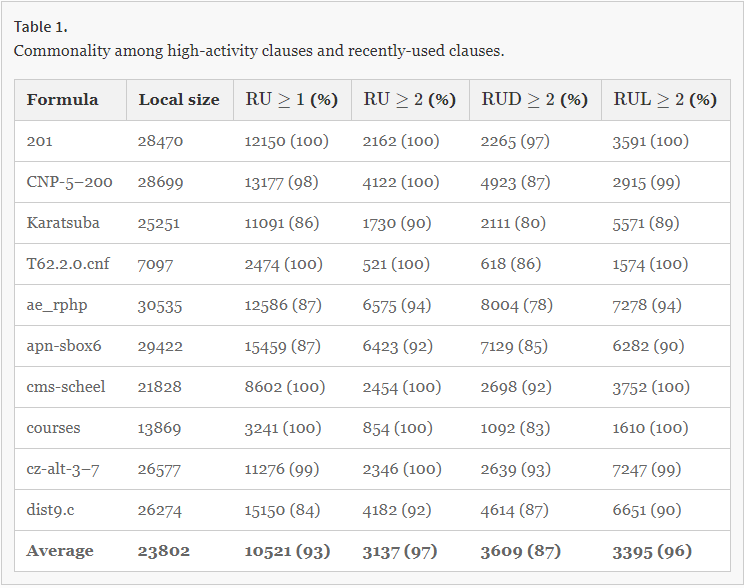
Clauses Saved by RU and Activity 译文:测量他们的RU和活动值,看看我们基于RU的计划可以节省多少条款。
We examined the clauses in Local just before the 10thth clause deletion in MapleLCMDistChronoBT, and measured their RU and activity values to see what fraction of clauses would be saved by our RU-based schemes. Table 1 shows the results for one formula from each of 10 families. The first column is the number of clauses in Local just before deletion. Other columns show the number of clauses that would be saved due to RU≥qRU≥q, and the fraction (in percent) of these clauses that have high enough activity to be saved by Delete-Half. On average this fraction is between 87 and 97%, suggesting that simple RU counters can account for a significant fraction of decisions based on activities.
|
|
4 Clause LBD and Tier2LBD is used in MapleLCMDistChronoBT for initial placement of a learned clause, and to move clauses between stores if the LBD changes. Here we report two simple methods to take into account LBD changes in a solver with online deletion and no Tier2.译文:在这里,我们报告了两种简单的方法来考虑在线删除和没有第2层的求解器中的LBD变化。 Figure 5 show the resulting performance.
译文:这里,我们通过在Local中的子句中添加“Tier 2标志”,用一个粗略的模拟替换了Tier2。 译文:如果MapleLCMDistChronoBT将其从本地移动到第2层,我们将该标志设置为true,反之为false。 译文:这不是一个精确的Tier2模拟,因为子句DB的大小没有适当地改变。尽管如此,最终的性能与原始解算器非常接近。
译文:这里,我们通过修改使用评分来考虑LBD。对于常量c,不是每次使用子句时都将RU加1,而是加c/LBD。
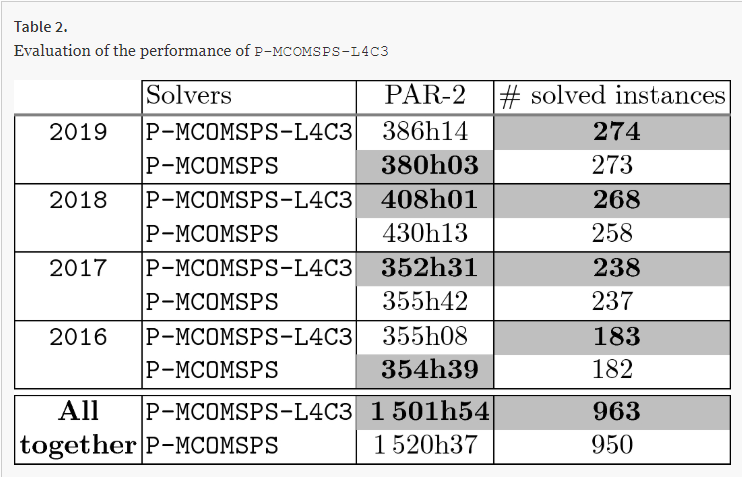
Table 2. Performance on satisfiable vs unsatisfiable formulas. |
|
5 DiscussionWe introduced a new, simple online clause deletion scheme, and reported the performance of instantiations of the scheme using clause age, LBD and very simple measures of usage. An implementation of the online scheme in MapleLCMDistChronoBT, the winning solver from the main track of the 2018 SAT Solver Competition, has performance almost as good as the original.
Online deletion requires less computation time than the Delete-Half scheme. However, the fraction of run time consumed by deletion in MapleLCMDistChronoBT is small, so this is not a major performance factor.
The online deletion schemes in this paper use age or age modified by a fixed quality threshold. A dynamic threshold may be more desirable, in which case we may use a feedback control scheme to ensure the threshold is such that the fraction of saved clauses is suitable (cf Fig. 4).译文:我们可以使用一个反馈控制方案来确保阈值是这样的,保存的子句的分数是合适的。
We continue to investigate more refined versions of our scheme, in particular with regard to clause quality measures and clause database size. Table 2 shows that our modified solvers are biased toward Satisfiable instances, and we will work on shifting this bias.译文:我们改进的求解器偏向于可满足的情况,我们将努力改变这种偏向。 |
|
|
阅读心得: 1.本文提供的最好版本:记录学习子句的使用次数,如果在本轮reduce到来时,基于活跃度需要删除,但是如果RU>2,则不删除,继续保留在local,不过将RU值清零或除以4.前一种称为M-OnlineDel-RU;后一种方式本文中称为M-OnlineDel-RUD。 2.本文提出的tier2Falg,具有创新和启发性。 |