

【数据结构】【树】
除了根节外,任何一个节点都有且仅有一个前驱
树是一种递归定义的数据结构
两个节点之间的路径是有向的,只能从上往下
树的度:各结点的度的最大值
m叉树:每个节点最多只能有m个孩子的树

度为m的树、m叉树第i层最多有 mi-1 个节点
高度为h的m叉树最多有mh-1/m-1
高度为h的m叉树至少有h个节点,高度为h,度为m的树至少有h+m-1个节点
具有n个结点的n叉树的最小高度为 [logm(n(m-1)+1)]
二叉树
二叉树是有序树,左右子树不能颠倒
每个节点最多只有两颗子树
满二叉树:(1)一棵高度为h,且含有2h-1个节点的二叉树;
(2)只有最后一层有叶子结点;
(3)不存在度为1的结点;按层序从1开始编号,节点i的做孩子为2i,右孩子为2i+1,节点i的股节点为i/2
(4)满二叉树一定是完全二叉树
完全二叉树:(1)只有最后两层可以有叶子结点;
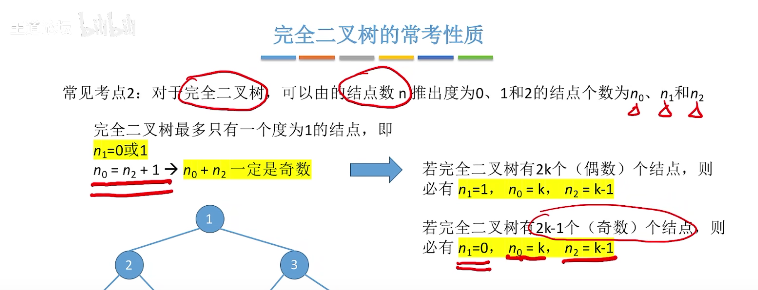
(2)最多只有一个度为1的节点;
(3)按层序从1开始编号,节点i的左孩子为2i,右孩子为2i+1,节点i的根节点为i/2;
(4)i<=[n/2]为分支节点,i>[n/2]为叶子结点;
(5)如果某结点只有一个孩子,那一定是左孩子
(6)设度为 0 结点(叶子结点)个数为 A,度为 1 的结点个数为 B,度为 2 的结点个数为 C,有A=C+1, A+B+C=总结点数
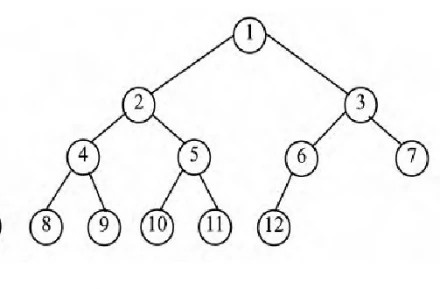
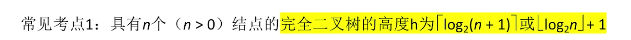
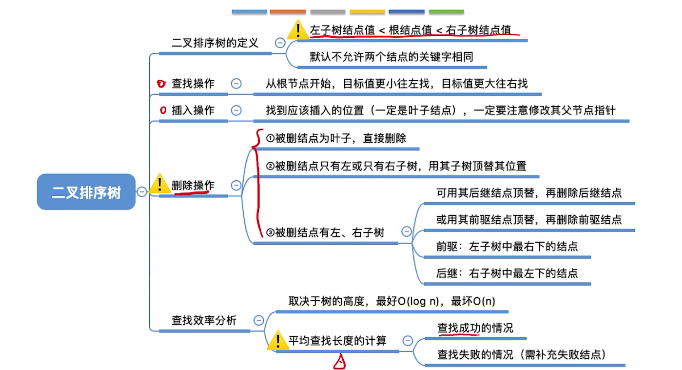
二叉排序树:(1)左子树上所有节点的关键字均小于根节点的关键字;右子树上所有节点的关键字均大于根节点的关键字
(2)左子树和柚子树又各是一棵二叉排序树
(3)二叉排序树棵用于元素的排序、搜索
平衡二叉树:(1)树上任意节点的左子树和右子树的深度之差不超过1
(2)一颗高度不高的树,搜索起来遍历的次数不会太多,有更高的搜索效率


二叉树的顺序存储中,一定要把二叉树的节点编号与完全二叉树对应起来,方便判断节点结构

//二叉树的顺序存储 #define MaxSize 100 struct TreeNode{ ElemType value;//节点中的数据元素 bool isEmpty;//节点是否为空 }; TreeNode t[MaxSize];//数组t按照从上至下,从左至右的顺序依次存储完全二叉树中的各个节点 for(int i=0;i<MazSize;i++){ t[i].isEmpty=true; //初始化时所有节点标记为空 }
链式存储
n个节点的二叉链表共有n+1个空链域(空链域可用于构造线索二叉树)
struct TreeNode{ int value;//节点中的数据元素 }; typedef struct BiTNode{ ElemType data;//节点中的数据元素 struct BiTNode *lchild,*rchild;//左右孩子指针 }BiTNode,*BiTree; //定义一颗空树 BiTree root = NULL; //插入根节点 root = (BiTree) malloc(sizeof(BiTNode)); root->data = {1}; root->lchild = NULL; root->rchild = NULL; //插入新节点 BiTNode * p = (BiTNode *) malloc(sizeof(BiTNode)); root->data = {2}; root->lchild = NULL; root->rchild = NULL; root->lchild = p;
三叉链表:方便寻找父亲节点,父亲节点只能从头开始遍历
//三叉链表 typedef struct BiTNode{ ElemType data;//节点中的数据元素 struct BiTNode *lchild,*rchild;//左右孩子指针 struct BiTNode *parent; }BiTNode,*BiTree;
二叉树的遍历
先序遍历:根左右
中序遍历:左根右
后序遍历:左右根
//先序遍历 typedef struct BiTNode{ ElemType data;//节点中的数据元素 struct BiTNode *lchild,*rchild;//左右孩子指针 }BiTNode,*BiTree; void PreOrder(BiTree T){//T指向第一个节点 if(T!=NULL){ visit(T); PreOrder(T->lchild); PreOrder(T->rchild); } } //中序遍历 typedef struct BiTNode{ ElemType data;//节点中的数据元素 struct BiTNode *lchild,*rchild;//左右孩子指针 }BiTNode,*BiTree; void PreOrder(BiTree T){ if(T!=NULL){ PreOrder(T->lchild); visit(T); PreOrder(T->rchild); } } //后序遍历 typedef struct BiTNode{ ElemType data;//节点中的数据元素 struct BiTNode *lchild,*rchild;//左右孩子指针 }BiTNode,*BiTree; void PreOrder(BiTree T){ if(T!=NULL){ PreOrder(T->lchild); PreOrder(T->rchild); visit(T); } }
求树的深度
//求树的深度(应用) int treeDepth(BiTree T){ if(T == NULL){ return 0; } else{ int l=treeDepth(T->lchild); int r=treeDepth(T->rchild); return l>r ? l+1 :r+1; } }
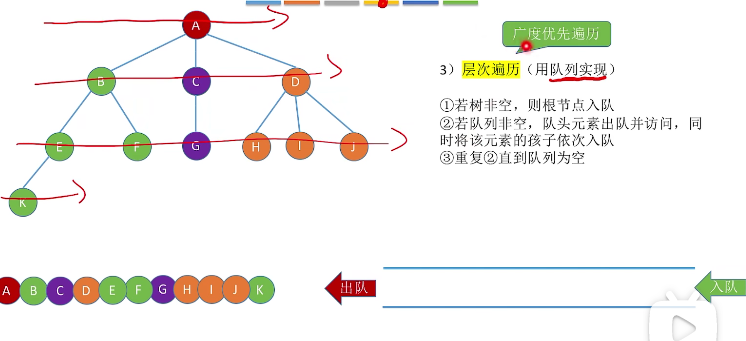
二叉树的层序遍历:初始化一个辅助队列,根节点入队,若队列非空。则队头节点出队,访问该节点,并且将其左右孩子插入对尾,一直重复这个操作直到队空
//二叉树的层序遍历 void LevelOrder(BiTree T){ LinkQueue Q; InitQueue(Q); BiTree P; EnQueue(Q,T); //让元素入队的时候入的是指针 while(!IsEmpty(Q)){ DeQueue(Q,p); visit(p); if(p->lchild=NULL) EnQueue(Q,p->lchild); if(p->rchild=NULL) EnQueue(Q,p->rchild); } }
由遍历序列构造二叉树:由前中后任意一个序列加上中序 这个组合可以确定二叉树的形状
中序线索二叉树:方便从一个指定节点出发,找到其前驱后继,方便遍历
//中序线索二叉树 typedef struct BiNode{ ElemType data; struct BiNode *lchild,*rchile; int ltag,rtag; //左右线索标志 tag==0表示指针指向孩子,tag==1表示指针是线索 }ThreadNode,*ThreadTree;
树的存储:
双亲表示法(顺序存储)设置数据域和“指针”域,“指针”域的数是双亲的序号。
二叉树的顺序存储中,一定要把二叉树的节点编号与完全二叉树对应起来,节点编号不仅反映了存储位置,也隐含了节点之间的逻辑关系(i的左孩子2i,右孩子2i+1,父节点i/2)
孩子表示法(顺序+链式)
//孩子表示法 struct CTNode{ int child;//孩子节点在数组中的位置 struct CTNode *node;//下一个孩子 }; typedef struct { ElemType data; struct CTNode *firstChild;//第一个孩子 }CTBox; typedef struct { CTBox nodes[MAX_TREE_SIZE]; int n,r; }CTree;
孩子兄弟表示法(链式)实现了树和二叉树的转换
//孩子兄弟表示法 typedef struct CSNode{ ElemType data; struct CSNode *firstChild ,*nextsibling;//第一个孩子和右兄弟指针 }CSNode,*CTree;
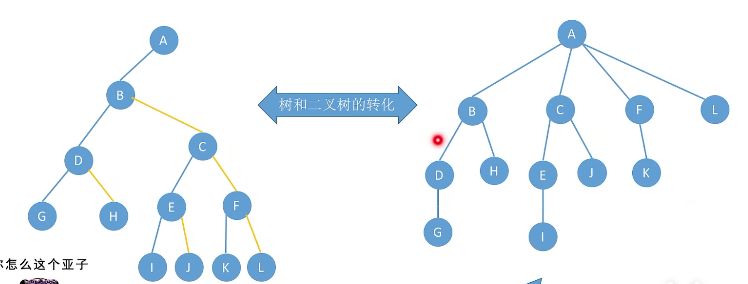
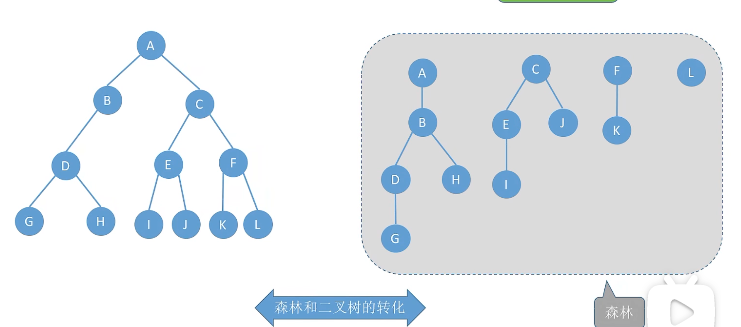
树的先根遍历:若树非空,先访问根节点,在依次对每颗子树进行先根遍历。
树的先根遍历序列与这颗树相应的二叉树的先序序列相同。
//树的先根遍历 void PreOrder(TreeNode *R){ if(R!=NULL) visit(R);//访问根节点 while(R还有下一课子树T) PreOrder(T);//先遍历下一课子树 }
后根遍历
树的先根遍历序列与这颗树相应的二叉树的中序序列相同。
//后根遍历 void PreOrder(TreeNode *R){ if(R!=NULL) while(R还有下一课子树T) PreOrder(T);//先遍历下一课子树 visit(R);//访问根节点 }
树的层次遍历(用队列实现)(广度优先遍历)
森林的先序遍历:效果等同于对一次对各个树进行先根遍历,也可以转成二叉树
森林的中序遍历:效果等同于对一次对各个树进行后根遍历,也可以转成二叉树

二叉排序(查找)树(BST)
左子树基点至<根节点值<柚子树节点值,进行中序遍历得到一个递增的有序序列
//在二叉排序树中找值为KEY的节点 typedef struct BSTNode{ int key; struct BSTNode *lchild,*rchile; }BSTNode,*BSTree; BSTNode *BST_Search(BSTree T,int key){//BSTree T是根节点的指针 while(T!==NULL&&key!=T->key){ if(ley<T->key)T=T->lchild; else T=T->rchild; } return T; } //在二叉排序树中找值为KEY的节点(递归实现) BSTNode *BST_Search(BSTree T,int key){ if(T==NULL) return NULL; if(key==T->key) return T else if(key < T->key) return BST_Search(T->lchild,key); else return BST_Search(T->rchild,key); }
二叉排序树插入
//在二叉排序树中插入值为K的节点(递归实现) int BST_Insert(BTree &T,int k){ if(T==NULL){ //原树为空,新插入的节点为根节点 T=(BSTree)malloc(sizeof(BSTNode)); T->key=k; T->lchild=T->rchild=NULL; reurn 1; } else if(k==T->key) //树中存在相同关键字的节点,插入失败 return 0; else if(k<T->key) return BST_Insert(T->lchild,k); else (k==T->key) return BST_Insert(T->rchild,k); }
二叉排序树的构造
不同的关键字序列(Str[])可能得到同款二叉排序树,也可能不同款。
//二叉排序树的构造 void Creat_BST(BSTree &T,int str[],int n){ T=NULL; //初始是T为空树 int i=0; while(i<n){ BST_Insert(T,str[i]); i++; } }
平衡二叉树
哈夫曼树
节点的权:有某种现实意义的数值
节点带权路径长度:从树的根到该节点的路径长度(经过的边数)与该节点上权值的乘积
树的带权路径长度:树中所有叶子结点的带权路径长度之和
哈夫曼树:在含有N个带权叶子节点的二叉树中,其中带全路径长度最小(WPL)的二叉树称为哈夫曼树。
构造哈夫曼树:
每次选择两个最小的节点让它们成为兄弟,把它们的权值之和作为根节点的权值,把这个根节点的全值和另一个全值最小的结点他们成为兄弟,以此类推。
特点:(1)每个初始节点最终都成为叶子节点,且权值越小的节点到根节点的路径长度越大。
(2)哈夫曼树的节点总数为2n-1
(3)哈夫曼树不存在度为1的节点
(4)哈夫曼树不唯一,但wpl必然相同且为最优
哈夫曼编码

哈夫曼编码可以用于数据的压缩
根据数列中数据的个数 n,所得到的排列顺序的数目为:C22n/n+1



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报