

Python爬虫——将爬取的数据存入excle
本性项目从淘车网爬取数据并将爬下来的数据生成excle表格
安装 lxml和XlsxWriter库的时候飘红,从Terminal和Python interpreter安装都不行,最后试了试cmd
用到了清华镜像加速:-i https://pypi.tuna.tsinghua.edu.cn/simple
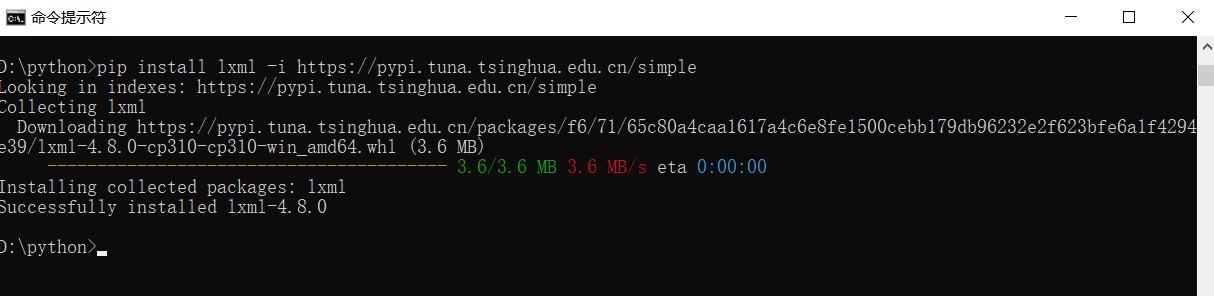
好像是先从cmd用清华镜像装,再从Python interpreter装,刚开始Python interpreter也装不上
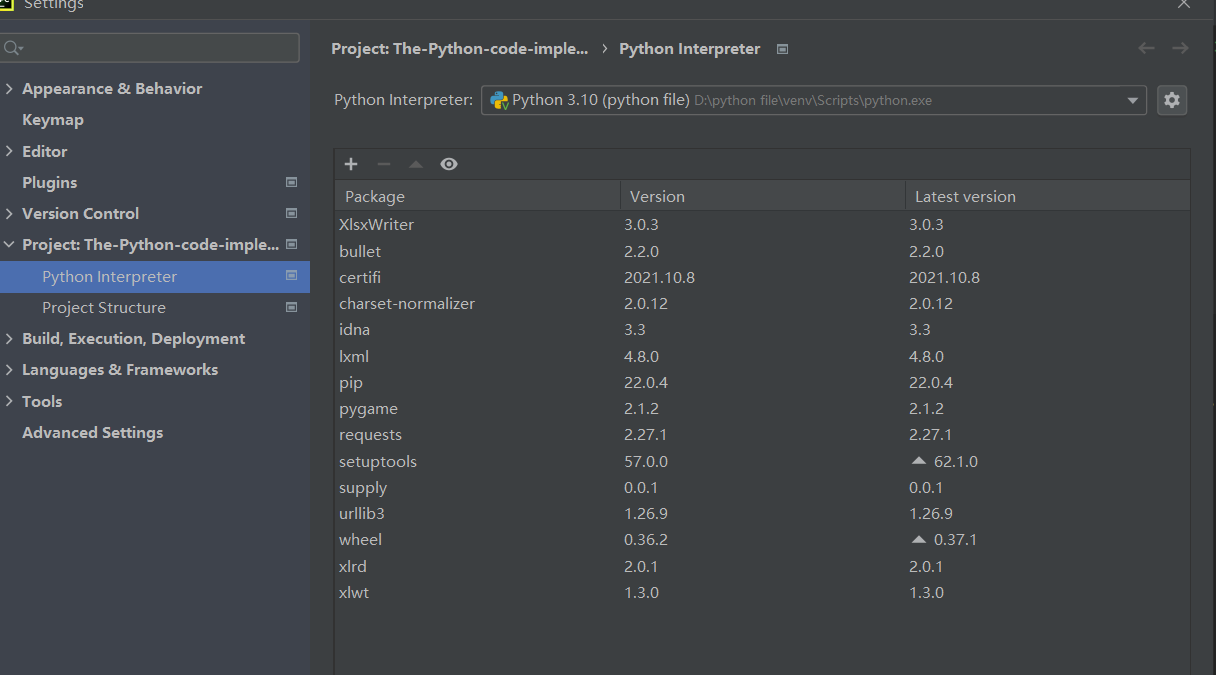

# -*- codeing = utf-8 -*- # @Time : 2022/5/6 21:42 下午 # @Auther :ywx # @File : 爬虫2.py # @Software: PyCharm import requests import xlrd import xlwt from lxml import etree import xlsxwriter url='https://beijing.taoche.com/landrover/' #设置请求头 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.50'} #通过状态码判断网页请求是否成功 def get(uel): response = requests.get(url,headers=headers) if response.status_code==200: print("success!") else: print("false") #爬虫部分 def parse(url): response = requests.get(url, headers=headers) #定义选择器 selector = etree.HTML(response.text) name = selector.xpath('//a/span/text()') originalprice = selector.xpath('//i[@class="onepaynor"]/text()') print(name,originalprice) # for i in range(len(name)): #print(name[i], originalprice[i]) #创建表格 workbook = xlsxwriter.Workbook('taoche_spider.xlsx') worksheet = workbook.add_worksheet() for i in range(len(name)): #在第i行,第1列,写入originalprice worksheet.write(i,0,name[i]) for i in range(len(originalprice)): worksheet.write(i, 1, originalprice[i]) workbook.close() get(url) parse(url)
创建表格的代码运行的时候出现 IndexError: list index out of range报错,刚开始以为是数组下标越界,后来发现是因为调用len(name)只能返回name[i],再返回 originalprice的时候 originalprice不在它的范围里。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报