

摘要:
针对命题逻辑公式求解过程中难以有效评估学习子句是否有利于后续搜索的问题,提出了一种基于学习子句趋势强度的评估算法。该算法首先通过分析学习子句在生存期内参与冲突分析的时间分布特征,将随机、离散的时间分布转换为连续的累积趋势强度;然后在删除周期达到时,通过设定趋势强度阈值删除在后续搜索过程中“不大可能”被使用的子句,保留“可能”被使用的子句;最后采用2015年、2016年SAT问题国际竞赛实例,将该算法与经典的活跃度评估算法和文字块距离(LBD)评估算法进行对比。实验结果表明,趋势强度评估算法在效率上明显优于活跃度评估算法,且求解的实例更多,同时与LBD算法基本持平。
基本步骤:
(1)通过分析学习子句在生存期内参与冲突分析的时间分布特征;
(2)将随机、离散的时间分布转换为连续的累积趋势强度;
(3)然后在删除周期达到时,通过设定趋势强度阈值删除在后续搜索过程中“不大可能”被使用的子句,保留“可能”被使用的子句;
1.引言
当SAT求解过程发生冲突时,通过冲突分析可以得到等价于当前冲突空间的子句,称其为学习子句。学习子句是逻辑推理得到的约束子句,将其放入原始公式中不会改变问题的逻辑属性。然而,受计算机内存条件、CPU运行速度的限制,演绎结果无限制地增长将导致内存溢出、搜索效率降低。因此,有必要对学习子句进行甄别以决定是保留还是删除。“好”的学习子句无论是对于可满足公式的求解,还是不可满足公式的判定都具有至关重要的加速作用。但无论从理论还是实验的角度,都很难评估学习子句的“好坏”,即难以有效评估学习子句与后续搜索的相关性。
本文通过分析删除周期点上的学习子句的来源分布,提出一种不同于已有评估算法的动态趋势评估算法。与经典的活跃度(VSIDS)和文字块距离(Literals Blocks Distance, LBD)评估方法相比,本文所提算法显著优于活跃度方法,与LBD方法基本持平。
2.相关研究
学习子句与原始公式中的子句的性质,都可以用于后续搜索。由于SAT问题的复杂性,学习子句对于后续搜索是否具有决定性作用,在生成学习子句时是未知的。现有的评估方法主要分为静态评估和动态评估两类。静态评估通常与搜索冲突无关。动态评估体现了学习子句与搜索过程的相关性,是目前主流的评估方法。
学习子句静态评估方法:
(1)文献[3]提出了ith-order方法,该方法删除了文字个数超过i 的子句。
(2)在GRASP[4]方法中,设定了一个临界值k,子句中文字数小于或等于k的学习子句或大于k 的单元子句都会被保留,其余学习子句则尽可能地被删除。
(3)iRelevance-bounded算法[5]只保留未赋值文字数不超过i且蕴涵有其他文字的子句。
(4)Chaff求解器[6]提出了一种懒散的子句删除策略,当学习子句中未被赋值的文字数首次超过N 个(一般为100~200)时,该子句将被打上标记,并在清理内存时被统一删除。
(5)Berkmin求解器[7]认为越晚被推导出的学习子句越具价值,因为从原问题中推导出这些子句耗费了更长的时间。Berkmin求解器使用队列(先进先出结构)来维护学习子句,每次删除总学习子句队列中前1/16的子句,剩下15/16子句中超过42个文字的子句也会被删除;同时,最后一次冲突得到的子句和活跃的子句均不受这一限制。
(6)文献[12]提出了有界大小随机策略(Size-Bounded Randomized,SBR),保留短子句(文字数小于k)并随机删除文字数大于k 的子句,实验表明,随机保留部分较长的子句对于部分SAT问题的推导证明是有效的。
学习子句的动态评估方法
(1)MiniSat求解器[8]为每个学习子句设置活跃度,当学习子句产生或被用于冲突分析时,增加其活跃度,周期性删除文字数大于2且排在队列前1/2或者活跃度小于临界值的子句。
(2)Audemard等[9]发现子句中某些文字是在同一决策层被赋值的,通常在其他搜索中也有很大可能性在同一决策层被赋值。基于这一思想,他们提出了文字块距离评估方法,该方法统计子句中文字所在的决策层个数LBD,并周期性删除超过预设阈值的子句。
(3)文献[10]提出了一种基于相位保存的学习子句相关度评估算法(Progress Saving basedquality Measure,PSM),通过动态比较子句中已赋值文字比例与移动汉明距离的大小,来决定子句是否应该被冻结、激活或删除。
(4)文献[11]提出了回溯层活跃度评估算法(Back Track Level,BTL)。BTL记录了学习子句中回溯层的大小,通过实验发现BTL小于3的子句包含了更多搜索树顶部中的文字,且被使用的频率远大于其他子句。因此,BTL越小的子句应具有更大相关度并被保存下来。
(5)文献[13]提出了一种基于群落结构检测学习子句关联度的方法,通过构造2群落得到的学习子句能够较好地提升求解性能。
(6)文献[14]综合了多种子句评估方式,提出了折中度(Degree of Compromise)概念,通过比较折中度,删除受支配的学习子句。
(7)文献2017李初民
(8)常文静
3.删除周期点上的学习子句来源分布
学习子句的“好坏”依赖于不同的评估方法,动态活跃度评估和LBD评估是目前最为流行的两种评估方式。
前者为每个子句设置一个活跃度计算器,子句活跃度为s′=s+(1/f)n,其中,f 为衰减因子,0<f<1;n 为总冲突次数。子句活跃度与总冲突次数有关,与子句中文字所在决策层无关。
而LBD评估方式正好与活跃度相反,其与决策层按文字划分的个数有关,与总冲突次数的关系不大。例如给定子句C1和C2,用A(C)和L(C)分别表示其活跃度和LBD,有A(C1)=
1000,A(C2)=2000,L(C1)=3,L(C2)=5。对于Minisat而言,C2的活跃度更大,显然比C1好;而对于Glucose而言,C1仅被划分为3块,少于L(C2),因此C1比C2好。
不同的评价方式也使得不同的学习子句被删除,且使得搜索过程出现明显差异。但无论是活跃度评估还是LBD评估,都采用了比较激进的删除策略,使得学习子句的利用效率不高。
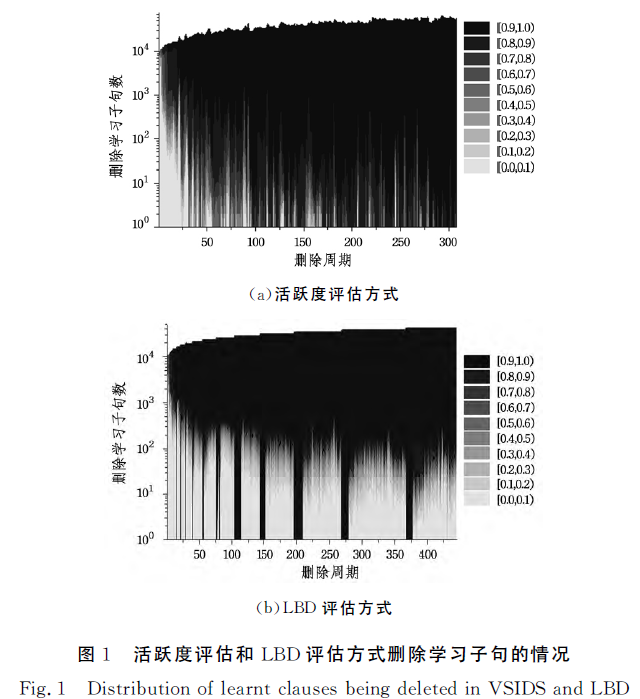 |
图1所示为活跃度评估和LBD评估方式删除的学习子句的来源分布,图1(a)和图1(b)分别为活跃度评估和LBD评估测试50bits_13.dimacs.cnf(SAT Race 2015)实例的情况,其中横坐标为删除周期k,纵坐标为相应删除的学习子句数,不同颜色表示第k次删除的学习子句的来源d,d 越大(颜
色越深)表示越晚产生的学习子句的占比越大。可以明显看
出,活跃度评估方式和LBD评估方式都删除了大量新学习到
的子句,且保留的前期学习到的子句越来越少。相较活跃度
评估方式,LBD删除学习子句的方式相对谨慎,保留的前期
学习子句相对较多。
