


Coverage-Based Clause Reduction Heuristics for CDCL Solvers
Nabeshima H., Inoue K. (2017) Coverage-Based Clause Reduction Heuristics for CDCL Solvers. In: Gaspers S., Walsh T. (eds) Theory and Applications of Satisfiability Testing – SAT 2017. SAT 2017. Lecture Notes in Computer Science, vol 10491. Springer, Cham. https://doi-org-s.era.lib.swjtu.edu.cn/10.1007/978-3-319-66263-3_9
Abstract
|
Many heuristics, such as decision, restart, and clause reduction heuristics, are incorporated in CDCL solvers in order to improve performance. In this paper, we focus on learnt clause reduction heuristics, which are used to suppress memory consumption and sustain propagation speed. 译文:在本文中,我们关注于学习子句约简启发式,用于抑制内存消耗和保持传播速度。 The reduction heuristics consist of evaluation criteria, for measuring the usefulness of learnt clauses, and a reduction strategy in order to select clauses to be removed based on the criteria. LBD (literals blocks distance) is used as the evaluation criteria in many solvers. For the reduction strategy, we propose a new concise schema based on the coverage ratio of used LBDs. 译文:一种新的基于已用lbd覆盖率的简明模式.The experimental results show that the proposed strategy can achieve higher coverage than the conventional strategy and improve the performance for both SAT and UNSAT instances. |
|
1 Introduction
| Many heuristics, such as decision, phase selection, restart, and clause reduction heuristics, are used in CDCL solvers in order to improve performance. For example, Katebi et al., show that decision and restart heuristics have resulted in significant performance improvement in their paper evaluating the components of CDCL solvers [5]. In this paper, we focus on clause reduction heuristics, which remove useless learnt clauses in order to suppress memory consumption and sustain propagation speed. Clause reduction is practically required since CDCL solvers learn a large number of clauses while solving. The reduction heuristics consist of evaluation criteria to measure the usefulness of learnt clauses and the reduction strategy for selecting clauses to be removed based on the criteria. | |
|
As the former evaluation criteria, LBD (literals blocks distance) [1] is implemented in many solvers. LBD is an excellent measure to identify learnt clauses that are likely to be used frequently. In this paper, we present experimental evidence of the identification power of LBD in a wide range of instances. Moreover, we show that an appropriate threshold for LBD, which are used to decide if clauses should be maintained or not, is determined depending on a given instance. However, a certain fixed threshold of LBD is often used in latter reduction strategies. In this paper, we propose a new reduction strategy based on the coverage of used LBDs, which dynamically computes an appropriate LBD threshold in order to cover most propagations and conflicts. The experimental results show that our schema effectively maintains the used clauses and achieves performance improvement for both SAT and UNSAT instances. |
|
| The rest of this paper is organized as follows: Sect. 2 reviews clause reduction heuristics used in CDCL solvers. In Sects. 3 and 4, we provide experimental results, in order to clarify the property of LBD, and to point out some issues in the LBD-based reduction strategy, respectively. Our proposed reduction strategy is described in Sect. 5. Section 6 shows the experimental results and Sect. 7 concludes this paper. | |
2 Clause Reduction Heuristics
|
The CDCL algorithm repeats the following two operations until a conflict occurs.1.
|
|
| For each assigned literal l, the decision level of l is defined as the number of decision literals on and before assigning l. By dl(l)dl(l), we denote the decision level of the literal l. When a conflict (falsified clause) occurs in the first step, the algorithm analyzes a cause of the conflict and learns a clause from the cause in order to prevent repeating the same conflict. The learnt clause is added to the clause database; then, the algorithm backjumps to the appropriate decision level computed from the clause. | |
| CDCL solvers learn a large number of clauses during the search process of a given SAT instance. Hence, solvers should reduce the clause database periodically in order to suppress memory consumption and sustain propagation speed. In this section, we introduce reduction heuristics based on LBD, which was firstly introduced in Glucose solver. First, we present the evaluation criteria LBD in order to sort learnt clauses according to usefulness.译文:我们提出了LBD的评价标准,以便根据有用性对学习过的句子进行排序。 | |
Definition 1 |
|
 |
|
|
By lbd(C), we denote the LBD of clause C. When a learnt clause is generated, the LBD of the clause is computed based on the current assignment. Additionally, the LBD is updated when the clause is used in unit propagations and the new LBD is smaller than the old one1. Literals with the same decision level have a possibility to be assigned at the same time in the future. Hence, small LBD clauses have a high possibility, which will be used in unit propagations and conflicts. We show the experimental evidence in the next section. 译文:此外,当在单元传播中使用子句时,会更新LBD,并且新LBD比旧LBD小。 |
|
Next, we review the clause reduction strategy used in Glucose. The clause database reduction is executed every l first +l inc ×xl first +l inc ×x conflicts2, where x is the number of reduction calls (initially x=0x=0). On each reduction, clauses are reduced according to the following policy that contains two exceptional conditions:
|
|
| In the following, we refer the above base policy and two exceptional conditions as BP, E1 and E2, respectively. This Glucose reduction strategy and its derivatives are used in many solvers. For example, Lingeling dynamically selects either Glucose-based or classical activity-based strategies [4]. If the standard deviation of the LBDs of learnt clauses is too small or too large, then, the activity-based strategy is selected. MapleCOMSPS uses the reduction strategy combining both. This keeps clauses whose LBDs ≤6≤6, while others are managed by the activity-based strategy. In addition, clauses with LBDs of 4 to 6, which have not been used for a while, are managed by the activity-based strategy [8]. In Sect. 4, we show some issues in the Glucosereduction strategy. | |
3 Experimental Evaluation of LBD
|
LBD is a well-known criterion for identifying learnt clauses that are likely to be used frequently. In this section, we present the experimental evidence of LBD usefulness in a wide variety of instances. From the results, we design our reduction strategy based on LBD. Throughout the paper, we use 755 instances, excluding duplicates, from the application instances used in competitions over the last 3 years,3 as benchmark instances. All experiments were conducted on a Core i5 (1.4 GHz) with 4 GB memory. We set the timeout for solvers to 5,000 CPU seconds. We used our SAT solver GlueMiniSat 2.2.10. The main difference with Glucose is that GlueMiniSat uses the lightweight in-processing techniques [7]. Detailed results and the source code of GlueMiniSat can be found at http://www.kki.yamanashi.ac.jp/~nabesima/sat2017/. 译文:LBD是一个众所周知的标准,用来识别可能经常使用的已学习的从句。在本节中,我们将在各种各样的实例中展示LBD有用性的实验证据. |
|
|
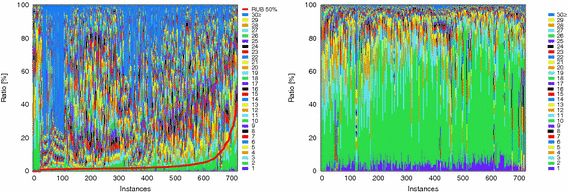
Fig. 1. Distribution of LBDs of learnt clauses (left) and used LBDs (right). Instances are sorted by ascending order of CPU time. (Color figure online) 左图: (1)学习子句(求解过程中始终不删除,得到的全部学习子句)的LBD分布情况; (2)求解时间少的样例lbd小的学习子句(靠左的0-20部分)绿色的比例较高; (3)求解时间长的样例lbd小的学习子句(靠右的600-700部分)同样出现绿色比例较高。 右图: (1)所有的学习子句中被使用用于BCP的学习子句的LBD分布情况; (2)总的看来全体样例蓝绿色比例都较高。说明:小lbd(值为1-2)的学习子句被经常使用于BCP传播,即propagations or conflicts are caused by LBD 2 clauses。
|
|
| Figure 1 shows the distributions of LBDs of learnt clauses (left) and used LBDs (right) for each instance. In this experiment, learnt clause reduction was disabled; that is, the solver held every learnt clause. The numbers in the legend represent LBDs. The red line in the left graph will be explained in Sect. 4. Each stacked bar in the left graph represents the ratio distribution of LBDs, for all learnt clauses, after the solver stopped (e.g., if there are 10% learnt clauses whose LBDs are 2, the height of LBD 2 bar is 10%). In the right graph, each bar represents the ratio distribution of clause LBDs, which caused propagations or conflicts (e.g., if 50% of propagations or conflicts are caused by LBD 2 clauses, then the height of the LBD 2 bar is 50%). | |
|
The left graph shows that learnt clauses have various LBDs. In easy instances at the left end of the graph, small LBDs are somewhat dominant; however, the other instances have many different LBDs. On the other hand, from the right graph, it is clear that most propagations or conflicts are caused by small LBD clauses. This strongly supports the identification power of the LBD criterion. 译文:左图显示,所学习的从句具有不同的LBDs。在图表左侧的简单例子中,较小的lbd占主导地位;然而,其他实例有许多不同的lbd。另一方面,从右图中可以看出,大部分传播或冲突都是由小的LBD条款引起的。这有力地支持了LBD准则的识别能力。 |
|
4 Issues of Glucose Reduction Strategy
 |
|
|
On the other hand, the interval between reductions increases exponentially. This means that the ratio of number of clauses that can be newly held, gradually approaches 0 as k increases. This is the first issue regarding BP. 译文:另一方面,还原之间的间隔呈指数增长。这意味着,随着k的增加,可以新持有的子句的数量之比逐渐接近0。这是关于BP的第一个问题。 |
|
|
The red line in the left graph of Fig. 1 represents the upper bound of the number of clauses held when following BP. In most instances, the number of glue clauses exceeds the bound.译文:在大多数情况下,glue子句的数量超过了限制。
Glue clauses are never removed by E1. As a result, the solver can not hold new non-glue clauses at all, as long as it follows BP and E1.译文:Glue子句不会被E1删除。因此,解算器根本不能保留新的无胶条款,只要遵循BP和E1。
Even with a high residual ratio, the increment becomes a constant by (3); therefore, the issue essentially remains. Moreover, by keeping only glue clauses (E1) is sometimes insufficient to cover most propagations and conflicts.译文:即使残差率很高,增量也变为常数(3);因此,这个问题基本上仍然存在。此外,仅保留glue子句(E1)有时不足以覆盖大多数传播和冲突。
In the right graph of Fig. 1, the purple and green bars at the bottom represent the ratio of LBD 1 and 2. This indicates that the appropriate upper bound of LBD depends on a given instance. These are the second issue regarding E1.译文:底部的紫色和绿色条代表LBD 1和2的比例。这表明LBD的适当上限取决于给定的实例。 |
|
| In Glucose, clauses used after the last reduction and with LBD less than, or equal to 30, are not removed (E2). The right graph in Fig. 1 shows that this threshold can cover most propagations and conflicts; however, it may be overly retentive. This is the third issue related to E2.译文:在葡萄糖中,在最后一次还原后使用的、LBD小于或等于30的子句不被移除(E2)。从图1的右图可以看出,这个阈值可以覆盖大部分的传播和冲突;然而,它可能会过度保留。这是与E2有关的第三个问题。 | |
| In the next section, we propose a new concise reduction strategy to address the above mentioned concerns. | |
|
阅读小结: (1)子句规模的增加幅度在不断减少直至不在增加; (2)新的非胶水子句可能不在能加入进来(由于规模的控制,加入后很快就被删除); (3)仅保留glue子句(E1)有时不足以覆盖大多数传播和冲突; (4)glucose使用的策略,在core和iter2集合中管理的“LBD小于或等于30的子句”不被移除,这会造成过度保留; (5)the appropriate upper bound of LBD depends on a given instance.LBD的适当上界取决于给定的实例。 |
5 Coverage-Based Reduction Strategy
|
Most propagations and conflicts are caused by small LBD clauses. We propose a reduction strategy to dynamically compute the upper bound of LBD in order to cover most propagations and conflicts. 阅读备注:作者提出了小的lBD子句在传播中的使用率的概念-覆盖大多数传播和冲突; |
|
 |
|
|
阅读注释: (1)学习子句被使用——指的是:在BCP中充当reason子句形成单元传播或导致冲突; (2)记录拥有small LBD 的学习子句被使用的次数; (3)计算得到相应的量: k阶累积出现次数——LBD为小于等于k值的的子句使用次数累加和 |
|
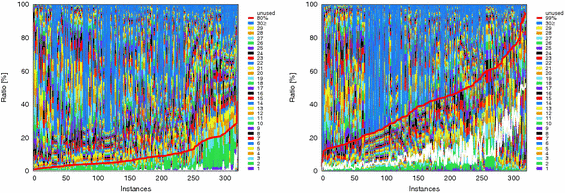
Fig. 2. Holding ratio of coverage of 80% (left) and 99% (right) for unsolved instances. Instances are sorted by ascending order of holding ratio. (Color figure online) |
|
| Next, we consider the trade-off between coverage and number of kept clauses. A high coverage requires the retention of a large number of clauses. Figure 2 exhibits the holding ratio, which is the number of maintained clauses at the termination of solver divided by the total number of learnt clauses, when we specify the coverage as 80% (left) and 99% (right). The red line represents the holding ratio and the white line denotes the ratio of unused and held clauses4. At the right end of the left graph, the red line is 30% and the white line is 10%. This means that a maximum of 30% of learnt clauses are required to cover at least 80% of uses of learnt clauses, and that a maximum of 10% of clauses are unused. The right graph at Fig. 2 shows that it is necessary to keep the majority of clauses in order to cover almost all uses, in the worst case, and that approximately half of them are not used. | |
|
阅读注释:权衡——提高覆盖率与保留大量的学习子句 (1)提高覆盖率需要保留大量学习子句;(2)保留大量学习子句时,其中很多子句子句没有被使用;(3)提高覆盖率会必然提高了没有被使用的学习子句的比例; |
|
|
In order to suppress the number of held clauses while covering propagations and conflicts as much as possible, we classify learnt clauses into three types: core, support, and other clauses. 译文:为了在尽可能覆盖传播和冲突的同时抑制持有子句的数量,我们将学习到的子句分为三类:核心子句、支持子句和其他子句。 We make core clauses cover most uses (e.g. 80%), and support clauses cover the remains (e.g. 99%). We give support clauses a short lifetime since their number can be enormous; we give core clauses a longer lifetime, where the lifetime n of clause C means that C will be removed when it is unused while n reductions occur. We provide the formal definition of core, support, and other clauses. Let C be a clause, and c core and c supp be the specified coverage of core and support clauses (c core ≤c supp c core ≤c supp ), respectively. |
|
 |
|
6 Experimental Results
 |
|
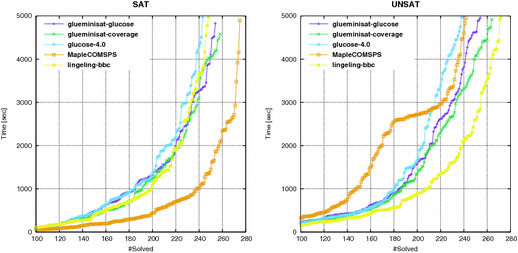
Fig. 3. Time to solve instances |
|
|
阅读注释: 单纯从Fig.3中来看 (1)lingeling求解器对SAT问题求解能离高;MapleCOMSPS求解器对USA问题求解能力较强; (2)新提出的覆盖率的概念用于改进glucose求解器,在原有的基础上有提高,但没有超过上述两个求解器;
|
|
| Table 1 shows the number of instances solved by each solver and Fig. 3 is the cactus plot of these results. GlueMiniSat, with the Glucose schema, has better performance than Glucose. The coverage schema can further improve performance for both SAT and UNSAT instances. MapleCOMSPS and Lingeling show the superior results for SAT and UNSAT instances, respectively. GlueMiniSat, with the coverage schema, shows that the well-balanced result and total number of solved instances are comparable with these state of the art solvers. | |
 |
|
|
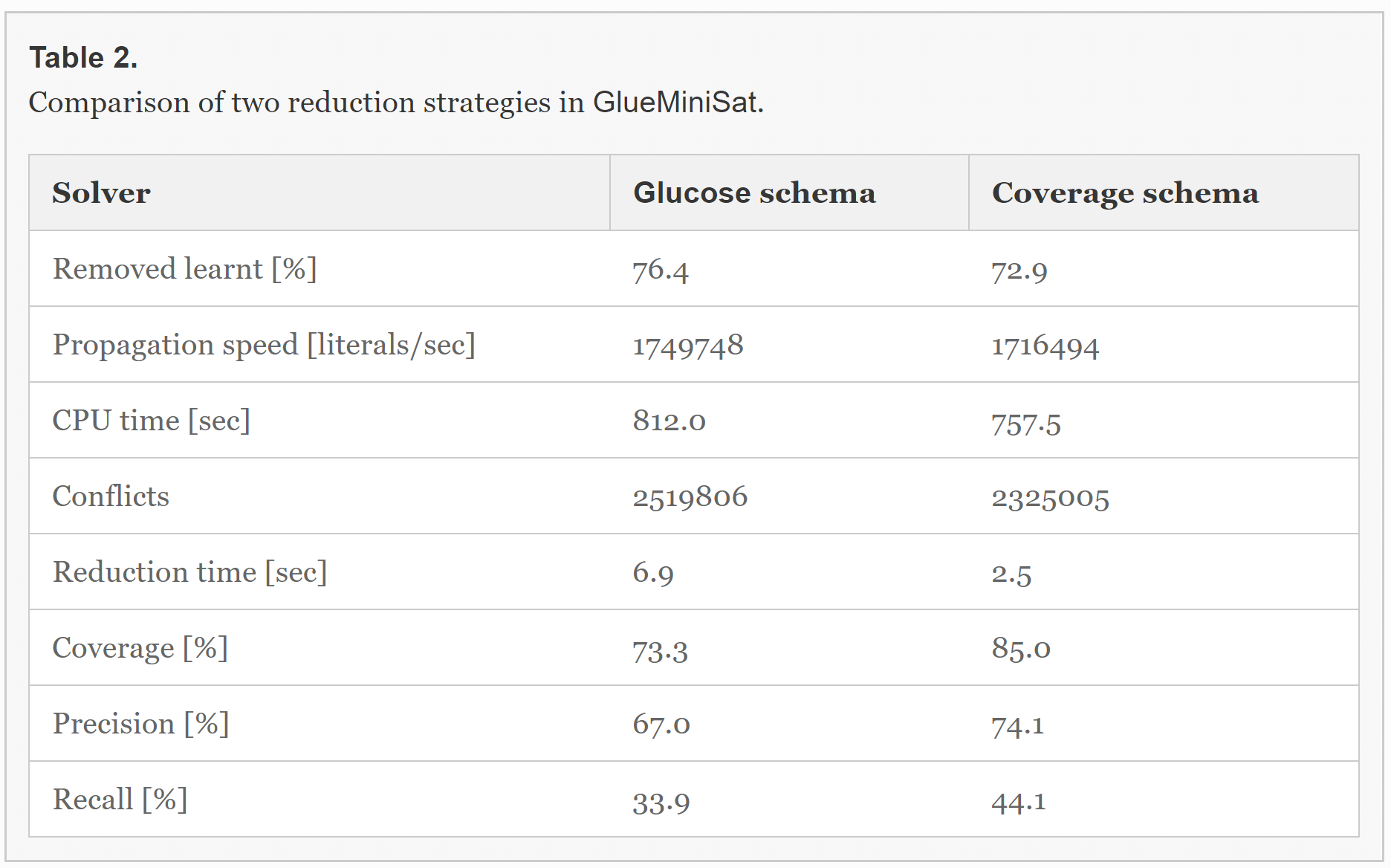
Table 2 is the comparison of statistics between Glucose and coverage schema. Each value in the first 5 lines denotes the average for commonly solved 494 instances of both strategies. The first two lines in the table show that the Glucose schema reduces more clauses than the coverage schema; hence, the Glucose schema shows higher propagation speed. On the other hand, the coverage schema requires shorter CPU time and less conflicts in order to solve instances. It shows that the coverage schema can hold more useful clauses than the Glucose schema.译文:结果表明,覆盖模式比葡萄糖模式包含更多有用的子句。
In the coverage schema, the reduction of learnt clauses is slightly faster since the computational cost is O(n) while the Glucose schema is O(nlogn)。 |
|
|
The last three lines in Table 2 are the results of different experiments, in which each solver does not actually remove learnt clauses to calculate coverage, precision, and recall. Each value indicates the average for commonly solved 406 instances. Coverage in Table 2 is the ratio of the number of used clauses that are caused only by maintained clauses to the total number of used clauses that are caused by all clauses. Precision is the ratio of used and held clauses to held clauses; recall is the ratio of used and held clauses to used clauses. In the coverage schema, these values have improved. This indicates that the coverage schema can better identify which clauses will be used. 译文:表2中的最后三行是不同实验的结果,在这些实验中,每个求解器并没有实际删除已学习的子句来计算覆盖率、精度和召回。 |
|
|
阅读注释: (1)2018年竞赛的求解器已经出现直接记录每个学习子句使用次数,并将使用次数衡量是否保留学习子句的依据。 (2)针对性的确定哪些学习子句应当被保留(不仅依据LBD值和已知的使用次数)?——样例的结构挖掘以及求解过程的跨区域连接(cross gule)学习子句保留或许是一个方向. |
7 Conclusion
| We have shown that LBD can identify which clauses will be used, and proposed a concise and lightweight coverage-based reduction strategy, which provides an appropriate LBD threshold in order to cover most propagations and conflicts. The experimental results show that the coverage schema can effectively hold clauses to be used. Many solvers use LBD as an evaluation criterion for learnt clauses. Our approach can be applicable to such solvers. | |
| 译文:一个简洁和轻量级的基于覆盖的减少策略. |
References
|
|

