

Learning Rate Based Branching Heuristic for SAT Solvers
Liang J.H., Ganesh V., Poupart P., Czarnecki K. (2016) Learning Rate Based Branching Heuristic for SAT Solvers. In: Creignou N., Le Berre D. (eds) Theory and Applications of Satisfiability Testing – SAT 2016. SAT 2016. Lecture Notes in Computer Science, vol 9710. Springer, Cham
Abstract
|
In this paper, we propose a framework for viewing solver branching heuristics as optimization algorithms where the objective is to maximize the learning rate, defined as the propensity for variables to generate learnt clauses. By viewing online variable selection in SAT solvers as an optimization problem, we can leverage a wide variety of optimization algorithms, especially from machine learning, to design effective branching heuristics. 译文:通过将SAT求解器中的在线变量选择视为一个优化问题,我们可以利用各种优化算法,特别是机器学习,来设计有效的分支启发式。 In particular, we model the variable selection optimization problem as an online multi-armed bandit, a special-case of reinforcement learning, to learn branching variables such that the learning rate of the solver is maximized. We develop a branching heuristic that we call learning rate branching or LRB, based on a well-known multi-armed bandit algorithm called exponential recency weighted average and implement it as part of MiniSat and CryptoMiniSat.
LRB与multi-armed bandit algorithm的关系:使用指数移动权值平均算法实现LRB。
We upgrade the LRB technique with two additional novel ideas to improve the learning rate by accounting for reason side rate and exploiting locality. The resulting LRB branching heuristic is shown to be faster than the VSIDS and conflict history-based (CHB) branching heuristics on 1975 application and hard combinatorial instances from 2009 to 2014 SAT Competitions. We also show that CryptoMiniSat with LRB solves more instances than the one with VSIDS. These experiments show that LRB improves on state-of-the-art. |
|
Keywords
Learning Rate Slot Machine Implication Graph CDCL Solver Clause Learning
主要内容: learning rate branching (LRB) heuristic
| 1.变元的学习率定义为:BCP传播与回溯阶段,变元被赋值到变元赋值被取消这段时间中,生成一定数量的学习子句,在这些学习子句中,与该变元相关的子句个数占总的子句个数的比率。 |
|
2.变元的学习率活跃度增加公式1:
r =
That is, variables with high LR are the ones that frequently appear in the generated learnt clause and/or the conflict side of the implication graph.
|
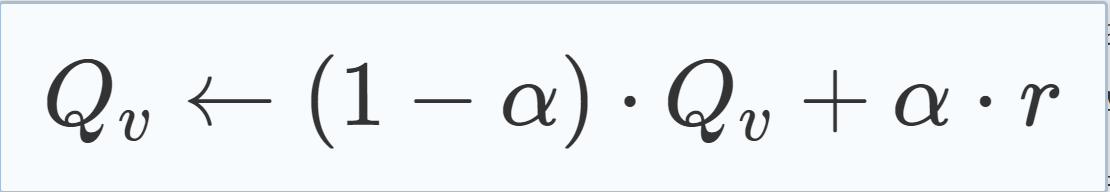 |
|
3.Extension: Reason Side Rate (RSR) Let A(v, I) be the number of learnt clauses which v reasons in generating in interval I and let L(I) be the number of learnt clauses generated in interval I. The reason side rate (RSR) of variable v at interval I is defined as
考虑变元处于reason side 一侧时的贡献,则改进的公式: |
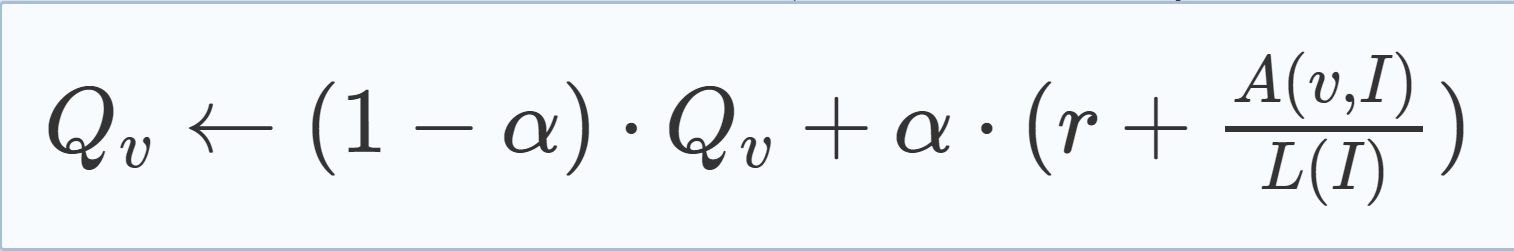 |
|
4.Extension: Locality
理由论述如下: |
| Recent research shows that VSIDS exhibits locality [20], defined with respect to the community structure of the input CNF instance [1, 20, 25]. Intuitively, if the solver is currently working within a community, it is best to continue focusing on the same community rather than exploring another. We hypothesize that high LR variables also exhibit locality, that is, the branching heuristic can achieve higher LR by restricting exploration. |
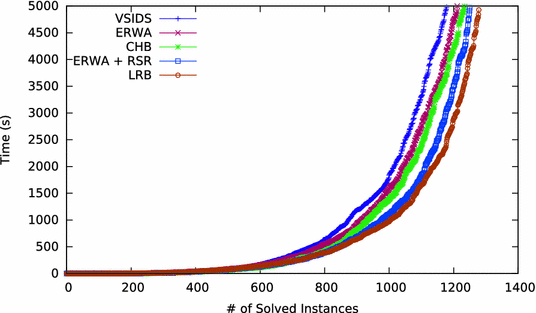
| 5.VSIDS、CHB、ERWA(只考虑冲突侧)、ERWA+RSR(考虑了reason侧)、LRB(综合都考虑了)的求解器求解问题对比:说明了改进效果。 |
 |
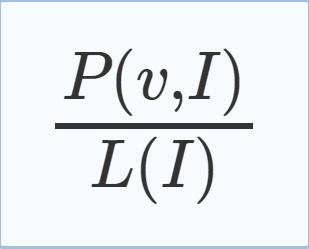
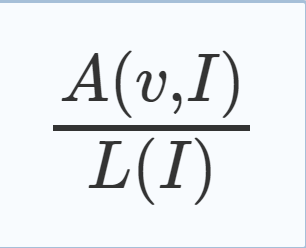

1 Introduction
| branching heuristic (and its variants) | 文献 |
| VSIDS 被提出在2001年 | 【24】 |
| VSIDS的改进系列版本 | [7, 15, 16, 28] |
| conflict analysis techniques | 【23】 |
| the conflict history-based (CHB) branching heuristic 2016年 | [19] |
| learning rate branching (LRB) 2016年 | |
| phase-saving | 【26】 |
| Exponential Recency Weighted Average (ERWA) | 【31】 |
| the decay reinforcement model [13,32] | 【13】【32】 |
S本文提到SAT的应用:
| Modern Boolean SAT solvers are a critical component of many innovative techniques in security, software engineering, hardware verification, and AI such as solver-based automated testing with symbolic execution [9], bounded model checking [11] for software and hardware verification, and planning in AI [27] respectively. |
对branching heuchrishtics思考视角:
| In this paper, we introduce a general principle for designing branching heuristics wherein online variable selection in SAT solvers is viewed as an optimization problem. |
| The objective to be maximized is called the learning rate (LR), a numerical characterization of a variable’s propensity to generate learnt clauses. The goal of the branching heuristic, given this perspective, is to select branching variables that will maximize the cumulative LR during the run of the solver. |
| Intuitively, achieving a perfect LR of 1 implies the assigned variable is responsible for every learnt clause generated during its lifetime on the assignment trail. |
创新点
Contributions
|
2 Preliminaries
|
2.1 Simple Average and Exponential Moving Average |
|
|
2.2 Multi-Armed Bandit (MAB) |
|
|
2.3 Clause Learning |
|
|
2.4 The VSIDS Branching Heuristic |
|
3. Learning Rate 定义
|
For example, suppose variable v is assigned by the branching heuristic after 100 learnt clauses are produced. It par- |
|
|
The exact LR of a variable is usually unknown during branching. In the previous example, variable v was picked by the branching heuristic after 100 learnt clauses are produced, but the LR is not known until after the 105-th learnt clause is produced. Therefore optimizing LR involves a degree of uncertainty, which makes the problem well-suited for learning algorithms. In addition, the LR of a variable changes over time due to modifications to the learnt clause database, stored phases, and assignment trail. As such, estimating LR requires nonstationary algorithms to deal with changes in the underlying environment. |
|
4. Abstracting Online Variable Selection as a Multi-Armed Bandit (MAB) Problem
5.
|
将一个比较绕的问题分四步讲解的非常明了: 5.1 Exponential Recency Weighted Average (ERWA) —— 给出Algorithm 1. 5.2 Extension: Reason Side Rate (RSR) —— 给出Algorithm 2. 5.3 Extension: Locality —— the decay reinforcement model [13,32]在此处的应用. 5.4 Putting it all Together to Obtain the Learning Rate Branching (LRB) Heuristic
|
|
|
|
|
|
|
|
|
|
|



References
-
1.Ansótegui, C., Giráldez-Cru, J., Levy, J.: The community structure of SAT formulas. In: Cimatti, A., Sebastiani, R. (eds.) SAT 2012. LNCS, vol. 7317, pp. 410–423. Springer, Heidelberg (2012)CrossRefGoogle Scholar
-
2.Audemard, G., Simon, L.: Predicting learnt clauses quality in modern SAT solvers. In: Proceedings of the 21st International Jont Conference on Artifical Intelligence, IJCAI 2009, pp. 399–404. Morgan Kaufmann Publishers Inc., San Francisco (2009)Google Scholar
-
3.Audemard, G., Simon, L.: Refining restarts strategies for SAT and UNSAT. In: Milano, M. (ed.) CP 2012. LNCS, vol. 7514, pp. 118–126. Springer, Heidelberg (2012)CrossRefGoogle Scholar
-
4.Audemard, G., Simon, L.: Glucose 2.3 in the SAT 2013 Competition. In: Proceedings of SAT Competition 2013, pp. 42–43 (2013)Google Scholar
-
5.Biere, A.: Adaptive restart strategies for conflict driven SAT solvers. In: Kleine Büning, H., Zhao, X. (eds.) SAT 2008. LNCS, vol. 4996, pp. 28–33. Springer, Heidelberg (2008)CrossRefGoogle Scholar
-
6.Biere, A.: Lingeling, Plingeling, PicoSAT and PrecoSAT at SAT Race 2010. FMV Report Series Technical report 10(1) (2010)Google Scholar
-
7.Biere, A., Fröhlich, A.: Evaluating CDCL variable scoring schemes. In: Heule, M., Weaver, S. (eds.) SAT 2015. LNCS, vol. 9340, pp. 405–422. Springer, Heidelberg (2015). doi: 10.1007/978-3-319-24318-4_29CrossRefGoogle Scholar
-
8.Brown, R.G.: Exponential smoothing for predicting demand. Oper. Res. 5, 145–145 (1957)CrossRefGoogle Scholar
-
9.Cadar, C., Ganesh, V., Pawlowski, P.M., Dill, D.L., Engler, D.R.: EXE: automatically generating inputs of death. In: Proceedings of the 13th ACM Conference on Computer and Communications Security, CCS 2006, pp. 322–335. ACM, New York (2006)Google Scholar
-
10.Carvalho, E., Marques-Silva, J.P.: Using rewarding mechanisms for improving branching heuristics. In: Proceedings of the Seventh International Conference on Theory and Applications of Satisfiability Testing (2004)Google Scholar
-
11.Clarke, E., Biere, A., Raimi, R., Zhu, Y.: Bounded model checking using satisfiability solving. Form. Methods Syst. Des. 19(1), 7–34 (2001)CrossRefzbMATHGoogle Scholar
-
12.Eén, N., Sörensson, N.: An extensible SAT-solver. In: Giunchiglia, E., Tacchella, A. (eds.) SAT 2003. LNCS, vol. 2919, pp. 502–518. Springer, Heidelberg (2004)CrossRefGoogle Scholar
-
13.Erev, I., Roth, A.E.: Predicting how people play games: reinforcement learning in experimental games with unique, mixed strategy equilibria. Am. Econ. Rev. 88(4), 848–881 (1998)Google Scholar
-
14.Fröhlich, A., Biere, A., Wintersteiger, C., Hamadi, Y.: Stochastic local search for satisfiability modulo theories. In: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI 2015, pp. 1136–1143. AAAI Press (2015)Google Scholar
-
15.Gershman, R., Strichman, O.: HaifaSat: a new robust SAT solver. In: Ur, S., Bin, E., Wolfsthal, Y. (eds.) HVC 2005. LNCS, vol. 3875, pp. 76–89. Springer, Heidelberg (2006)CrossRefGoogle Scholar
-
16.Goldberg, E., Novikov, Y.: BerkMin: a fast and robust sat-solver. Discrete Appl. Math. 155(12), 1549–1561 (2007)MathSciNetCrossRefzbMATHGoogle Scholar
-
17.Jeroslow, R.G., Wang, J.: Solving propositional satisfiability problems. Ann. Math. Artif. Intell. 1(1–4), 167–187 (1990)CrossRefzbMATHGoogle Scholar
-
18.Lagoudakis, M.G., Littman, M.L.: Learning to select branching rules in the DPLL procedure for satisfiability. Electron. Notes Discrete Math. 9, 344–359 (2001)CrossRefzbMATHGoogle Scholar
-
19.Liang, J.H., Ganesh, V., Poupart, P., Czarnecki, K.: Exponential recency weighted average branching heuristic for SAT solvers. In: Proceedings of AAAI 2016 (2016)Google Scholar
-
20.Liang, J.H., Ganesh, V., Zulkoski, E., Zaman, A., Czarnecki, K.: Understanding VSIDS branching heuristics in conflict-driven clause-learning SAT solvers. In: Liang, J.H., Ganesh, V., Zulkoski, E., Zaman, A., Czarnecki, K. (eds.) HVC 2015. LNCS, vol. 9434, pp. 225–241. Springer, Heidelberg (2015). doi: 10.1007/978-3-319-26287-1_14CrossRefGoogle Scholar
-
21.Loth, M., Sebag, M., Hamadi, Y., Schoenauer, M.: Bandit-based search for constraint programming. In: Schulte, C. (ed.) CP 2013. LNCS, vol. 8124, pp. 464–480. Springer, Heidelberg (2013)CrossRefGoogle Scholar
-
22.Marques-Silva, J.: The impact of branching heuristics in propositional satisfiability algorithms. In: Barahona, P., Alferes, J.J. (eds.) EPIA 1999. LNCS (LNAI), vol. 1695, pp. 62–74. Springer, Heidelberg (1999)CrossRefGoogle Scholar
-
23.Marques-Silva, J.P., Sakallah, K.A.: GRASP-a new search algorithm for satisfiability. In: Proceedings of the 1996 IEEE/ACM International Conference on Computer-aided Design, ICCAD 1996, pp. 220–227. IEEE Computer Society, Washington, DC (1996)Google Scholar
-
24.Moskewicz, M.W., Madigan, C.F., Zhao, Y., Zhang, L., Malik, S.: Chaff: engineering an efficient SAT solver. In: Proceedings of the 38th Annual Design Automation Conference, DAC 2001, pp. 530–535. ACM, New York (2001)Google Scholar
-
25.Newsham, Z., Ganesh, V., Fischmeister, S., Audemard, G., Simon, L.: Impact of community structure on SAT solver performance. In: Sinz, C., Egly, U. (eds.) SAT 2014. LNCS, vol. 8561, pp. 252–268. Springer, Heidelberg (2014)Google Scholar
-
26.Pipatsrisawat, K., Darwiche, A.: A lightweight component caching scheme for satisfiability solvers. In: Marques-Silva, J., Sakallah, K.A. (eds.) SAT 2007. LNCS, vol. 4501, pp. 294–299. Springer, Heidelberg (2007)CrossRefGoogle Scholar
-
27.Rintanen, J.: Planning and SAT. In: Biere, A., Heule, M., van Maaren, H., Walsh, T. (eds.) Handbook of Satisfiability, vol. 185, pp. 483–504. IOS Press, Amsterdam (2009)Google Scholar
-
28.Ryan, L.: Efficient Algorithms for Clause-Learning SAT Solvers. Master’s thesis, Simon Fraser University (2004)Google Scholar
-
29.Soos, M.: CryptoMiniSat v4. In: SAT Competition, p. 23 (2014)Google Scholar
-
30.Stump, A., Sutcliffe, G., Tinelli, C.: StarExec: a cross-community infrastructure for logic solving. In: Demri, S., Kapur, D., Weidenbach, C. (eds.) IJCAR 2014. LNCS, vol. 8562, pp. 367–373. Springer, Heidelberg (2014)Google Scholar
-
31.Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction, vol. 1. MIT Press Cambridge, Massachusetts (1998)Google Scholar
-
32.Yechiam, E., Busemeyer, J.R.: Comparison of basic assumptions embedded in learning models for experience-based decision making. Psychon. Bull. Rev. 12(3), 387–402 (2005)CrossRefGoogle Scholar
-
33.Zhang, L., Madigan, C.F., Moskewicz, M.H., Malik, S.: Efficient conflict driven learning in a boolean satisfiability solver. In: Proceedings of the 2001 IEEE/ACM International Conference on Computer-aided Design, ICCAD 2001, pp. 279–285. IEEE Press, Piscataway (2001)Google Scholar
