MongoDB复制集概念架构浅析
2019-01-05 15:37 狂澜与玉昆0950 阅读(537) 评论(0) 收藏 举报一、复制集的作用
(1) 高可用
防止设备(服务器、网络)故障。
提供自动failover 功能。
技术来保证数
(2) 灾难恢复
当发生故障时,可以从其他节点恢复。
(3) 功能隔离
用于分析、报表,数据挖掘,系统任务等。
用于备份。
二、复制集架构及角色
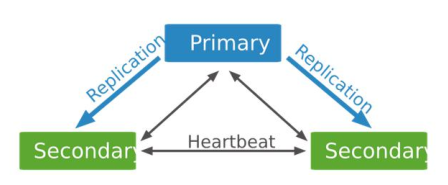
MongoDB复制集由一组mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点。
(一)主节点
接收所有来自客户端的写操作,MongoDB Driver(客户端)的所有数据都写入Primary,Primary通过将所有数据集的变动记录到oplog中以支持复制的Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。
一个复制集只能有一个主节点。由于在一个复制集中只有一个成员能够接收写操作,复制集为所有来自主节点的读提供了严格的一致性校验 。
(二)副本节点
将主节点上的oplog复制过来并应用这些操作来修改其自己的数据集以确保从节点的数据集与主节点的数据集一致。
一旦主节点不可用了,复制集就会将一个从节点选举成为新的主节点。
(三)特殊的副本节点
(1) 仲裁节点
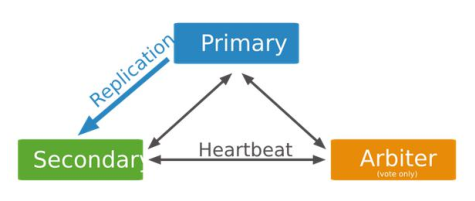
仲裁节点(投票节点)中并不包含数据集,投票节点的作用仅仅是在选举过程中参与投票。
当复制集的成员个数为偶数时,添加一个投票节点可以防止平局的出现,通过多数选票来选举出新的主节点。
由于投票节点仅提供投票功能,故无需一个专用的物理机。
(2) Priority 0节点
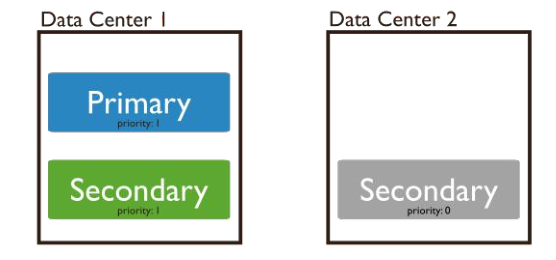
Priority0节点的选举优先级为0,不会被选举为Primary。
比如你跨机房A、B部署了一个复制集,并且想指定Primary必须在1机房,这时可以将B机房的复制集成员Priority设置为0,这样Primary就一定会是A机房的成员。
注意:如果这样部署,最好将大多数节点部署在A机房,否则网络分区时可能无法选出Primary。
(3) Hidden节点

Hidden节点不能被选为主(Priority为0),并且对Driver不可见。
因Hidden节点不会接受Driver的请求,可使用Hidden节点做一些数据备份、离线计算的任务,不会影响复制集的服务。
(4) Delayed节点
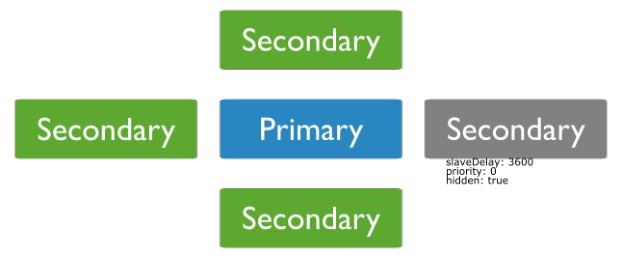
Delayed节点必须是Hidden节点,并且其数据落后与Primary一段时间(可配置,比如1个小时)。
因Delayed节点的数据比Primary落后一段时间,当错误或者无效的数据写入Primary时,可通过Delayed节点的数据来恢复到之前的时间点。
三、Oplog
(一)作用
Primary与Secondary之间通过oplog来同步数据,Primary上的写操作完成后,会向特殊的local.oplog.rs特殊集合写入一条oplog,Secondary不断的从Primary取新的oplog并应用,从而实现Replication的功能。同时由于其记录了Primary上的写操作,故还能将其用作数据恢复。可以简单的将其视作MySQL中的binlog。
(二)大小
Oplog是一个capped collection。
在64位的Linux, Solaris,FreeBSD, and Windows系统中,MongoDB默认将其大小设置为可用disk空间的5%(默认最小为1G,最大为50G)。
(三)Oplog数据结构
四、复制集数据集同步流程
MongoDB复制集里的Secondary会从Primary上同步数据,以保持副本集所有节点的数据保持一致,数据同步主要包含2个过程:
- initial sync
- replication (oplog sync)
先通过init sync同步全量数据,再通过replication不断重放Primary上的oplog同步增量数据。
(一)三个步骤
1、T1时间,从Primary同步所有数据库的数据(local除外),通过listDatabases + listCollections + cloneCollection命令组合完成,假设T2时间完成所有操作。
2、从Primary应用[T1-T2]时间段内的所有oplog,可能部分操作已经包含在步骤1,但由于oplog的幂等性,可重复应用。
3、根据Primary各集合的index设置,在Secondary上为相应集合创建index。(每个集合_id的index已在步骤1中完成)。
(二)同步场景分析
(1) 副本集初始化
初始化选出Primary后,此时Secondary上无有效数据,oplog是空的,会先进行initial sync,然后不断的应用新的oplog 。
(2) 新加入成员
因新成员上无有效数据,会先进行initial sync,然后不断的应用新的oplog。
(3) 有数据的节点加入
- 如果该节点最新的oplog时间戳,比所有节点最旧的oplog时间戳还要小,该节点将找不到同步源,会一直处于RECOVERING而不能服务;反之,如果能找到同步源,则直接进入replication阶段,不断的应用新的oplog。
- 因oplog太旧而处于RECOVERING的节点目前无法自动恢复,需人工介入处理(故设置合理的oplog大小非常重要),最简单的方式是发送resync命令,让该节点重新进行initial sync。
(三)异常处理(rollback)
- 当Primary宕机时,如果有数据未同步到Secondary;当Primary重新加入时,如果新的Primary上已经发生了写操作,则旧Primary需要回滚部分操作,以保证数据集与新的Primary一致。
- 旧Primary将回滚的数据写到单独的rollback目录下,数据库管理员可根据需要使用mongorestore进行恢复。
五、复制集选举
(一)选举情景
MongoDB复制集在以下场景会发生Primary的选举:
- 复制集的初始化。
- 复制集被reconfig。
- Secondary节点检测到Primary宕机时,会触发新Primary的选举。
- 当有Primary节点主动stepDown(主动降级为Secondary)时,也会触发新的Primary选举。
- 复制集成员心跳检测结果发生变化,比如某个节点挂了或者新增节点。
MongoDB采用投票算法进行选举!!!
Primary的选举受节点间心跳、优先级、最新的oplog时间等多种因素影响。
(二)选举相关
(1) 节点间心跳
复制集成员间默认每2s会发送一次心跳信息,如果10s未收到某个节点的心跳,则认为该节点已宕机;
如果宕机的节点为Primary,Secondary(前提是可被选为Primary)会发起新的Primary选举。
(2) 节点优先级
每个节点都倾向于投票给优先级最高的节点。
优先级默认为1,取值为0 – 1000。
优先级为0的节点不会主动发起Primary选举。
当Primary发现有优先级更高Secondary,并且该Secondary的数据落后在10s内,则Primary会主动降级,让优先级更高的Secondary有成为Primary的机会。(reconfig)
(3) Optime
拥有最新optime(最近一条oplog的时间戳)的节点才能被选为主。
(4) 网络分区
只有更大多数投票节点间保持网络连通,才有机会被选Primary;
如果Primary与大多数的节点断开连接,Primary会主动降级为Secondary。当发生网络分区时,可能在短时间内出现多个Primary。
(三)Votes属性
- 复制集成员最多50个。
- 参与Primary选举投票的成员最多7个,其他成员的
- votes属性必须设置为0,即不参与投票。
{ "_id" : <num> "host" : <hostname:port>, "votes" : 0 }
(四)副本集初始化选举primary
复制集通过replSetInitiate命令(或mongo shell的rs.initiate())进行初始化,初始化后各个成员间开始发送心跳消息,并发起Priamry选举操作,获得大多数成员投票支持的节点,会成为Primary,其余节点成为Secondary。
(五)大多数的定义
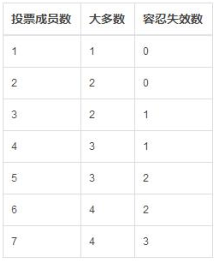
假设复制集内投票成员数量为N,则大多数为N/2 + 1,当复制集内存活成员数量不足大多数时,整个复制集将无法选举出Primary,复制集将无法提供写服务,处于只读状态。
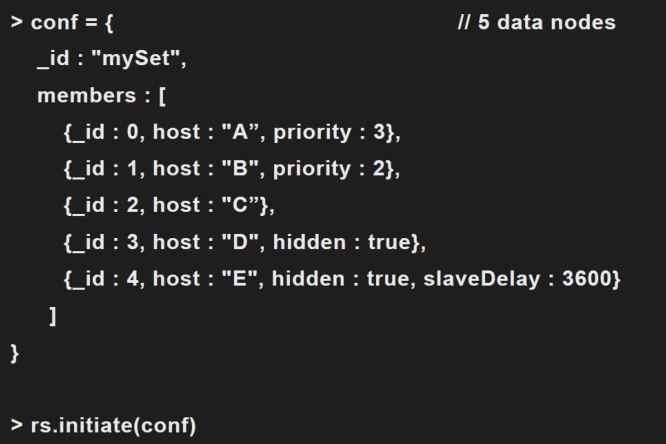
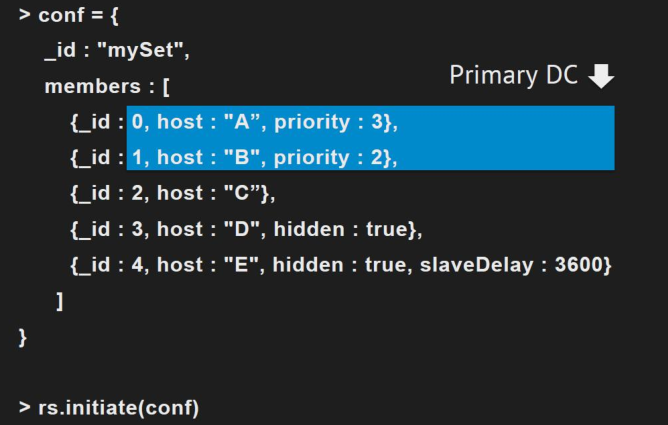
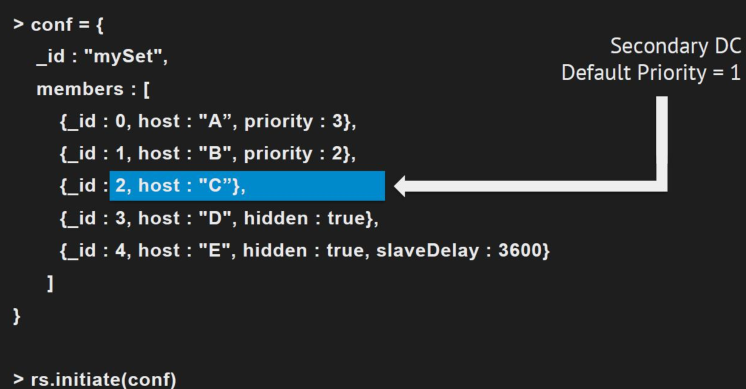
六、复制集配置
优先级(priority):用于选举主节点。
隐藏节点:用于数据分析等目的。
延迟节点:避免人为误操作。
配置案例:
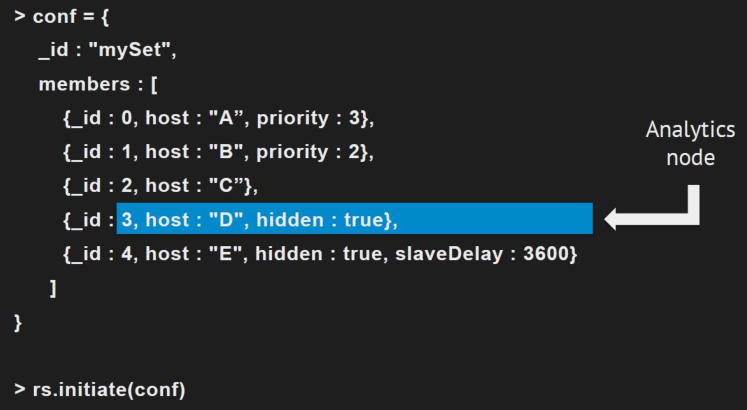
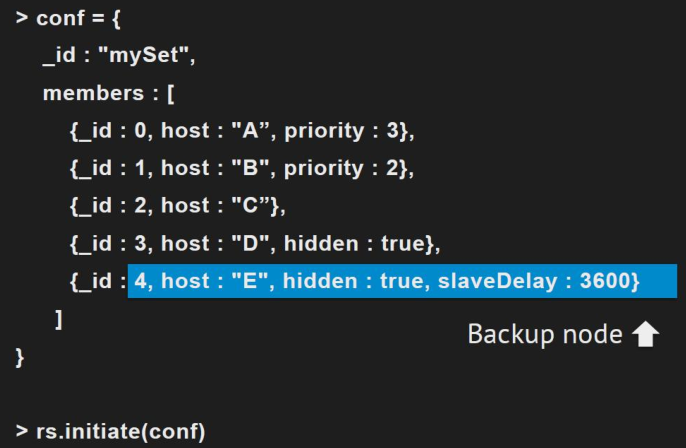
七、写关注机制Write Concern
- 用来指定MongoDB对写操作的回执行为;
- 可在connection level或者写操作level指定;
- 支持以下值:
w: 0 | 1 | n | majority | tag
j:1
wtimeout:millis
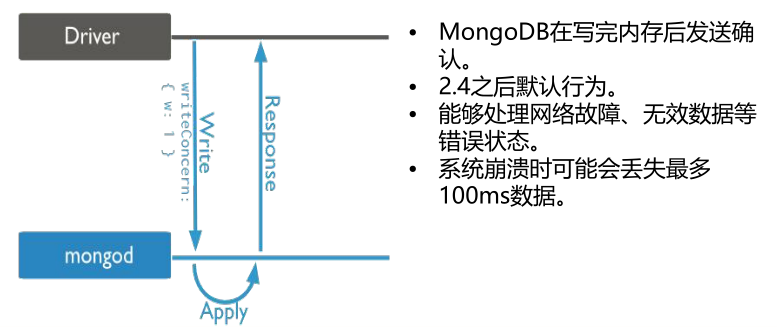
(1)w:1 Acknowledged
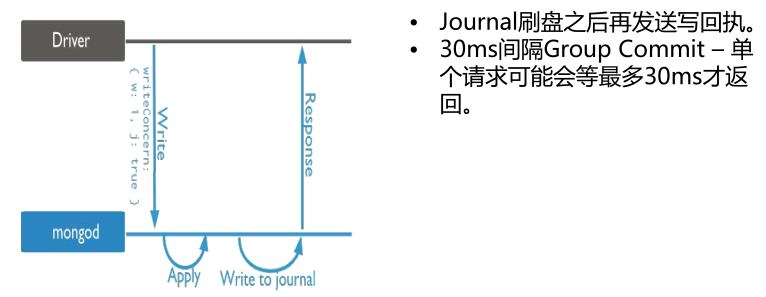
(2)j:1 Journaled
(3)w:2/n/majority Replica Acknowledged
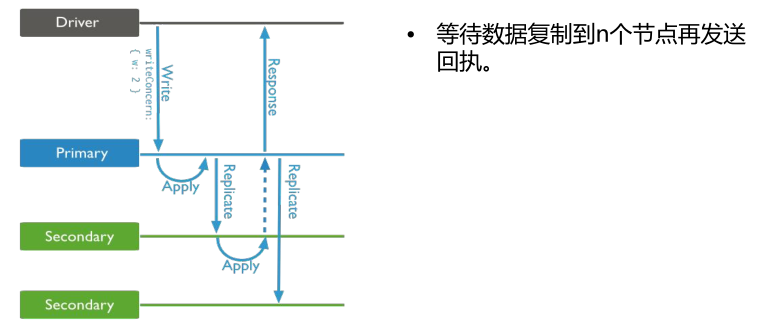
八、复制集读选项
默认情况下,复制集的所有读请求都发到Primary,Driver可通过
设置Read Preference来将读请求路由到其他的节点。
- primary:默认规则,所有读请求发到Primary。
- primaryPreferred:Primary优先,如果Primary不可达,请求Secondary。
- secondary:所有的读请求都发到secondary。
- secondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primary。
- nearest:读请求发送到最近的可达节点上(通过ping探测得出最近的节点)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号