归并排序算法理解
归并排序算法简介
归并排序就是利用归并的思想实现的排序方法
假设初始序列含有n个记录,看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到 |n/2|(|x|表示不小于x的最小整数)个长度为2或1的有序子序列;再两两归并,如此重复,直至得到一个长度为n的有序序列为止,这种排序方法称为2路归并排序
归并排序算法的递归实现
MSort()函数
//对顺序表L作归并排序(此函数的作用就是进行一次封装,达到统一接口的效果)
void MergeSort(SqList *L){
MSort(L->r, L->r, 1, L->length);
}
//将SR[s..t]归并排序为TR1[s..t]
void MSort(int SR[], int TR1[], int s, int t){
int m;
int TR2[MAXSIZE + 1];
//递归结束条件
if (s == t)
TR1[s] = SR[s];
else{
//将SR[s..t]平分为SR[s..m]和SR[m+1..t]
m = (s + t) / 2;
//递归将SR[s..m]归并为有序的TR2[s..m]
MSort(SR, TR2, s, m);
//递归将SR[m+1..t]归并为有序TR2[m+1..t]
MSort(SR, TR2, m + 1, t);
//将TR2[s..m]和TR2[m+1..t] 归并到TR1[s..t]
Merge(TR2,TR1, s, m, t);
}
}
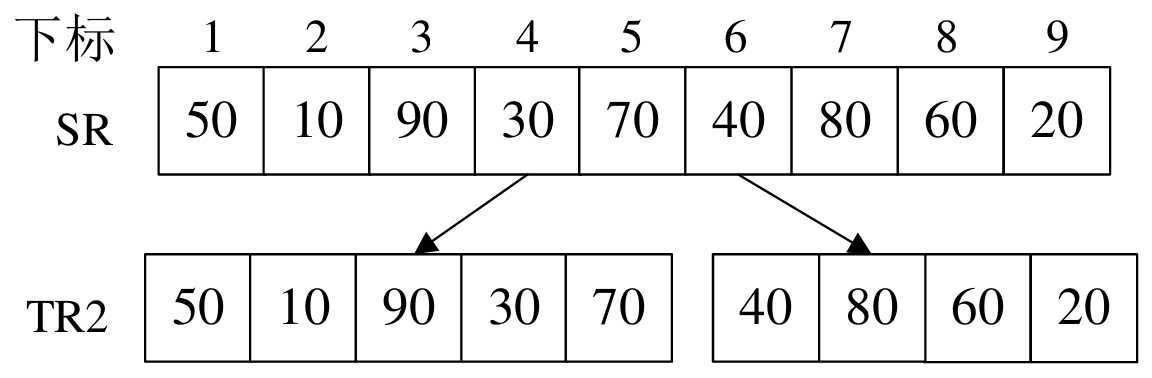
假设对数组{50,10,90,30,70,40,80,60,20}进行排序,L.length=9
则第一次调用MSort()函数的时候(还未进行递归),我们将原数组分成了两个部分
-
“MSort(SR,TR2,1,5):是将数组SR中的第1~5的关键字归并到有序的TR2(调用前TR2为空数组)
-
“MSort(SR,TR2,6,9):是将数组SR中的第6~9的关键字归并到有序的TR2
如下图所示:
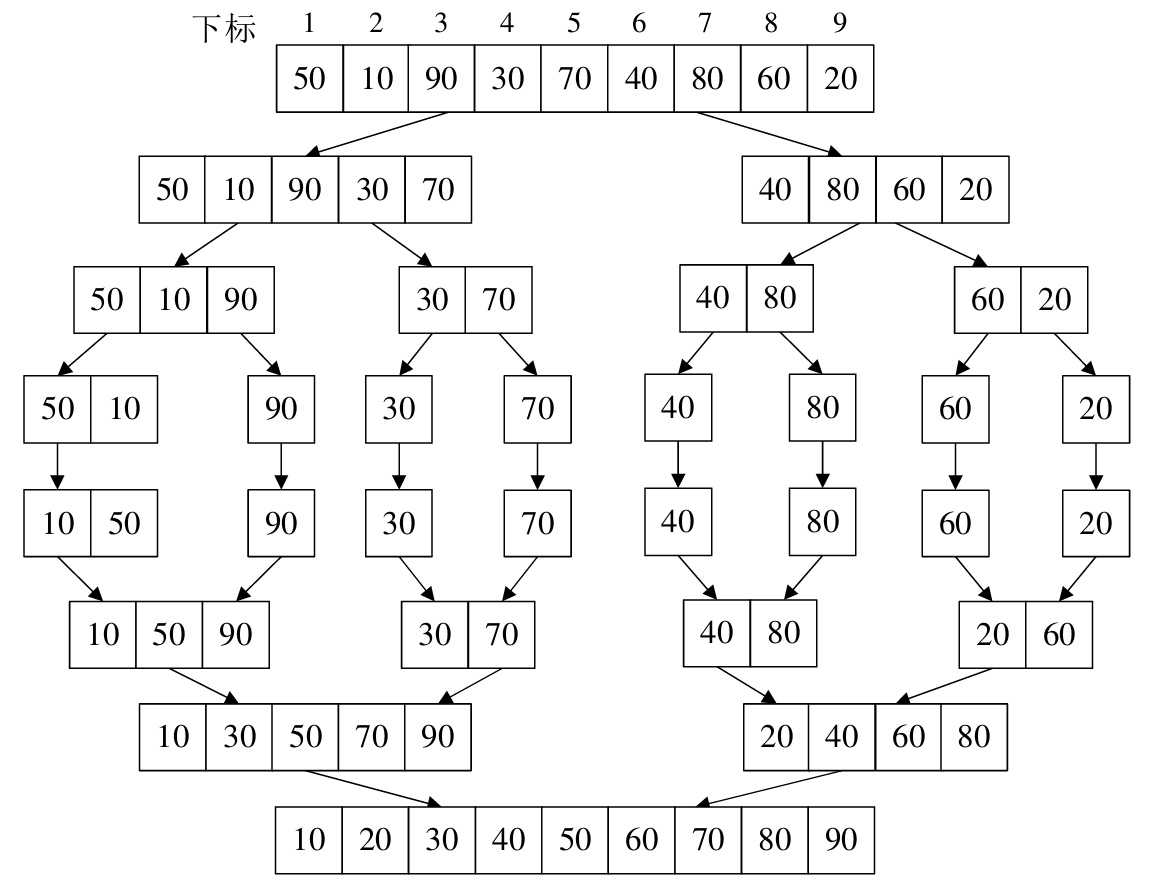
接下来,将进行不断的递归深入,直到满足s==t的递归结束条件,也就是划分的每个部分只剩下一个元素
然后一层一层退出迭代,每次退出一层迭代,就会调用一次Merge()函数,将TR2数组的两个部分归并为一个TR1数组
整个过程如下图所示:
在理解了整体的算法流程之后,我们再看一下Merge()函数的实现
Merge()函数
//将有序的SR[i..m]和SR[m+1..n]归并为有序的TR[i..n]
void Merge(int SR[], int TR[], int i, int m, int n){
int j, k, l;
//将SR中记录由小到大归并入TR
for (j = m + 1, k = i; i <= m && j <= n; k++){
if (SR[i] < SR[j])
TR[k] = SR[i++];
else
TR[k] = SR[j++];
}
if (i <= m){ //将剩余的SR[i..m]复制到TR
for (l = 0; l <= m - i; l++)
TR[k + l]=SR[i + l];
}
if (j<=n){ //将剩余的SR[j..n]复制到TR
for (l = 0; l <= n - j; l++)
TR[k + l] = SR[j + l];
}
}
注意在该函数中:
-
i为SR数组前一部分的索引 -
j为SR数组后一部分的索引 -
k为TR数组(归并目标数组)的索引
前面已经提到,每次退出一层递归,都会调用一个归并函数Merge(),将两个部分的数组归并为一个数组
这里我们只解释最后一次归并,也就是最复杂的一次归并
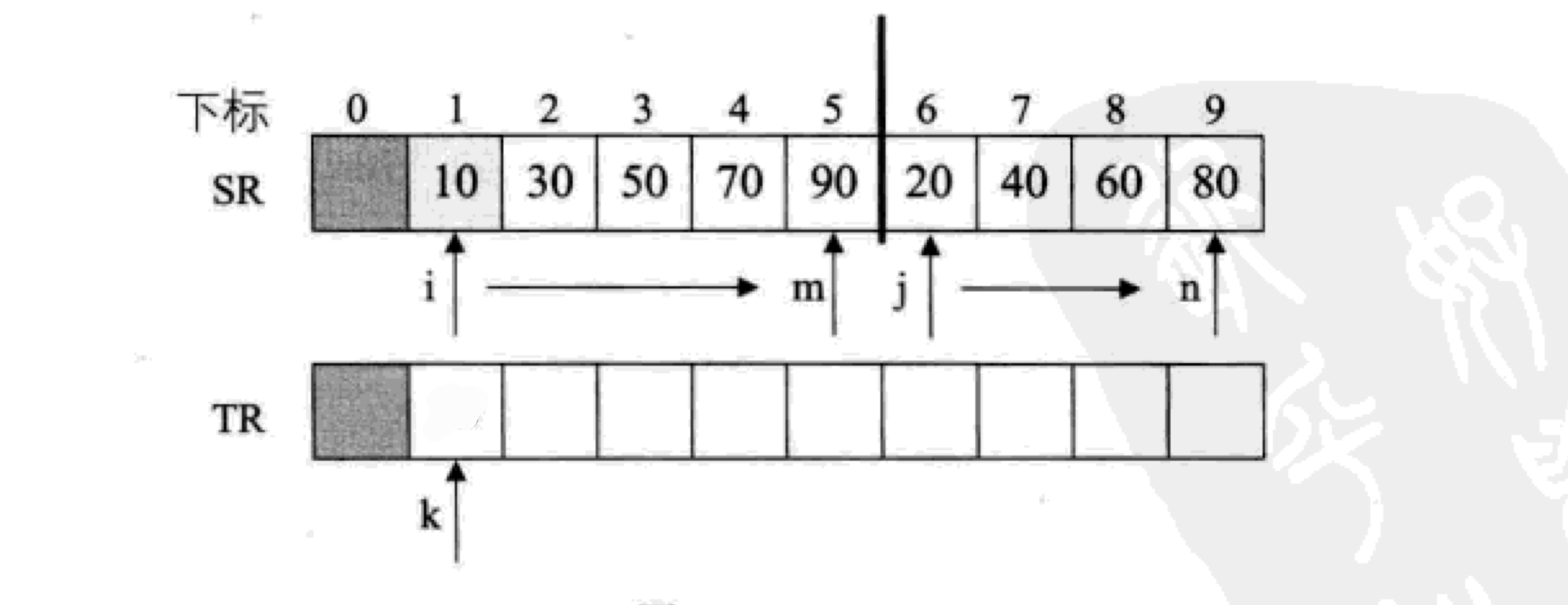
最后一次递归调用的Merge是将{10,30,50,70,90}与{20,40,60,80}归并为最终有序的序列
因此数组SR为{10,30,50,70,90,20,40,60,80},i=1,m=5,n=9
如图所示:
首先,该函数的第一个for循环负责将SR数组的前后两个部分的元素,按照顺序(逐个比较)进行归并
例如第一次归并的操作:
- SR[i]=SR[1]=10,SR[j]=SR[6]=20,TR[k]=TR[1]=10,并且i++
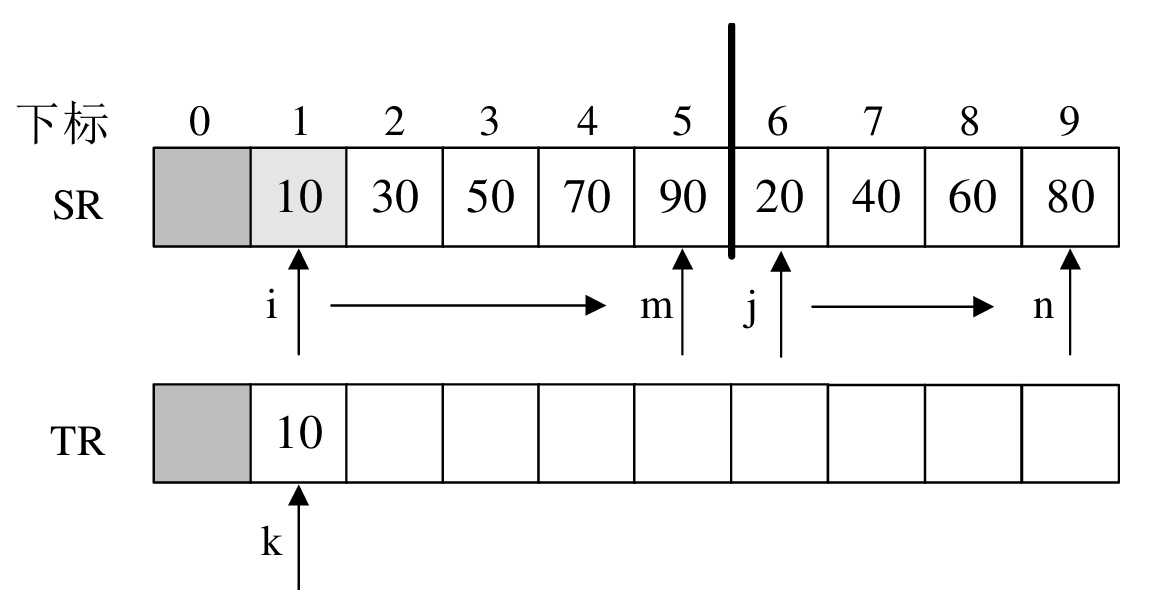
如此循环,直至i或j越界( i>m 或 j>n )
一旦这两个部分有一个部分越界之后,说明这个部分的元素已经完成了归并
则接下来我们需要将另一个部分的未归并的剩余元素直接复制到TR[]中
如下图展示了后半部分先归并完成的情况:
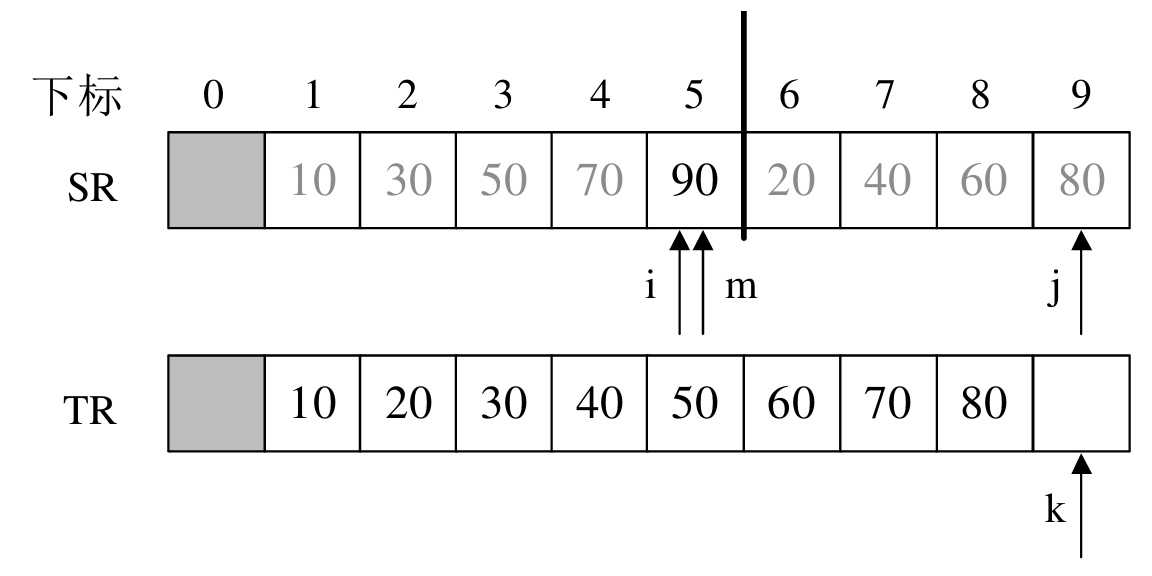
最后,将归并剩下的数组数据,移动到TR的后面:
当前k=9,i=m=5,for循环l=0,TR[k+l]=SR[i+l]=90,完成归并排序,如下图所示:

递归实现归并排序算法总结
由于归并排序在归并过程中需要与原始记录序列同样数量的存储空间存放归并结果以及递归时深度为log2n(2为底)的栈空间
因此空间复杂度为O(n+logn)
Merge函数中if(SR[i] < SR[j])语句说明需要两两比较,不存在跳跃,因此归并排序是一种稳定的排序算法
归并排序是一种比较占用内存,但却效率高且稳定的算法
归并排序算法的非递归实现
《大话数据结构》中的实现方式:
MergeSort2()函数
//对顺序表L作归并非递归排序
void MergeSort2(SqList *L){
//申请额外空间
int * TR = (int *)malloc(L->length * sizeof(int));
int k = 1;
while (k < L->length){
MergePass(L->r, TR, k, L->length);
//子序列长度加倍
k = 2 * k;
MergePass(TR, L->r, k, L->length);
//子序列长度加倍
k = 2 * k;
}
}
以上是非递归实现的归并排序算法的主体函数,其实现方式是使用L->r数组和TR数组互相进行两两归并算法
如下图所示,并以此类推:
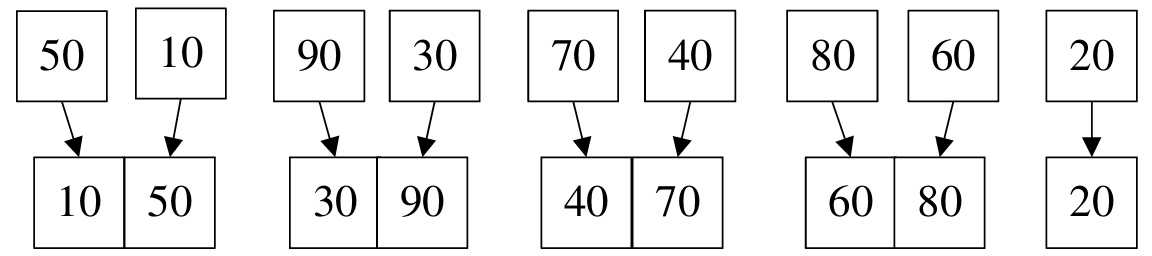
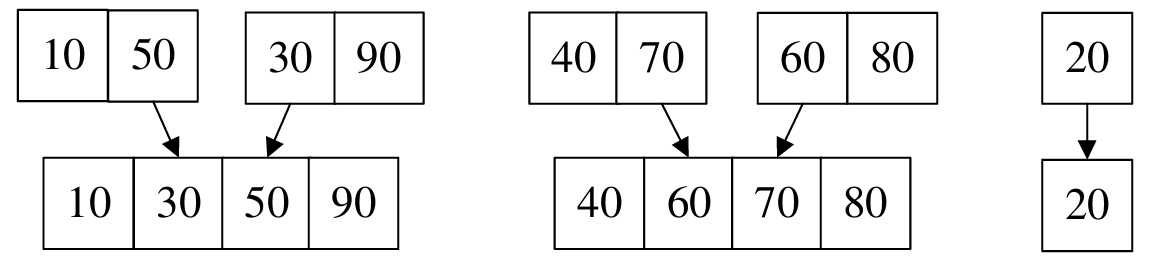
每次归并完成之后,将归并的子序列长度x2,直至结束
其核心函数为MergePass()函数,接下来看它的实现方式
MergePass()函数
//将SR[]中相邻长度为s的子序列两两归并到TR[]
void MergePass(int SR[], int TR[], int s, int n){
int i = 1;
int j;
while (i <= n - 2 * s + 1){
//两两归并
Merge(SR, TR, i, i + s - 1, i + 2 * s - 1);
i = i + 2 * s;
}
//归并最后两个序列
if (i < n - s + 1)
Merge(SR, TR, i, i + s - 1, n);
//若最后只剩下单个子序列
else
for (j = i; j <= n; j++)
TR[j] = SR[j];
}
首先,第一次调用MergePass(L.r,TR,k,L.length)函数的时候:
- L.r是初始无序状态,TR为新申请的空数组,k=1,L.length=9
问:为什么while的条件是i<=n-2s+1?
答:因为下面调用Merge()函数时,将两个部分进行归并,而其中的后一部分的结尾下标为:i+2s-1,因此若i>n-2s+1则有i+2s-1>n,会导致数组越界
这样第一次调用这个函数时,两两归并的范围限于1-8,9号元素会被剩下来
对于这种多余的元素,我们再判断,i+s-1(这是用来归并的前一部分的终点)是否小于n:
-
若
i+s-1<n,说明归并的前一部分的终点并未到达n,则可以继续归并,移相得:i<n-s+1,则进入if分支,继续调用Merge()函数进行归并 -
若
i+s-1>=n,说明若继续归并,则归并的前一部分的终点已经达到n,则无法归并,进入else分支,可以直接将剩余部分的元素复制到TR数组
注意:Merge(int SR[], int TR[], int i, int m, int n)
-
i值指前一部分的开始下标
-
m值指前一部分的结束下标(后一部分从m+1开始)
-
n值为后一部分的结束下标
非递归实现归并排序算法总结
非递归的迭代方法,避免了递归时深度为log2n(2为底)的栈空间,空间只是用到申请归并临时用的TR数组,空间复杂度为O(n),避免递归在时间性能上也有一定的提升
应该说,使用归并排序算法时,尽量考虑使用非递归方法
另一种非递归实现方式(来自小甲鱼数据结构视频教程)
注释十分详细,不再讲解
#include<stdio.h>
#include<stdlib.h>
#define MAXSIZE 10
void MergeSort(int k[],int n){
//next是用来标志temp数组下标的
int i,next;
//每次归并都是对两段数据进行对比排序
//left\right分别代表左面和右面(前面和后面)的两段数据
//min和max分别代表各段数据的最前和最后下标
int left_min,left_max,right_min,right_max;
//申请一段内存用于存放排序的临时变量
int *temp = (int *)malloc(n * sizeof(int));
//步长:i;从步长=1开始逐级递增
for(i=1; i<n; i*=2){
//每次步长递增,都从头开始归并处理
for(left_min=0; left_min<n-i; left_min = right_max){
//两段数据和步长之间关系
right_min = left_max = left_min + i;
right_max = left_max + i;
//最后的下标不能超过n,否则无意义
if(right_max>n)
right_max = n;
//每次的内层循环都会将排列好的数据返回到K数组,因此next指针需每次清零
next = 0;
//两端数据均未排完
while(left_min<left_max&&right_min<right_max){
if(k[left_min] < k[right_min])
temp[next++] = k[left_min++];
else
temp[next++] = k[right_min++];
}
//上面的归并排序循环结束后,可能有一段数据尚未完全被排列带temp数组中
//剩下未排列到temp中的数据一定是按照升序排列的最大的一部分数据
//此时有两种情况:left未排列完成,right未排列完成
//若是left未排列完成(left_min<left_max),则对于这一段数据省去temp数组的中转,直接赋值到k数组,即从right_max开始倒着赋值
//若是right未排列完成,则可以想到,那一段数据本就在应该放置的位置,则无需处理
while(left_min < left_max)
//上面分析应该从right_max开始倒着赋值,但是实际因为右边的数据段已经全部排列
//故此时right_min=right_max
//且这里将right_min移动到需要的位置,方便下面赋值时使用
k[--right_min] = k[--left_max];
while(next>0)
//把排列好的数据段赋值给k数组
//这里可以直接用上面经过--right_min倒数过来的right_min值
//经过上面倒数的处理,right_min恰好在需要赋值和不需要赋值的数据段的分界处
k[--right_min] = temp[--next];
}
}
}
//测试
int main(){
int i,a[10] = {5,2,6,0,3,9,1,7,4,8};
MergeSort(a,10);
printf("排序后的结果是:");
for(i=0; i<10; i++)
printf("%d",a[i]);
printf("\n\n");
return 0;
}

