KL散度,VAE
KL散度(相对熵)
 衡量两个概率分布的距离,两个概率分布越相似,KL散度越小,交叉熵越小。表示已知q,p的不确定性程度-p的不确定性程度
衡量两个概率分布的距离,两个概率分布越相似,KL散度越小,交叉熵越小。表示已知q,p的不确定性程度-p的不确定性程度
- 交叉熵:表示已知分布p后q的不确定程度,用已知分布p去编码q的平均码长

- 交叉熵在分类任务中为loss函数
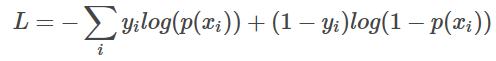
往往交叉熵比均方误差做loss函数好
1.均方差求梯度太小,在深度网络中,随着网络变深,会出现梯度消失,即梯度饱和问题,因此交叉熵做loss函数比较好。
2.均方误差是一个非凸的函数,cross-entropy是一个凸函数。
如两个高斯分布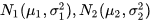 的KL散度KL(p1||p2)如下:
的KL散度KL(p1||p2)如下:
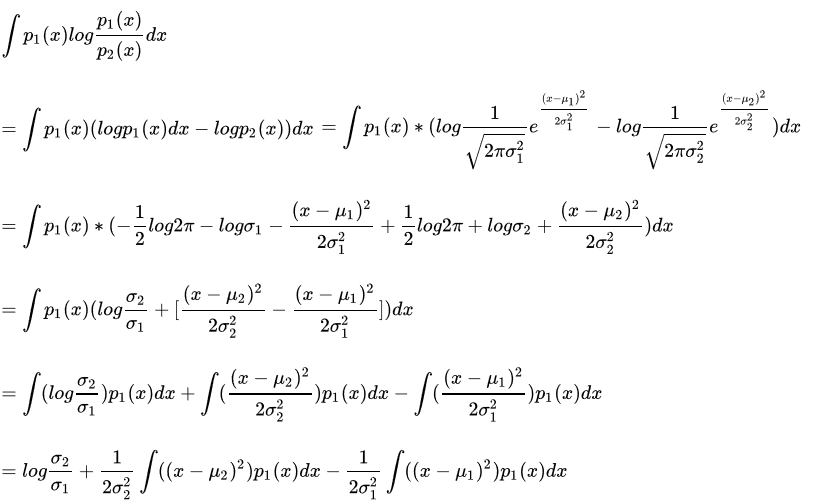
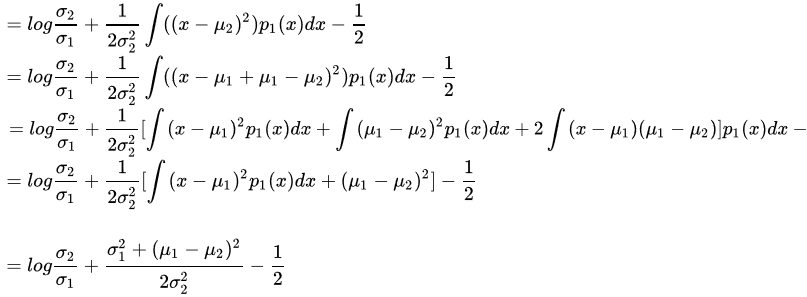
当其中一个是标准正太分布时,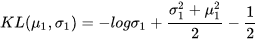
- 多维高斯KL散度
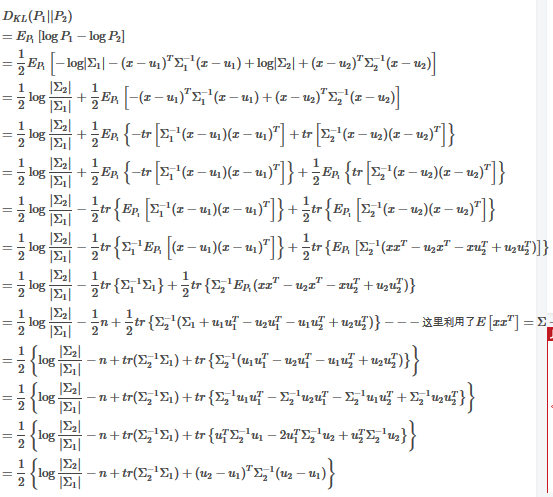

AE是由编码器合解码器组成,由于是一个编码和解码的过程,只是存储了图像信息没有加入随机因素,图像的生产没创新性和多样性,而VAE是通过解码器生产输入图像均值矩阵和方差矩阵,然后生产多维高斯分布矩阵Z,Z瞒住高斯分布,作为解码器的输入,加入了随机性,所以生产的图片多样性更强。
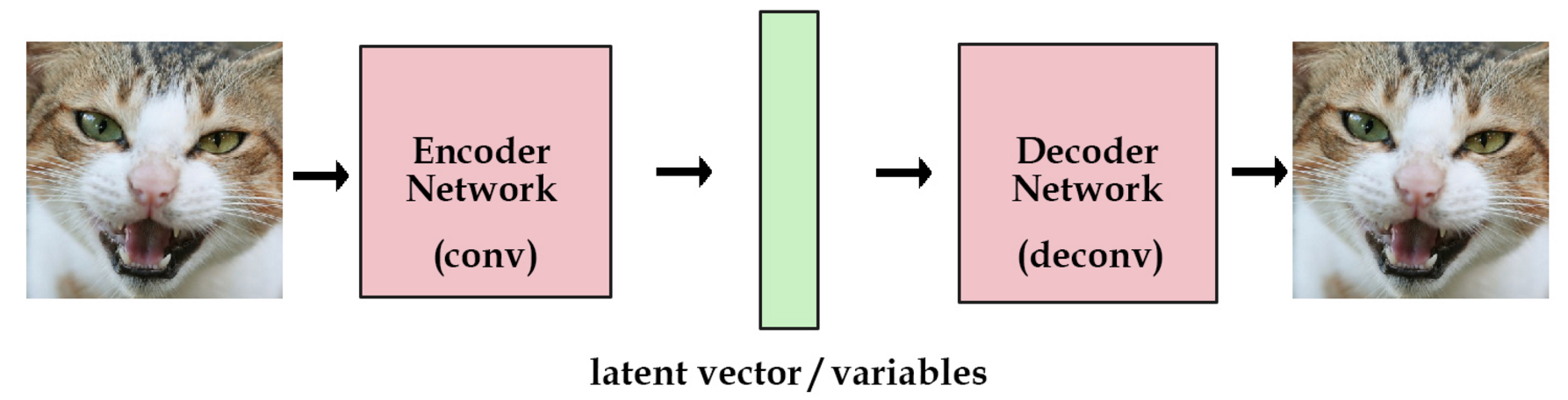
AE
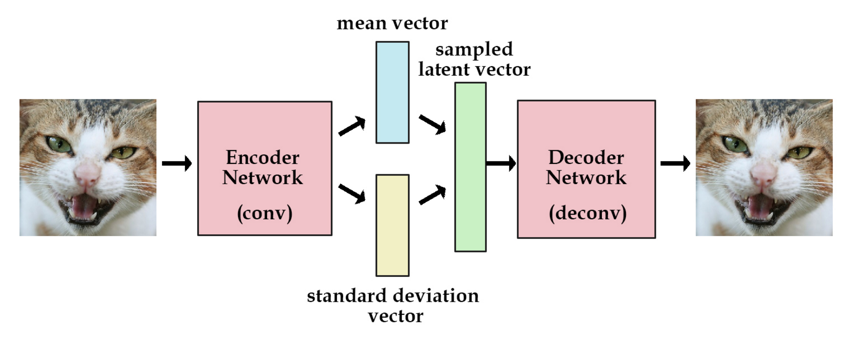
VAE
其中loss函数为
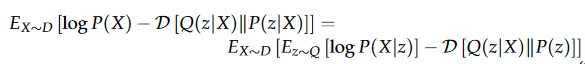
化简:
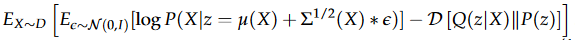
右边第一项为边缘概率的期望值,希望标准正态分布采样下的X生成概率最大,可以用交叉熵表示,等价于使输入的x和输出的X接近。
其中右边第二项为
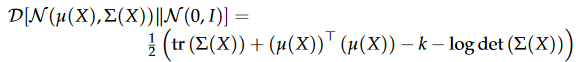
最终会让编码器构造的正态分布接近标准正态分布。
详细的推导过程,可以看《Tutorial on Variational Autoencoders》
下面是mnist的为数据集训练的代码


import os import tensorflow as tf import argparse from PIL import Image import numpy as np FLAGS = None; def read_image(filename): reader = tf.TFRecordReader() filename_queue = tf.train.string_input_producer([filename]) _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, features={ 'image_raw': tf.FixedLenFeature([], tf.string), 'label': tf.FixedLenFeature([], tf.int64), }) image = tf.decode_raw(features['image_raw'], tf.uint8) image = tf.reshape(image, [784]) image = tf.cast(image, tf.float32) * (1. / 255.) label = tf.cast(features['label'], tf.int32) return image,label def read_image_batch(filename,batch_size = 128): image,label = read_image(filename) num_preprocess_threads = 10 batch_size = batch_size min_queue_examples = 100 image_batch, label_batch = tf.train.shuffle_batch( [image, label], batch_size=batch_size, num_threads=num_preprocess_threads, capacity=min_queue_examples + batch_size, min_after_dequeue=min_queue_examples) one_hot_labels = tf.to_float(tf.one_hot(label_batch, 10, 1, 0)) return image_batch,one_hot_labels def weight_variable(shape): "creat a weight variable initial with stddev" return tf.get_variable('weights', shape,initializer = tf.contrib.layers.variance_scaling_initializer()) def bias_variable(shape,_init = 0.0): """Create a bias variable with appropriate initialization.""" return tf.get_variable('biases', shape,initializer = tf.constant_initializer(0.0)) def full_connect(input, out_depth, name = 'full_connect'): with tf.variable_scope(name): W = weight_variable([input.get_shape()[1], out_depth]) B =bias_variable([out_depth],_init = 0.0) return tf.matmul(input, W) + B def Gaussian_encoder(x,reuse = False): with tf.variable_scope("gaussian_encoder",reuse = reuse) as scope: if reuse: scope.reuse_variables() fc1 = full_connect(x,500,name = 'fc1') fc1 = tf.nn.elu(fc1) fc1 = tf.nn.dropout(fc1, 0.9) fc2 = full_connect(fc1,500,name = 'fc2') fc2 = tf.nn.tanh(fc2) fc2 = tf.nn.dropout(fc2, 0.9) z_mean = full_connect(fc2,20,name='mean') #stddev must be postive z_stddev = 1e-6 + tf.nn.softplus(full_connect(fc2,20,name="weight")) return z_mean,z_stddev def Bernoulli_decoder(z,n_output,reuse = False): with tf.variable_scope("bernoulli_decoder",reuse = reuse) as scope: if reuse: scope.reuse_variables() fc1 = full_connect(z,500,name = 'fc1') fc1 = tf.nn.tanh(fc1) fc1 = tf.nn.dropout(fc1, 0.9) fc2 = full_connect(fc1,500,name = 'fc2') fc2 = tf.nn.elu(fc2) fc2 = tf.nn.dropout(fc2, 0.9) x_ = full_connect(fc2,n_output,name='output') x_ = tf.nn.sigmoid(x_) return x_ def autoencoder(x): mu,sigma = Gaussian_encoder(x) z = mu + sigma * tf.random_normal(tf.shape(mu),0,1,dtype=tf.float32) x_ = Bernoulli_decoder(z,x.get_shape()[1]) #x_ image pixel must in 0-1 x_ = tf.clip_by_value(x_, 1e-8, 1 - 1e-8) marginal_likelihood = tf.reduce_sum(x*tf.log(1e-8+x_) + (1-x) * tf.log(1e-8+1-x_),1) KL_divergence = 0.5 * tf.reduce_sum(tf.square(sigma) + tf.square(mu)-tf.log(1e-8 + tf.square(sigma)) -1,1) loss = -tf.reduce_mean(marginal_likelihood - KL_divergence) return loss def decoder(z,dim_img): image = Bernoulli_decoder(z,dim_img,reuse = True) return image def Reconstruction(x): mu,sigma = Gaussian_encoder(x,reuse = True) z = mu + sigma * tf.random_normal(tf.shape(mu),0,1,dtype=tf.float32) images = Bernoulli_decoder(z,x.get_shape()[1],reuse = True) return images def main(_): train_images,train_labels = read_image_batch("./train.tfrecords") test_images,test_labels = read_image_batch("./test.tfrecords") x = tf.reshape(train_images,[-1,784]) test_images = tf.reshape(test_images,[-1,784]) loss = autoencoder(x) train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss) #saver = tf.train.Saver() x_test = tf.placeholder(tf.float32, shape=[None,784]) x_gen = Reconstruction(x_test) z = tf.placeholder(tf.float32, shape=[None,20]) z_ = decoder(z,784) z_feed = np.random.normal(loc=0, scale=1, size=[1,20]) with tf.Session() as sess: tf.global_variables_initializer().run() coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) x_t = sess.run(test_images) xt = np.array(x_t[6]*255.).astype(np.uint8).reshape([28,28]) result = Image.fromarray(xt) result.save( 'input.png') for i in range(10000): sess.run(train_step) if ((i+1)%1000 == 0): print("step:", i + 1, "loss:", sess.run(loss)) x_ = sess.run(x_gen,feed_dict={x_test:x_t}) x_ = np.array(x_[6]*255.).astype(np.uint8).reshape([28,28]) result = Image.fromarray(x_) result.save(str(i+1) + '.png') z_out = sess.run(z_,feed_dict={z:z_feed}) z_out = np.array(z_out*255.).astype(np.uint8) result = Image.fromarray(z_out.reshape([28,28])) result.save('z_'+str(i+1) + '.png') print("loss: " , sess.run(loss)) coord.request_stop() coord.join(threads) if __name__ == '__main__': parser = argparse.ArgumentParser(); parser.add_argument('--buckets', type=str, default='',help='input data path') parser.add_argument('--checkpointDir', type=str, default='',help='output model path') FLAGS, _ = parser.parse_known_args() tf.app.run(main=main)
其中loss为边缘概率的最大似然和KL散度最小值
marginal_likelihood = tf.reduce_sum(x*tf.log(1e-8+x_) + (1-x) * tf.log(1e-8+1-x_),1) KL_divergence = 0.5 * tf.reduce_sum(tf.square(sigma) + tf.square(mu)-tf.log(1e-8 + tf.square(sigma)) -1,1) loss = -tf.reduce_mean(marginal_likelihood - KL_divergence)
参考: https://zhuanlan.zhihu.com/p/22464760

 浙公网安备 33010602011771号
浙公网安备 33010602011771号