分布式深度学习(Spark MLlib,Parameter Server、Ring-allreduce和Tensorflow )
Spark MLlib
Spark分布式计算原理
Spark(分布式的计算平台),分布式:指计算节点之间不共享内存,需要通过网络通信的方式交换数据。Spark最典型的应用方式是建立在大量廉价计算节点(廉价主机、虚拟的docker container)上;但这种方式区别于CPU+GPU的架构和共享内存多处理器的高性能服务器架构。

图1
从图1Spark架构图看出,Manager node调度组织Spark程序,而Worker Node(可分为不同的partition(数据分片),是spark的基本出来单元)执行具体的计算任务,然后将结果返回给Drive Program。
执行具体的程序时,Spark将程序拆解成一个任务DAG(有向无环图),再根据DAG决定程序各步骤执行的方法。如图2所示,该程序先分别从textFile和HadoopFile读取文件,经过一些列操作后再进行join,最终得到处理结果。
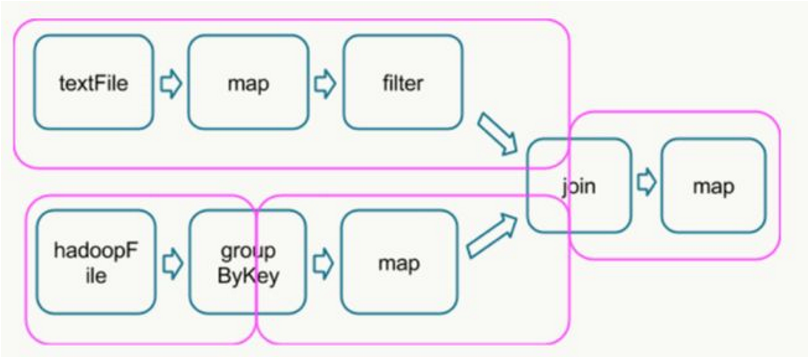
图2
在Spark平台上并行处理DAG时,最关键的过程是找到哪些是可以并行处理的部分,哪些是shuffle和reduce。
shuffle指的是所有partition的数据必须进行洗牌后才能得到下一步的数据,最典型的操作就是groupByKey和join操作。拿join操作来说,必须通过在textFile数据中和hadoopFile数据中做全量的匹配才可以得到join后的dataframe。而groupby操作需要对数据中所有相同的key进行合并,也需要全局的shuffle才能够完成。
map,filter等操作仅需要逐条的进行数据处理和转换就可以,不需要进行数据间的操作,因此各partition之间可以并行处理。
在得到最终的计算结果之前,程序需要进行reduce的操作,从各partition上汇总统计结果,随着partition的数量逐渐减小,reduce操作的并行程度逐渐降低,直到将最终的计算结果汇总到master节
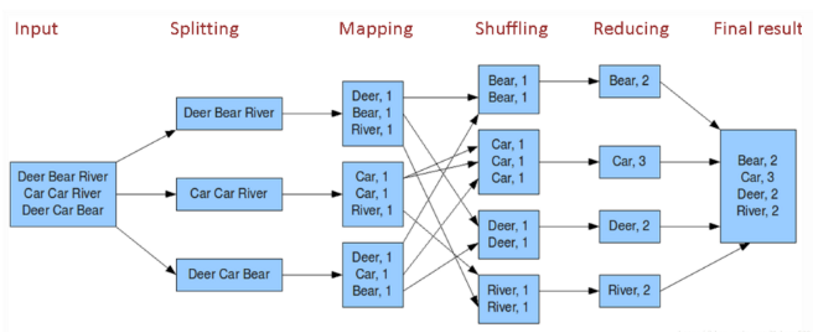 图3
图3
DAG根据宽依赖划分成stag(如图2粉色框),而shuffle操作是宽依赖,需要在不同计算节点之间进行数据交换,非常消耗计算、通信及存储资源,因此shuffle操作是spark程序应该尽量避免的。Spark的计算过程:Stage内部数据高效并行计算,Stage边界处进行消耗资源的shuffle操作或者最终的reduce操作。
Spark MLlib并行训练原理——梯度下降的实现方法
Spark MLlib如何实现Random Forest(完全可以实现数据并行,而GBDT智能并行)这里不讨论,是讨论如何实现深度学习的分布式训练。梯度下降的并行程度实现质量直接决定了深度学习模型的训练速度。
MiniBatch梯度下降的源码(猜测在sparkcontext上运行)
while (!converged && i <= numIterations) { val bcWeights = data.context.broadcast(weights) // Sample a subset (fraction miniBatchFraction) of the total data // compute and sum up the subgradients on this subset (this is one map-reduce) val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i) .treeAggregate((BDV.zeros[Double](n), 0.0, 0L))( seqOp = (c, v) => { // c: (grad, loss, count), v: (label, features) val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1)) (c._1, c._2 + l, c._3 + 1) }, combOp = (c1, c2) => { // c: (grad, loss, count) (c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3) }) bcWeights.destroy(blocking = false) if (miniBatchSize > 0) { /** * lossSum is computed using the weights from the previous iteration * and regVal is the regularization value computed in the previous iteration as well. */ stochasticLossHistory += lossSum / miniBatchSize + regVal val update = updater.compute( weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble), stepSize, i, regParam) weights = update._1 regVal = update._2 previousWeights = currentWeights currentWeights = Some(weights) if (previousWeights != None && currentWeights != None) { converged = isConverged(previousWeights.get, currentWeights.get, convergenceTol) } } else { logWarning(s"Iteration ($i/$numIterations). The size of sampled batch is zero") } i += 1 }
简化版:
while (i <= numIterations) { //迭代次数不超过上限 val bcWeights = data.context.broadcast(weights) //广播模型所有权重参数 val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i) .treeAggregate() //各节点采样后计算梯度,通过treeAggregate汇总梯度 val weights = updater.compute(weights, gradientSum / miniBatchSize) //根据梯度更新权重 i += 1 //迭代次数+1 }
Spark只有简单的数据平行,没有参数并行,mini batch过程制作了三件事,:
1. 把当前的模型参数广播到各个数据partition(可当作虚拟的计算节点)
2. 各计算节点进行数据抽样得到mini batch的数据,分别计算梯度(可并行),再通过treeAggregate操作汇总梯度,得到最终梯度gradientSum
3. 利用gradientSum更新模型权重
其中treeAggregate,逐层汇总求和,这个操作是一次reduce操作,本身并不包含shuffle操作,再加上采用分层的树形操作,在每层中都是并行执行的,因此整个过程是相对高效的。
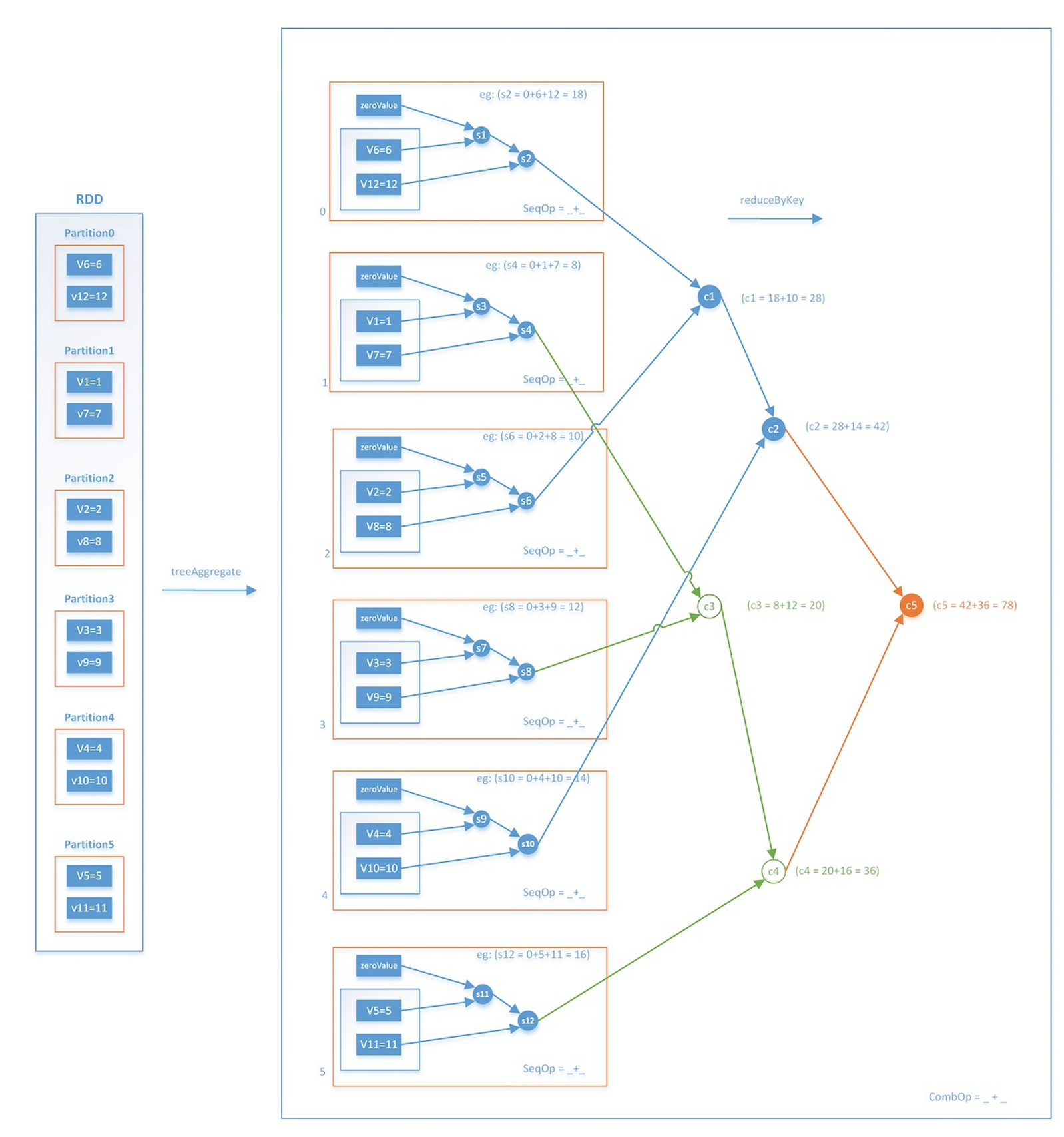
图4
Spark MLlib并行训练的局限性
1. 采用全局广播的方式,在每轮迭代前广播全部模型参数。众所周知Spark的广播过程非常消耗带宽资源,特别是当模型的参数规模过大时,广播过程和在每个节点都维护一个权重参数副本的过程都是极消耗资源的过程,这导致了Spark在面对复杂模型时的表现不佳;
2. 采用阻断式的梯度下降方式,每轮梯度下降由最慢的节点决定。从上面的分析可知,Spark MLlib的mini batch的过程是在所有节点计算完各自的梯度之后,逐层Aggregate最终汇总生成全局的梯度。也就是说,如果由于数据倾斜等问题导致某个节点计算梯度的时间过长,那么这一过程将block其他所有节点无法执行新的任务。这种同步阻断的分布式梯度计算方式,是Spark MLlib并行训练效率较低的主要原因;
3. Spark MLlib并不支持复杂网络结构和大量可调超参。事实上,Spark MLlib在其标准库里只支持标准的多层感知机神经网络的训练,并不支持RNN,LSTM等复杂网络结构,而且也无法选择不同的activation function等大量超参。这就导致Spark MLlib在支持深度学习方面的能力欠佳。
Parameter Server的分布式训练原理
PS是李沐提出的,MXNET和tensorflow都实现了该方案,该方案要解决的问题:
1. 访问这些巨量的参数,需要大量的网络带宽支持;
2. 很多机器学习算法都是sequential ,只有上一次迭代完成(各个worker都完成)之后,才能进行下一次迭代,这就导致了如果机器之间性能差距大(木桶理论),就会造成性能的极大损失;
3. 在分布式中,容错能力是非常重要的。很多情况下,算法都是部署到云环境中的(这种环境下,机器是不可靠的,并且job也是有可能被抢占的)。
PS的物理架构
与spark的master-worker的架构基本一致,如下
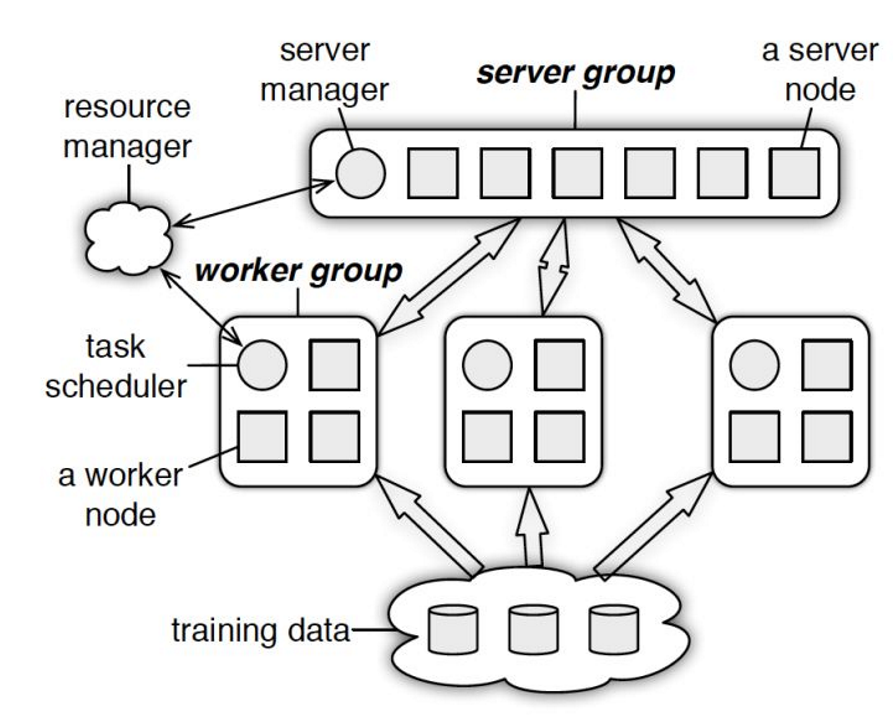
图5
PS分为两大部分:server group和多个worker group,另外resource manager负责总体的资源分配调度。
• server group一般包含多个server node,当模型参数过多单台server不能容纳时(如何单机能存心,单点通信带宽瓶颈怎么办,虽然是异步PULL和PUSH但是还是很频繁的数据交换),server node通过Key-value的形式负责维护一部分参数,server manager负责维护和分配server资源;
• 每个worker group对应一个application(即一个模型训练任务),worker group之间及内部并不无通信,只与server通信。各 worker 上的训练数据只涵盖了一部分特征(由于推荐/搜索等模型的特征超级稀疏),如
下图当有100个worker node时,其涵盖的参数规模占总参数的7.8%,所以worker node可以很轻易的在本地缓存下所需的参数,每次更新也只需同步本地训练数据所能够涵盖的那一部分模型即可,大大节省带宽。
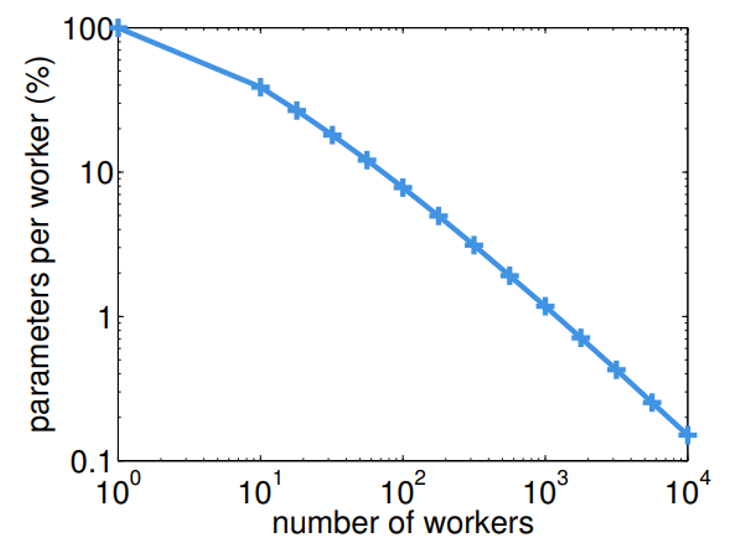
图6
• PS 最擅长的是训练稀疏数据集上的算法,如超大规模 LR 的 CTR 预估(论文《Scaling Distributed Machine Learning with the Parameter Server》中以此举例)。但是基于 DNN 的推荐/搜索算法,常见模式是稀疏 ID 特征 Embedding+MLP,稍稍有所不同 。
- 稀疏 ID 特征 Embedding,是使用 PS 的理想对象
-
- 超大的 embedding 矩阵已经无法容纳于单台机器中,需要分布式的 key-value 数据库共同存储;数据稀疏,各 worker 上的训练数据只涵盖一部分 ID 特征,自然也只需要和 server 同步这一部分 ID 的embedding 向量。
2. MLP 部分,稍稍不同
-
- 和计算机视觉中动辄几百层的深网络相比,工业级别的推荐/搜索算法的MLP 也就是 3~4 层而已,否则就有过拟合的风险。这等「小浅网络」可以容纳于单台机器的内存中,不需要分布式存储。 与每台 worker 只需要与 server 同步本地所需要的部分 embedding 不同,MLP 是一个整体,每台 worker 都需要与 server 同步完整 MLP 的全部参数,不会只同步局部模型。
3. 因此实践中:
-
- 稀疏 ID 特征 Embedding,就是标准的 PS 做法,用 key-value 来存储。Key 就是 id feature,value 就是其对应的 embedding 向量;
- MLP 部分,我用一个 KEY_FOR_ALL_MLP 在 server 中存储 MLP 的所有参数(一个很大,但单机足以容纳的向量),以完成 worker 之间对 MLP 参数的同步。
一般模型的目标,最小化损失函数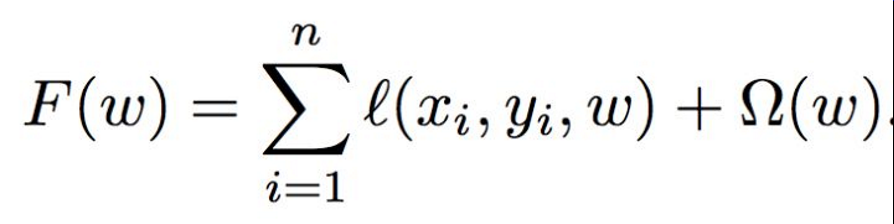
常用的优化方法时随机梯度下降,图7介绍了分布式梯度下降法的伪代码:

图7
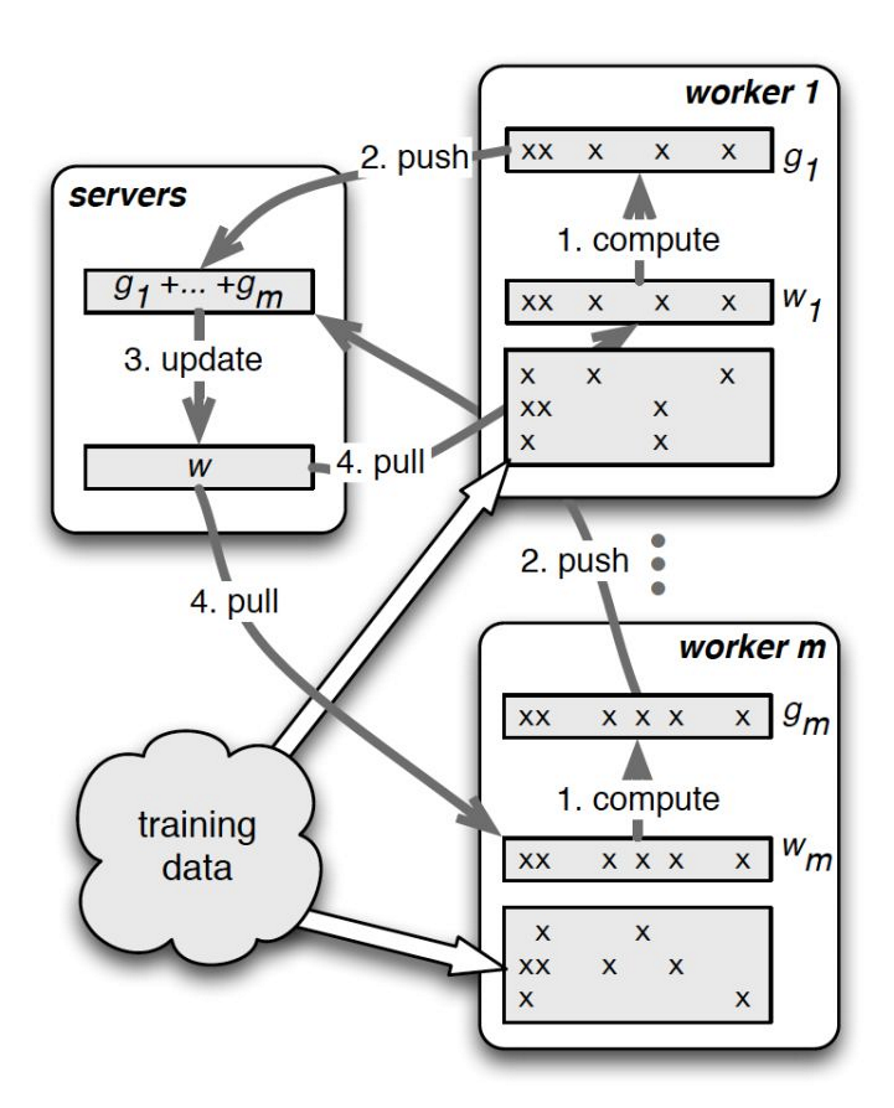
图8并行训练流程示意图
•server节点的主要功能是保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数(论文中描述的是汇总了所有梯度,再更新参数,感觉是同步更新,但实际好像是异步更新,server得到一个梯度进行更新一次,如何更新其实可以设计规则,平衡一致性和并行效率)
• worker节点的主要功能是各保存部分训练数据,从server节点拉取最新的模型参数,根据训练数据计算局部梯度,上传给server节点。
PUSH&PULL
• push:worker节点利用本节点上的训练数据,计算好局部梯度,上传给server节点;
• pull:为了进行下一轮的梯度计算,worker节点从server节点拉取最新的模型参数到本地。
整个PS的分布式训练流程:
1. 每个worker载入一部分训练数据
2. worker节点从server节点pull最新的所需模型参数
3. worker节点利用本节点数据计算梯度
4. worker节点将梯度push到server节点
5. server节点汇总梯度更新模型
6. goto step2 直到迭代次数上限或模型收敛
PS支持Range Push & Range Pull ,即w.push(R,dest)&w.pull(R,dest),R是worker节点所需模型参数的一个范围,可以是所有参数也可以是部分参数,Server上的key都是排序的(一般是先hash后排序,后面会详细说)。
一致性和并行效率的平衡
worker节点的梯度下降不是“同步阻断式”(严格意义上一致性最强的梯度下降方法),根据调度逻辑可以是“异步非阻断式”的,如9图,节点在做第11次迭代(iter 11)计算时,第10次迭代后的push&pull过程并没有结束,也就是说最新的模型权重参数还没有被拉取到本地,该节点仍使用的是iter 10的权重参数计算的iter 11的梯度。但是iter12必须获取最新参数后再计算梯度,这是通过一些“最大延迟”等参数来限制异步的程度。比如可以限定在三轮迭代之内,模型参数必须更新一次,那么如果某worker节点计算了三轮梯度,该节点还未完成一次从server节点pull最新模型参数的过程,那么该worker节点就必须停下等待pull操作的完成。即iter12这个task是依赖与前面pull task的完成,如图10c,这是同步和异步之间的折衷方法。
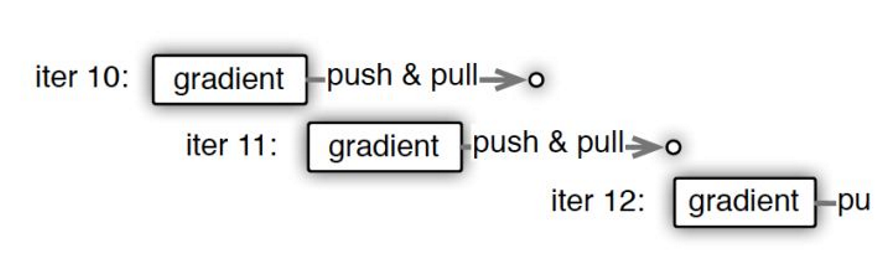
图9

图10
下面是两个同步和异步更新的动画,可以明显看出区别

图11 同步
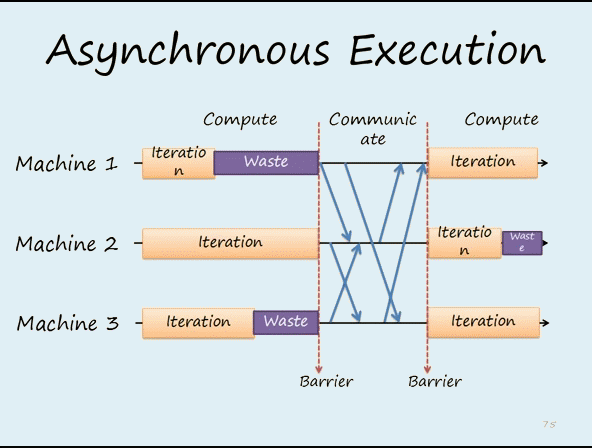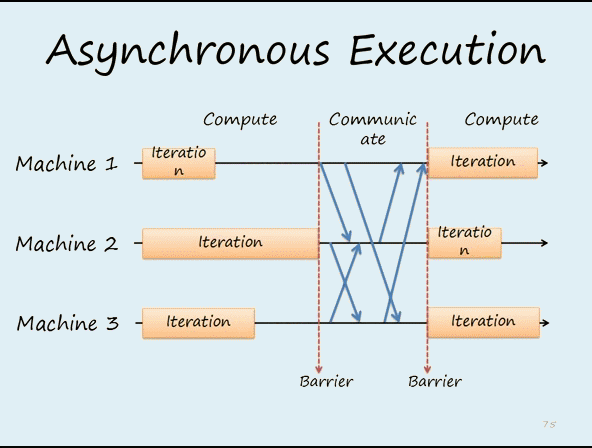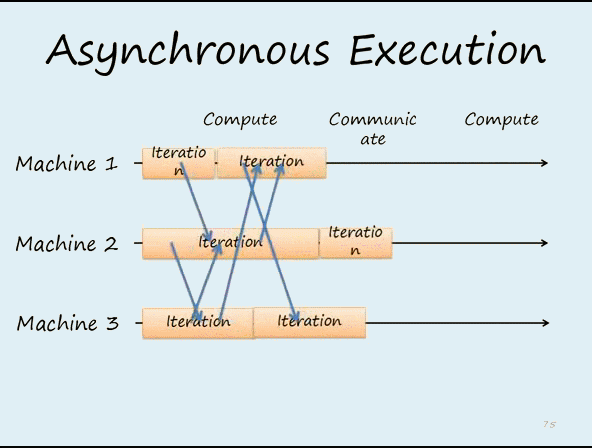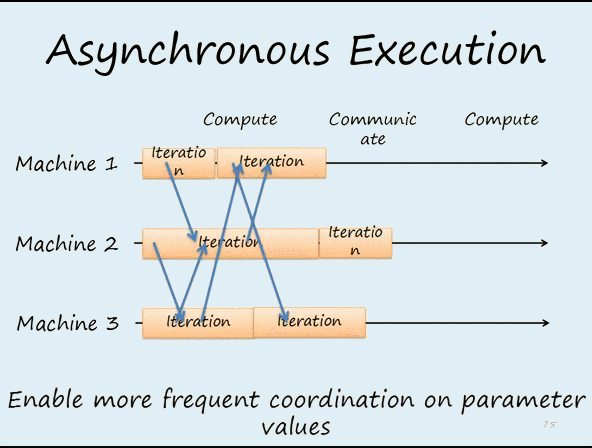
图12 异步
多server节点的协同
PS采用了server group内多server的架构,每个server主要负责一部分的模型参数(Key Range )。考虑了容错性(server节点挂了,新节点加入等),采用了一致性hashing:
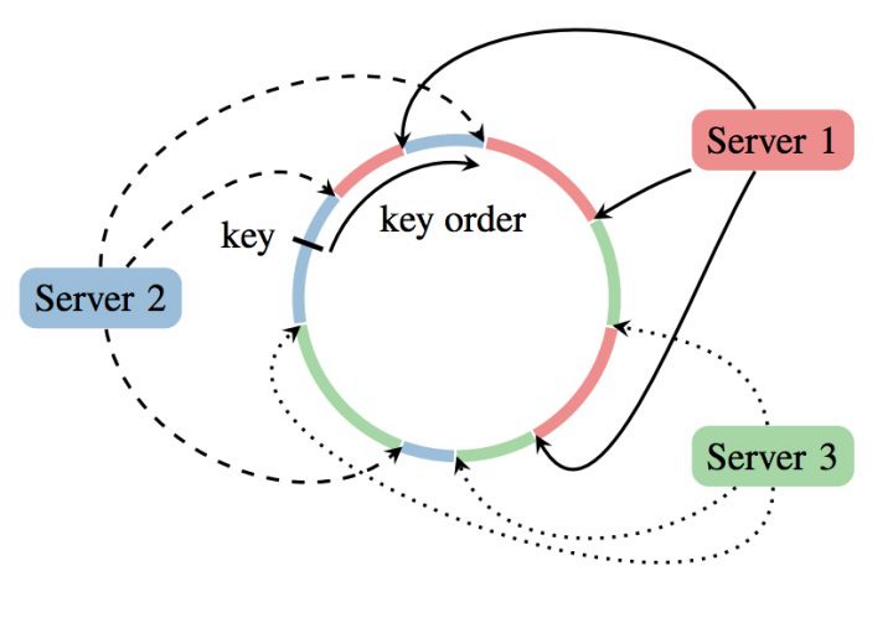
图13
PS的server group中应用一致性哈希的原理大致有如下几步:
1. 将模型参数的key映射到一个环形的hash空间,比如有一个hash函数可以将任意key映射到0~(2^32)-1的hash空间内,我们只要让(2^32)-1这个桶的下一个桶是0这个桶,那么这个空间就变成了一个环形hash空间;
2. 根据server节点的数量n,将环形hash空间等分成n*m个range,让每个server间隔地分配m个hash range。这样做的目的是保证一定的负载均衡性,避免hash值过于集中带来的server负载不均;
3. 在新加入一个server节点时,让新加入的server节点找到hash环上的插入点,让新的server负责插入点到下一个插入点之间的hash range,这样做相当于把原来的某段hash range分成两份,新的节点负责后半段,原来的节点负责前半段。这样不会影响其他hash range的hash分配,自然不存在大量的rehash带来的数据大混洗的问题。
4. 删除一个server节点时,移除该节点相关的插入点,让临近节点负责该节点的hash range。
PS server group中应用一致性哈希原理,其实非常有效的降低了原来单master节点带来的瓶颈问题。worker节点通过Range PUSH & PULL,异步的与对应的不同server进行参数交换,防止了单点广播参数带来的带宽瓶颈。
Worker节点的协作:
当训练数据比较大时,恢复一个worker节点的代价比恢复一个server节点代价大,但少了这部分训练数据可能对模型收敛影响很小,有的时候可能就不恢复worker节点,甚至停掉最快的worker节点。
Parameter Server要点
1. 用“异步非阻断式”的分布式梯度下降策略替代同步阻断式的梯度下降策略;
2. 实现多server节点的架构,避免了单master节点带来的带宽瓶颈和内存瓶颈;
3. 使用一致性哈希,range pull和range push等工程手段实现信息的最小传递,避免广播操作带来的全局性网络阻塞和带宽浪费。
这只是Parameter Server的主要原理,还有如同步信息,更新参数,梯度失效(stale gradient)等问题未详细介绍。
总之如图14,Parmeter Sever加快了训练,减少了交互的通讯量
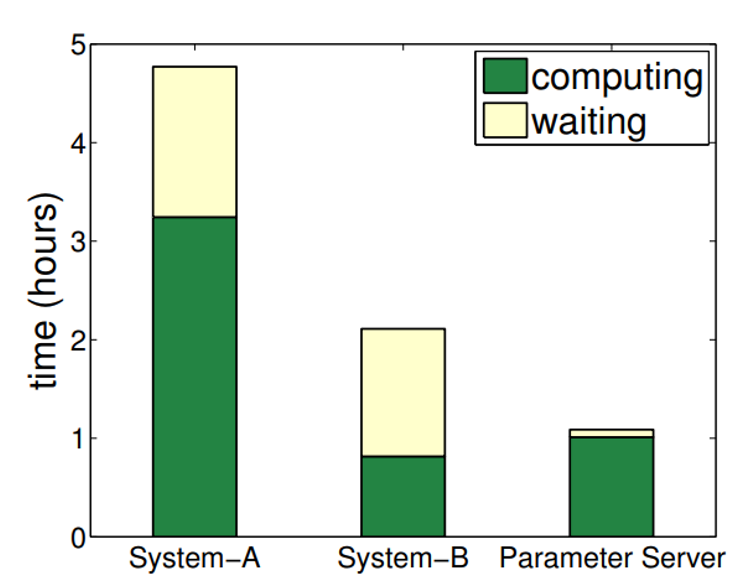
图14
以上Parameter Server的主要原理,还有如同步信息,更新参数,梯度失效(stale gradient)等问题未详细介绍。
未弄明白的问题:模型一般需要每天更新,要实现每天更新训练(不然效果会下降),就可能有新id特征,Embedding参数就要增加,如何新增key,文中没给出,但是论文又提到了这么一段话“Moreover, billions of new ad impressions may arrive daily. Adding this data into the system often improves both prediction accuracy and coverage. But it also requires the learning algorithm to run daily, possibly in real time. ”
Ring-AllReduce
在PS框架下,同步更新,然后将参数广播到worker node(虽然是worker node去PULL参数,但是同步更新会造成同时PULL就是广播),会网络通信瓶颈,虽然说PS里用了多个server来减轻带宽压力,而worker的带宽没充分有用起来。
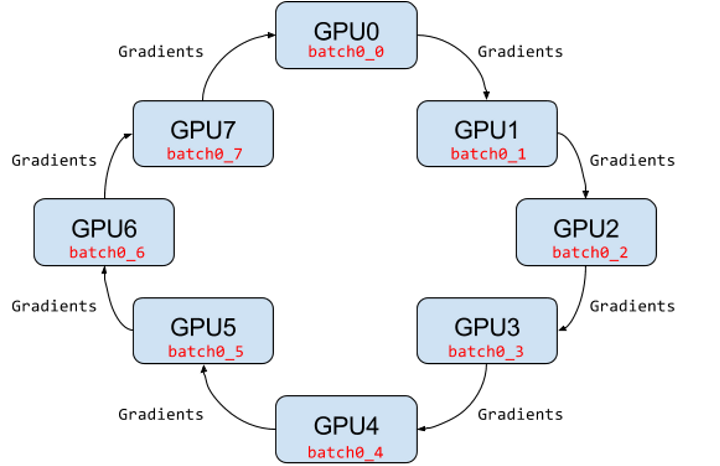
图15 Ring-AllReduce架构示意图
Ring AllReduce是一种分布式规约算法,《Bringing HPC Techniques to Deep Learning》将其用到深度学习里,用同步更新,但是没有通信压力,如图15,该方法所有节点都是等同的worker节点共N个,将梯度分成N份,梯度传播分为两步:
1. scatter-reduce:如图16左边,逐步交换彼此的梯度并融合,最后每个节点都会包含完整融合梯度的一部分。共N-1次通信,每次发送数据量S/N,S是总数据SIZE,B是带宽,因此Data Transferred = (N-1)*S/(NB),计算量为(N-1)*(S/N)*C
2. allgather:如图16右边,逐步交换彼此不完整的融合梯度,最后所有 节点都会得到完整的融合梯度。共N-1次通信,Data Transferred = (N-1)*S/(NB),没有计算。
总通讯量2(N-1)*S/(NB)不会随着节点个数增加而增加,具有线性加速的能力。
相比PS架构,Ring-allreduce架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。在百度的实验中,他们发现训练速度基本上线性正比于worker节点数。
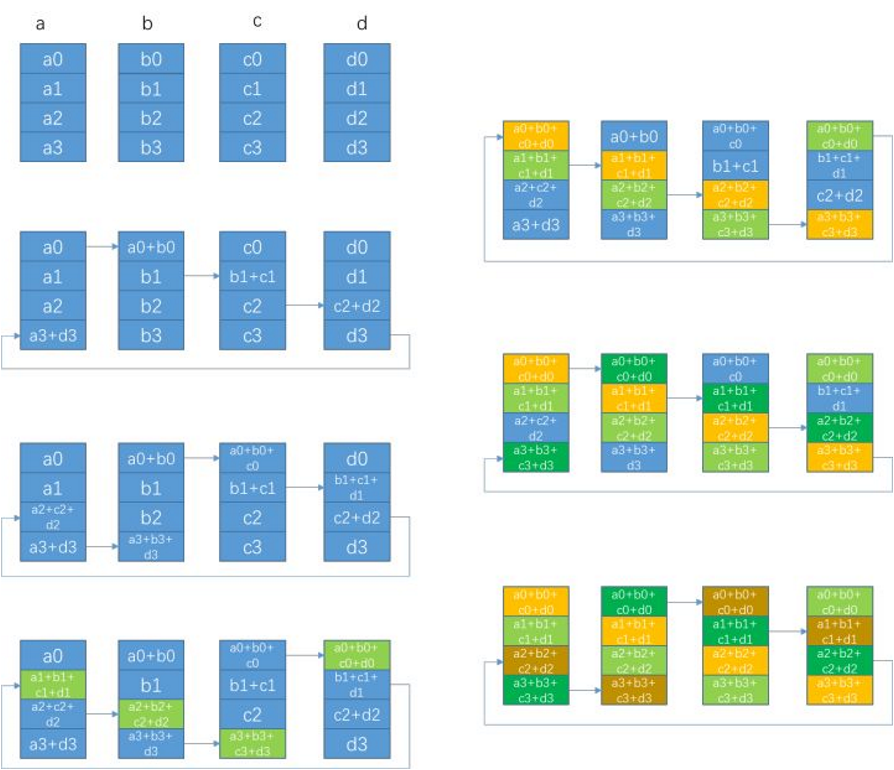
图16
Ring AllReduce只是规约算法的一种,其存在一个问题,随着节点增多单个Ring越来越大,延迟将不可接受?(未理解,之前不是时间不会随着N增大吗?难道是N增大之后额外的通讯量增多了,还是其数据量远远小于带宽,不能将带宽利用起来?)之后又一些改进参考资料3。
Tensorflow实现分布式架构
Tensorflow最开始的分布式架构是parmeter server框架(可实现同步更新和异步更新),后来也实现了Ring AllReduce框架(同步更新)。
基于PS框架的Tensorflow
图17是PS框架下的同步更新和异步更新,该模式下由于要等所有的worker把梯度传给PS节点后才进行梯度更新,实际上需要各个设备的计算和通信能力要均衡,由于木桶效应,一个拖油瓶会严重拖慢训练进度,所以同步更新相对来说训练速度会慢一些。异步更新,各worker节点完成一次mini-batch,不等待其他节点,直接更新梯度,由此会出现一个梯度失效问题(stale gradients,某设备完成梯度计算后,发现模型参数已经更新了,这个梯度是基于之前的参数计算得到的,已经失效了),从而导致陷入次优解问题(sub-optimal training perfomance),针对该问题,微软提出了一种Asynchronous Stochastic Gradient Descent方法,通过梯度补偿来提升训练效果。
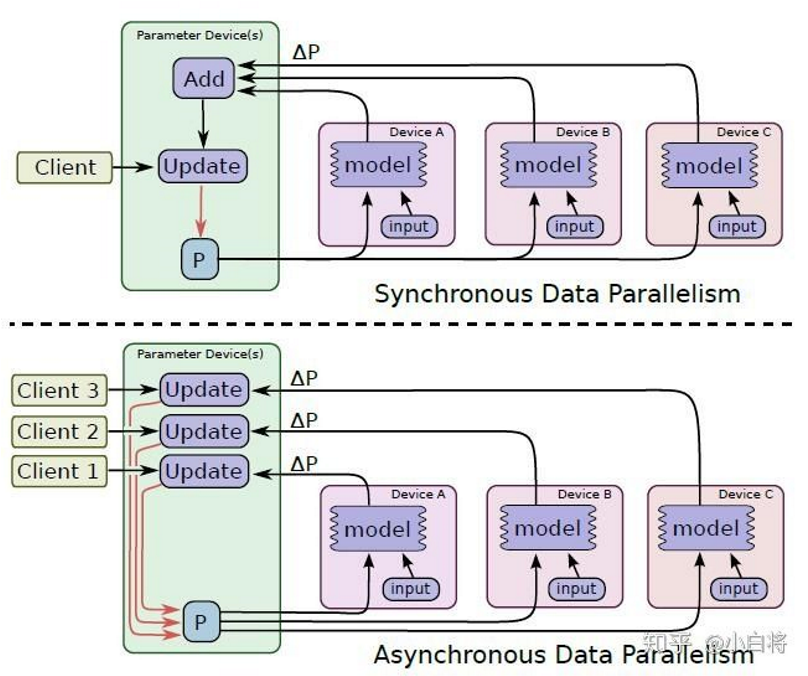
图17、同步更新和异步更新
参与分布式系统的所有节点或设备称为集群(cluster),一个cluster中包含很多服务器(server),每个server去执行一项任务(task),server和task一一对应。即cluster可以看成是server的集合/task的集合。TensorFlow为各个task又增加了一个抽象层,将一系列相似的task集合称为一个job,比如在PS架构中,习惯称parameter server的task集合为ps,而称执行梯度计算的task集合为worker。因此cluster也可以看成是job的集合,不过这只是逻辑上的意义,具体还要看这个server真正干什么。
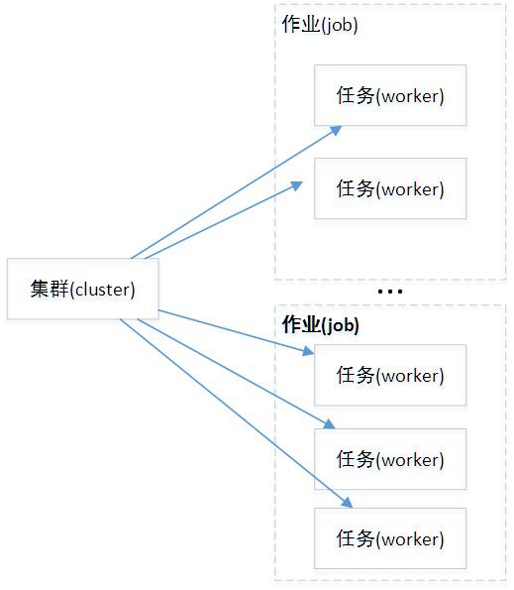
图18 集群内部关系图
我们可以手动调度cluster中server,也可以通过轮询和贪心的方式自动调度分配。
with tf.device("/job:ps/task:0"): weights_1 = tf.Variable(...) biases_1 = tf.Variable(...) with tf.device("/job:ps/task:1"): weights_2 = tf.Variable(...) biases_2 = tf.Variable(...) with tf.device("/job:worker/task:7"): input, labels = ... layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1) logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2) # ... train_op = ... #指定Session的target参数,采用grpc+主机地址,或者sever.target,两者等同。 with tf.Session("grpc://worker7.example.com:2222") as sess: for _ in range(10000): sess.run(train_op)
PS下复制训练(Replicated training)的实现方式
1. In-graph replication:只构建一个client,一个Graph,Graph中包含一套模型参数,放置在ps上(client在PS上创建,tf.session在PS上创建),同时Graph中包含模型计算部分的多个副本,每个副本都放置在一个worker上,这样多个worker可以同时训练复制的模型,每个worker计算子图是相同的,但是属于同一个Graph。这种方法很少使用,因为一旦client挂了,整个系统就全崩溃了,容错能力差。
2. Between-graph replication:每个worker都创建一个client,这个client一般还与task的主程序在同一进程中。各个client构建相同的Graph,但是参数还是放置在ps上。这种方式就比较好,一个worker的client挂掉了,系统还可以继续跑。
3. Asynchronous training:异步方式训练,各个worker自己干自己的,不需要与其它worker来协调,前面也已经详细介绍了异步训练,上面两种方式都可以采用异步训练。
4. Synchronous training:同步训练,各个worker要统一步伐,计算出的梯度要先聚合才可以执行一次模型更新,对于In-graph replication方法,由于各个worker的计算子图属于同一个Graph,很容易实现同步训练。但是对于Between-graph replication方式,各个worker都有自己的client,这就需要系统上的设计了,TensorFlow提供了tf.train.SyncReplicasOptimizer来实现Between-graph replication的同步训练
In-graph replication的例子(如果参数过多一个PS上放不下呢?)


1 #通用的数据并行还是推荐between-graph的,因为in-graph要自己归并cost之类的 2 #10.100.203.75这台运行 3 #python test_dis.py --job_name=worker --ps_hosts=10.100.203.75:1111 --worker_hosts=10.100.206.209:2222,10.100.203.75:2223 --task_id=1 4 #python test_dis.py --job_name=ps --ps_hosts=10.100.203.75:1111 --worker_hosts=10.100.206.209:2222,10.100.203.75:2223 --task_id=0 5 #10.100.206.209这台运行 6 #python test_dis.py --job_name=worker --ps_hosts=10.100.203.75:1111 --worker_hosts=10.100.206.209:2222,10.100.203.75:2223 --task_id=0 7 #注意task_id和在哪台机器上启动--job_name=worker脚本的--worker_hosts顺序对应 8 #感觉最好应该先运行2个worker在运行ps,最后是只在ps有打印训练过程 9 10 import tensorflow as tf 11 FLAGS = tf.app.flags.FLAGS 12 tf.app.flags.DEFINE_string('job_name', '', 'One of "ps", "worker"') 13 tf.app.flags.DEFINE_string('ps_hosts', '', 14 """Comma-separated list of hostname:port for the """ 15 """parameter server jobs. e.g. """ 16 """'machine1:2222,machine2:1111,machine2:2222'""") 17 tf.app.flags.DEFINE_string('worker_hosts', '', 18 """Comma-separated list of hostname:port for the """ 19 """worker jobs. e.g. """ 20 """'machine1:2222,machine2:1111,machine2:2222'""") 21 tf.app.flags.DEFINE_integer( 22 'task_id', 0, 'Task id of the replica running the training.') 23 ps_hosts = FLAGS.ps_hosts.split(',') 24 worker_hosts = FLAGS.worker_hosts.split(',') 25 cluster_spec = tf.train.ClusterSpec({'ps': ps_hosts,'worker': worker_hosts}) 26 server = tf.train.Server( 27 {'ps': ps_hosts,'worker': worker_hosts}, 28 job_name=FLAGS.job_name, 29 task_index=FLAGS.task_id) 30 31 32 print("!!!!") 33 if FLAGS.job_name == 'worker': 34 server.start() 35 server.join() 36 print("!!!!") 37 38 39 from tensorflow.examples.tutorials.mnist import input_data 40 mnist = input_data.read_data_sets("./", one_hot=True)#MNIST的四个.gz文件 41 42 learning_rate = 0.001 43 training_iters = 200000 44 batch_size = 128 45 display_step = 10 46 47 n_input = 784 48 n_classes = 10 49 dropout = 0.75 50 51 def conv2d(x, W, b, strides=1): 52 x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME') 53 x = tf.nn.bias_add(x, b) 54 return tf.nn.relu(x) 55 56 def maxpool2d(x, k=2): 57 return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1], 58 padding='SAME') 59 60 61 def conv_net(x, weights, biases, dropout): 62 x = tf.reshape(x, shape=[-1, 28, 28, 1]) 63 64 conv1 = conv2d(x, weights['wc1'], biases['bc1']) 65 # Max Pooling (down-sampling) 66 conv1 = maxpool2d(conv1, k=2) 67 68 conv2 = conv2d(conv1, weights['wc2'], biases['bc2']) 69 conv2 = maxpool2d(conv2, k=2) 70 # Fully connected layer 71 # Reshape conv2 output to fit fully connected layer input 72 fc1 = tf.reshape(conv2, [-1, weights['wd1'].get_shape().as_list()[0]]) 73 fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1']) 74 fc1 = tf.nn.relu(fc1) 75 fc1 = tf.nn.dropout(fc1, dropout) 76 77 out = tf.add(tf.matmul(fc1, weights['out']), biases['out']) 78 return out 79 80 with tf.device("/job:ps/task:0"): 81 x = tf.placeholder(tf.float32, [None, n_input]) 82 y = tf.placeholder(tf.float32, [None, n_classes]) 83 keep_prob = tf.placeholder(tf.float32) #dropout (keep probability) 84 85 weights = { 86 # 5x5 conv, 1 input, 32 outputs 87 'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])), 88 # 5x5 conv, 32 inputs, 64 outputs 89 'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])), 90 # fully connected, 7*7*64 inputs, 1024 outputs 91 'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])), 92 # 1024 inputs, 10 outputs (class prediction) 93 'out': tf.Variable(tf.random_normal([1024, n_classes])) 94 } 95 biases = { 96 'bc1': tf.Variable(tf.random_normal([32])), 97 'bc2': tf.Variable(tf.random_normal([64])), 98 'bd1': tf.Variable(tf.random_normal([1024])), 99 'out': tf.Variable(tf.random_normal([n_classes])) 100 } 101 102 with tf.device("/job:worker/task:0"): 103 pred = conv_net(x, weights, biases, keep_prob) 104 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y)) 105 # Evaluate model 106 correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) 107 accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) 108 with tf.device("/job:worker/task:1"): 109 pred2 = conv_net(x, weights, biases, keep_prob) 110 cost2 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred2, labels=y)) 111 cost3 = tf.add(cost,cost2) 112 optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost3) 113 # Evaluate model 114 correct_pred2 = tf.equal(tf.argmax(pred2, 1), tf.argmax(y, 1)) 115 accuracy2 = tf.reduce_mean(tf.cast(correct_pred2, tf.float32)) 116 accuracy3 = tf.add(accuracy2,accuracy) 117 # Initializing the variables 118 init = tf.global_variables_initializer() 119 # Launch the graph 120 with tf.Session("grpc://"+ps_hosts[0]) as sess: 121 sess.run(init) 122 step = 1 123 while step * batch_size < training_iters: 124 batch_x, batch_y = mnist.train.next_batch(batch_size) 125 sess.run(optimizer, feed_dict={x: batch_x, y: batch_y, 126 keep_prob: dropout}) 127 if step % display_step == 0: 128 loss, acc = sess.run([cost3, accuracy3], feed_dict={x: batch_x, 129 y: batch_y, 130 keep_prob: 1.}) 131 print("Iter " + str(step*batch_size) + ", Minibatch Loss= " + \ 132 "{:.6f}".format(loss) + ", Training Accuracy= " + \ 133 "{:.5f}".format(acc)) 134 step += 1 135 print("Optimization Finished!") 136 # Calculate accuracy for 256 mnist test images 137 print("Testing Accuracy:", \ 138 sess.run(accuracy, feed_dict={x: mnist.test.images[:256], 139 y: mnist.test.labels[:256], 140 keep_prob: 1.}))
Between-graph replication是最常用的方式,每个worker上都包含独立的client(都会调用一下tf.Session类)它们构建相同的计算图,然后把参数放在ps上,TensorFlow提供了一个专门的函数tf.train.replica_device_setter来构建Graph。
1 import tensorflow as tf 2 import numpy as np 3 # 创建集群信息,包括ps和worker两种角色。 4 # 集群有两类任务,ps和worker;ps由2个任务组成(一般一个任务是一个机器或者一个分配单元),worker由3个任务组成。 5 ps_hosts = ["xx.xxx.xx.xxxx:oooo", "xx.xxx.xx.xxxx:oooo"] 6 worker_hosts = ["xx.xxx.xx.xxxx:oooo", "xx.xxx.xx.xxxx:oooo", "xx.xxx.xx.xxxx:oooo"] 7 cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts}) 8 tf.app.flags.DEFINE_string("job_name", "worker", "One of 'ps', 'worker'") 9 tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job") 10 tf.app.flags.DEFINE_boolean("is_sync", False, "using synchronous training or not") 11 FLAGS = tf.app.flags.FLAGS 12 def main(): 13 server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index) 14 if FLAGS.job_name == "ps": 15 server.join() 16 else: 17 # 会根据job名,将with内的Variable op放到ps tasks,将其他计算op放到worker tasks。默认分配策略是轮询round-robin,按次序将参数挨个放到各个ps上,但这个方式可能不能使ps负载均衡,如果需要更加合理,可以采用tf.contrib.training.GreedyLoadBalancingStrategy策略。 18 with tf.device(tf.train.replica_device_setter( 19 worker_device="/job:worker/task:%d" % FLAGS.task_index, 20 cluster=cluster)): 21 x_data = tf.placeholder(tf.float32, [100]) 22 y_data = tf.placeholder(tf.float32, [100]) 23 W = tf.Variable(tf.random_uniform([1], -1.0, 1.0)) 24 b = tf.Variable(tf.zeros([1])) 25 y = W * x_data + b 26 loss = tf.reduce_mean(tf.square(y - y_data)) 27 global_step = tf.Variable(0, name="global_step", trainable=False) 28 optimizer = tf.train.GradientDescentOptimizer(0.1) 29 train_op = optimizer.minimize(loss, global_step=global_step) 30 # The StopAtStepHook handles stopping after running given steps. 31 hooks = [tf.train.StopAtStepHook(last_step=1000000)] 32 ##是否同步 33 if FLAGS.is_sync: 34 # asynchronous training 35 # use tf.train.SyncReplicasOptimizer wrap optimizer 36 # ref: https://www.tensorflow.org/api_docs/python/tf/train/SyncReplicasOptimizer 37 optimizer = tf.train.SyncReplicasOptimizer(optimizer, replicas_to_aggregate=FLAGS.num_workers, 38 total_num_replicas=FLAGS.num_workers) 39 # create the hook which handles initialization and queues 40 hooks.append(optimizer.make_session_run_hook((FLAGS.task_index==0))) 41 # The MonitoredTrainingSession takes care of session initialization, 42 # restoring from a checkpoint, saving to a checkpoint, and closing when done 43 # or an error occurs. 44 with tf.train.MonitoredTrainingSession(master=server.target, 45 is_chief=(FLAGS.task_index == 0), 46 # 我制定task_index为0的任务为主任务,用于负责变量初始化、做checkpoint、保存summary和复原 47 checkpoint_dir="/tmp/tf_train_logs", 48 save_checkpoint_secs=None, 49 hooks=hooks) as mon_sess: 50 while not mon_sess.should_stop(): 51 # Run a training step asynchronously. 52 # See `tf.train.SyncReplicasOptimizer` for additional details on how to 53 # perform *synchronous* training. 54 # mon_sess.run handles AbortedError in case of preempted PS. 55 train_x = np.random.rand(100).astype(np.float32) 56 train_y = train_x * 0.1 + 0.3 57 _, step, loss_v, weight, biase = mon_sess.run([train_op, global_step, loss, W, b], 58 feed_dict={x_data: train_x, y_data: train_y}) 59 if step % 100 == 0: 60 print("step: %d, weight: %f, biase: %f, loss: %f" % (step, weight, biase, loss_v)) 61 print("Optimization finished.") 62 if __name__ == "__main__": 63 tf.app.run()
Between-graph replication的另外一个问题,由于各个worker都独立拥有自己的client,但是对于一些公共操作(如模型参数初始化与checkpoint文件保存等),如果每个client都执行一遍,显然是对资源的浪费。为解决该问题,一般指定一个worker为chief worker,作为各个worker的管家,协调它们之间的训练,并且完成模型初始化和模型保存和恢复等公共操作。在TensorFlow中,可以使用tf.train.MonitoredTrainingSession创建client的Session,并且其可以指定哪个worker是chief worker。想深入理解,其中也对分布式TensorFlow的容错机制做了简单介绍。
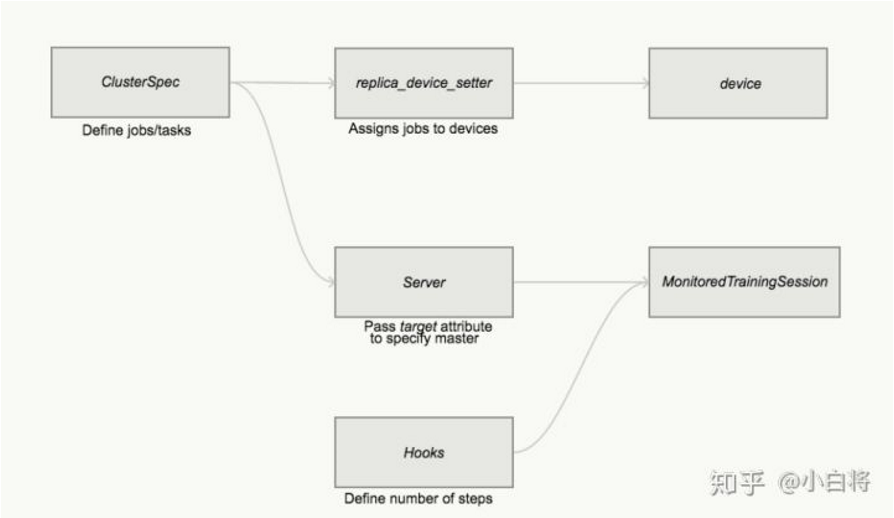
图20 Between-graph replication方式的编程结构图
低阶API创建parameter server集群缺点:
- 概念多,学习曲线陡峭。
- 单机代码到多机修改的代码量大。
- 需要多台机子跑不同的脚本,当然这可以通过k8s集群管理工具来解决。
- PS 和 Worker 的比例不好选取。(建议选取偶数个的ps,我的经验是ps和worker的比例是1:3)
- 训练速度性能损失较大。(通信代价较高)
parameter server常见的优化点:
- 如果有参数量较大的embedding变量时,可选择使用embedding_lookup_sparse_with_distributed_aggregation函数替代tf.nn.embedding_lookup_sparse函数。该函数可将embedding的聚合计算都放在变量所在的PS端,计算后转成稠密张量再传送到Worker上继续网络模型的计算。
- tf.device函数中有一个参数是设置变量在ps端放置策略的,可使用tf.contrib.training.GreedyLoadBalancingStrategy来替代默认的轮循。优点是:可根据参数的内存字节来完成类似在线垃圾收集的工作。根据weight和bias的字节数来放置到内存合适的task中,带来更好的负载平衡。
- 当参数有超大量级时(比如embedding参数),可在创建变量的时候使用分割变量策略:partitioner=tf.fixed_size_partitioner(ps_nums)
- 优化input pipeline。链接:https://www.tensorflow.org/guide/performance/datasets
- bandwidth高带宽范亲和策略,保证多个ps分布在不同的物理机上。
Tensorflow实现Ring-AllReduce
参考资料:
1.https://zhuanlan.zhihu.com/p/81784947
2.https://zhuanlan.zhihu.com/p/82116922
3.https://zhuanlan.zhihu.com/p/79030485
4.https://zhuanlan.zhihu.com/p/35083779
5.https://github.com/tensorflow/examples/blob/master/community/en/docs/deploy/distributed.md

 浙公网安备 33010602011771号
浙公网安备 33010602011771号