

HiveServer2的ActivePassive高可用与常见高可用浅析
负载均衡的高可用
最近在工作中遇到了hiveserver2需要部署高可用的场景,去网上搜索了解过后,用了绝大多数人推荐的共同方法:
| Property_name | Property_value | Description |
|---|---|---|
| hive.server2.support.dynamic.service.discovery | true(默认false) | 使hiveserver2服务可被动态发现 |
| hive.server2.zookeeper.namespace | hiveserver2(默认值) | hiveserver2实例在zk中注册的znode名 |
| hive.zookeeper.client.port | 2181(默认值) | zk端口 |
| hive.zookeeper.quorum | zk1:2181,zk2:2181,zk3:2181(默认空) | zk集群连接方式 |
当如上配置后,启动的hiveserver2实例都会注册到zk的/hiveserver2节点下,如下所示
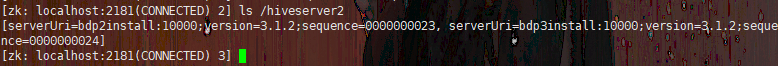
get一下其中一个实例,就会发现它包含了这个hs2的uri、端口号等连接配置,如下所示

此时用客户端(如beeline)连接hs2时,url需使用
jdbc:hive2://zk1:2181,zk2:2181,zk3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
此时zk会随机从多个实例中随机拿一个实例供连接使用,过程在代码中体现如下:
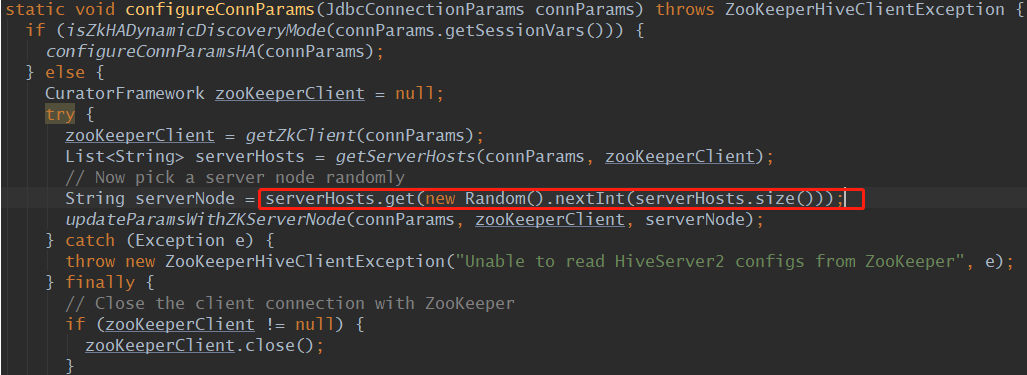
先去指定的znode(/hiveserver2)下拿到所有实例,再通过Random随机拿其中一个去连接;也正因为这个随机的过程,此种方式的hs2高可用一定程度上实现了hiveserver2的负载均衡。
问题
但这种方式的高可用在使用中存在一个问题,即当你同时开启了鉴权的服务(如ranger),hs2在启动时不仅会注册hs2的实例,还会注册一个leader节点,如下所示

从图中可以看出,leader节点下有两个子节点,而每个子节点实际没有任何内容,因为这个leader节点在此处没有用处。
但因为leader节点的存在,使上面讲的随机拿的过程中就可能会拿到这个leader节点,而该节点实际不是有效的hs2实例,故此时连接会报错“Unable to read HiveServer2 configs from ZooKeeper”.
那么Leader节点为什么会产生呢?我们看下源码里对应的部分

而目前还没有发现leader节点的具体作用,只会在从zk拿实例时徒增报错。
为了解决此问题,我重新编译了hive-jdbc的源码,在从zk拿实例的过程中过滤掉了leader节点。
能解决此问题的,还有另一种方式,即配置ActivePassiveHA。
ActivePassiveHA
探究源码过程中,发现hive还提供了另一种高可用方案,即ActivePassiveHA,开启需如下配置:
| Property_name | Property_value | Description |
|---|---|---|
| hive.server2.support.dynamic.service.discovery | true(默认false) | 使hiveserver2服务可被动态发现 |
| hive.server2.active.passive.ha.enable | true(默认false) | ActivePassiveHA启用 |
| hive.server2.active.passive.ha.registry.namespace | hs2ActivePassiveHA(默认值) | hiveserver2实例及leader在zk中注册的znode名 |
| hive.zookeeper.quorum | zk1:2181,zk2:2181,zk3:2181(默认空) | zk集群连接方式 |
| hive.zookeeper.client.port | 2181(默认值) | zk端口 |
当如上配置后,启动的hiveserver2实例都会注册到zk的/hs2ActivePassiveHA节点下,如下所示

由图可见,其本质还是和上面类似的注册实例的过程相似,但注册的实例统一放在了instances下面,且注册时信息更详细;而单独产生的_LEADER节点则将两个实例中的registry.unique.id拿出单独放置。(hs2ActivePassiveHA后的unsecure或secure是根据是否开启身份验证或鉴权后自动添加的)
而ActivePassiveHA和上述高可用方案最大的区别,就是通过_LEADER节点分配可连接实例中的"leader"和"worker",当leader没有挂掉的时候,所有通过zk连接到hs2的连接都会指向leader节点,而不会连接到其他节点,与上述高可用方案的随机方式有一定区别。
此时,连接的url需使用
jdbc:hive2://zk1:2181,zk2:2181,zk3:2181/;serviceDiscoveryMode=zooKeeperHA;zooKeeperNamespace=hs2ActivePassiveHA
这种高可用方案同时解决了另一个问题:java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfiguration,如下所示
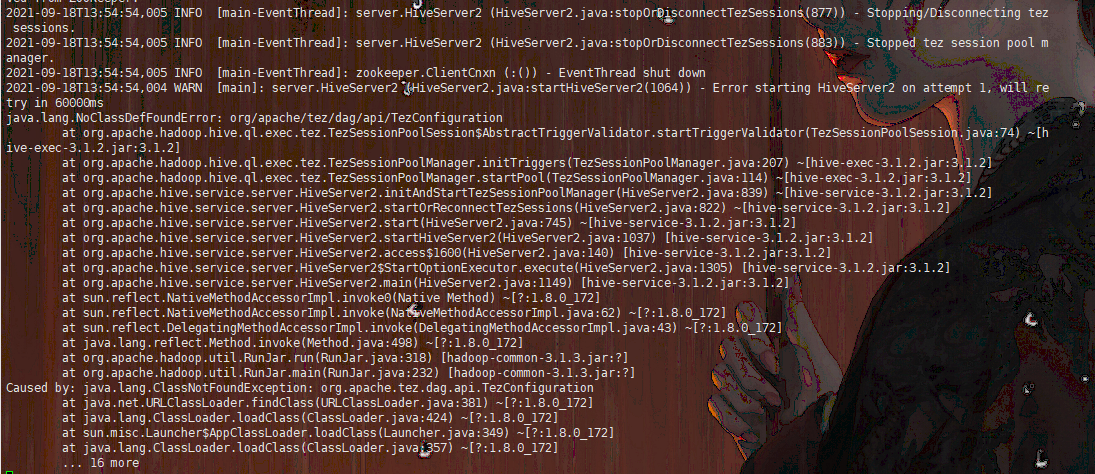
这问题出现在hs2启动过程中,因为对hive3来说mr引擎已经是过时的,所以无论你的hive执行引擎选的是什么,都会在启动hs2时自动启动一个TezSession,但如果你在hive-env.sh中没有配置tez包的位置,这里就会报ClassNotFound,并且强制等待60s后重试,重试后不管成功还是失败都会继续向下执行,不影响正常启动,但拖慢了hs2启动的时间。本来十几秒就能解决的事非要等待一分多钟才行。
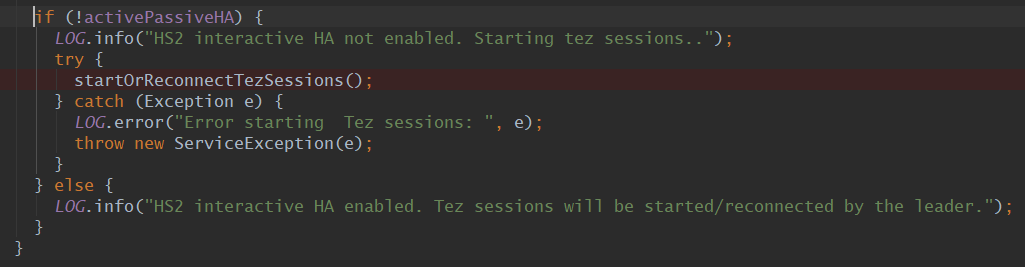
但当开启了ActicePassiveHA后,这个启动TezSession的过程就会变成此处暂不启动,后续由leader自行启动,代码如下:
问题
此种高可用方案在hive官网和网络上的帖子中几乎没有被提及,是在hs2启动时跟源码发现的,目前发现存在一些问题:
- 此种方式的高可用在leader节点没有挂掉的情况下会始终连接leader节点,只有在leader不可用时才会自动切换,类似hadoop的Actice/Standby方案,但这样只能做到故障切换,没有做到负载均衡(这种方式在代码中是否有另外一套负载均衡的机制还有待探究)
- url中serviceDiscoveryMode=zooKeeperHA的连接方式不被一些鉴权服务所支持(如ranger)
本文首发于博客园,作者榆天紫夏,希望对大家有所帮助。如有遗漏或问题欢迎补充指正
本文来自博客园,作者:榆天紫夏,转载请注明原文链接:https://www.cnblogs.com/yutianzixia/p/15308698.html

