堆排序算法理解
堆排序算法用到的大顶堆/小顶堆
以使用大顶堆的堆排序算法为例,其实堆排序算法的原理就是不断将剩余的未完成排序的数据构造成一个大顶堆,然后每次将大顶堆的堆顶元素(也就是最大的元素)取出,如此循环即完成了堆排序。
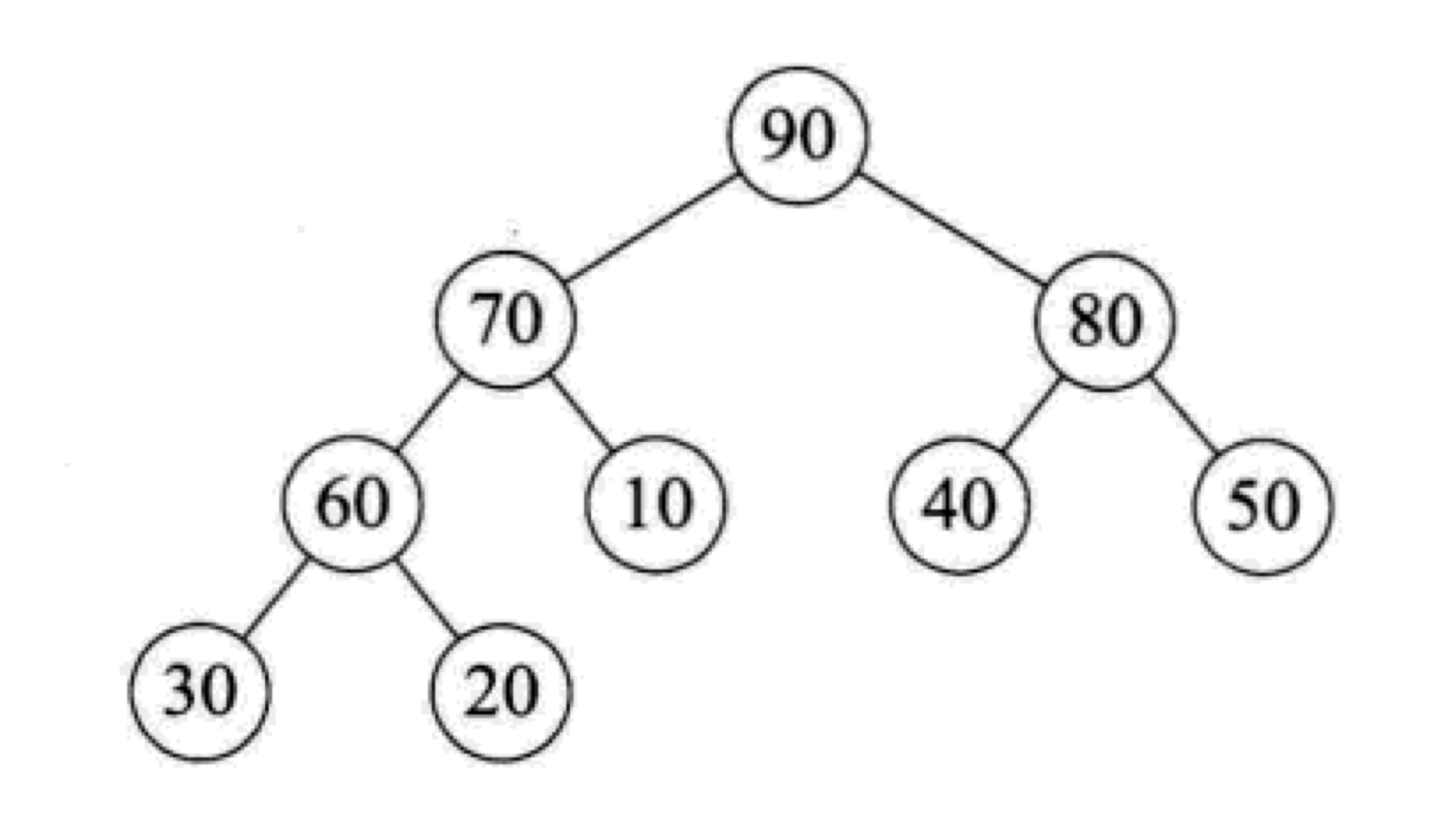
大顶堆:每个结点的值都大于或等于其左右孩子结点的值,如下图所示,就是一个大顶堆:
堆排序算法HeapSort()函数
void HeapSort(SqList *L){
int i;
//把L中的r构建成一个大顶堆
for (i = L->length / 2; i > 0; i--)
HeapAdjust(L, i, L->length);
for (i = L->length; i > 1; i--){
//将堆顶记录和当前未经排序子序列的最后一个记录交换
swap(L, 1, i);
//将L->r[1..i-1]重新调整为大顶堆
HeapAdjust(L, 1, i - 1);
}
}
从上面的代码可以看出,堆排序算法整体可以分为两个部分,也就是两个for循环:
- 第一个循环是要将现在的待排序序列构建成一个大顶堆
- 第二个循环是要逐步将每一个最大的根结点与末尾元素进行交换,并且再将剩余部分调整成为一个大顶堆
第一个for循环
首先,第一个for循环的i为什么是从length/2开始的呢?(如果是一个长度为9的序列,则是从4开始,逐渐递减:4->3->2->1)
答案就在下图中,根据完全二叉树的性质,序号 ≤ length/2的结点一定是双亲结点(一定有孩子)
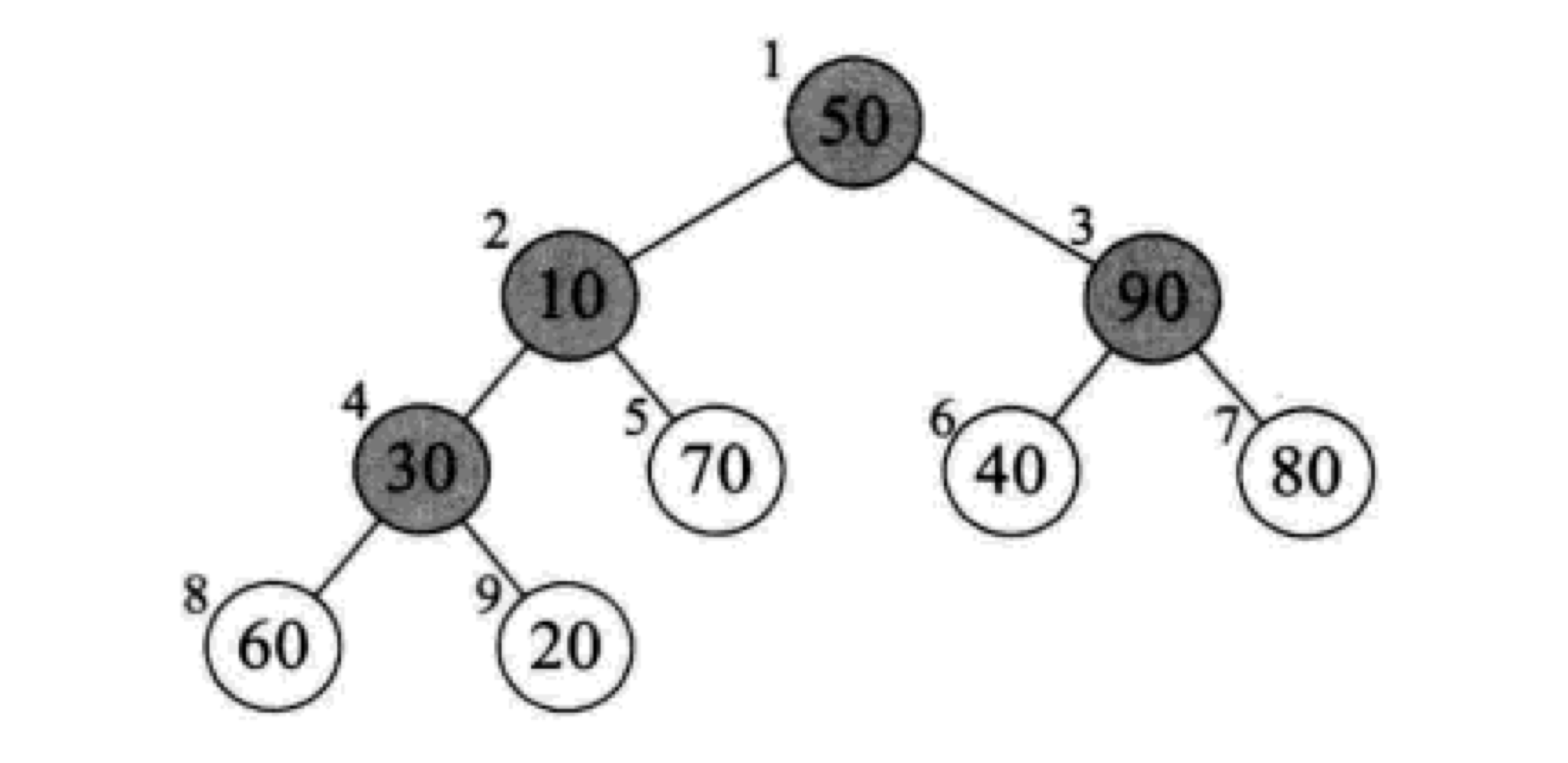
我们所谓的将待排序的序列构建成为一个大顶堆,其实就是从下往上、从右到左,将每一个非终端结点(非叶子结点)当作根节点,将其和其子树调整成大顶堆。在上图的例子中,i就是按照4->3->2->1的顺序变化,也就是依次调整4、3、2、1结点为根节点的子树。
将循环的逻辑搞明白之后,我们知道,在for循环的循环体中,还需要实现将子树调整为大顶堆的功能,那么接下来,我们就应该深入了解一下循环体中的HeapAdjust()函数的实现方式了。
堆排序算法HeapAdjust()函数解读
//已知L->r[s..m]中记录的关键字除L->r[s]之外均满足堆的定义,本函数调整L->r[s]的关键字,使L->r[s..m]成为一个大顶堆
void HeapAdjust(SqList *L,int s,int m){
int temp, j;
//在一个for循环中,temp的值不会改变,总是第一个r[i]的值(在后面提到的连续轮换中要注意这一点)
temp = L->r[s];
//沿关键字较大的孩子结点向下筛选
for (j = 2 * s; j <= m; j *= 2){
if (j < m && L->r[j] < L->r[j + 1]) //j为较大的孩子的下标
++j; //右孩子更大则选择右孩子
//s位置为最大值,则直接跳出循环(已经是大顶堆)
if (temp >= L->r[j])
break;
//将较大值放到s位置
L->r[s] = L->r[j];
//将s也赋值为j,为了更深层子树若不符合大顶堆,可以继续深入下去(也就是这个for循环继续下去)
//也是为了找到下面temp值插入的位置:每次用j位置的值取代s位置,s位置就保留下来等待temp插入
s = j;
}
//将最开始的s位置的值(保存在temp中)插入
L->r[s] = temp;
}
第一次循环 s = 4
初始状态的二叉树如图:
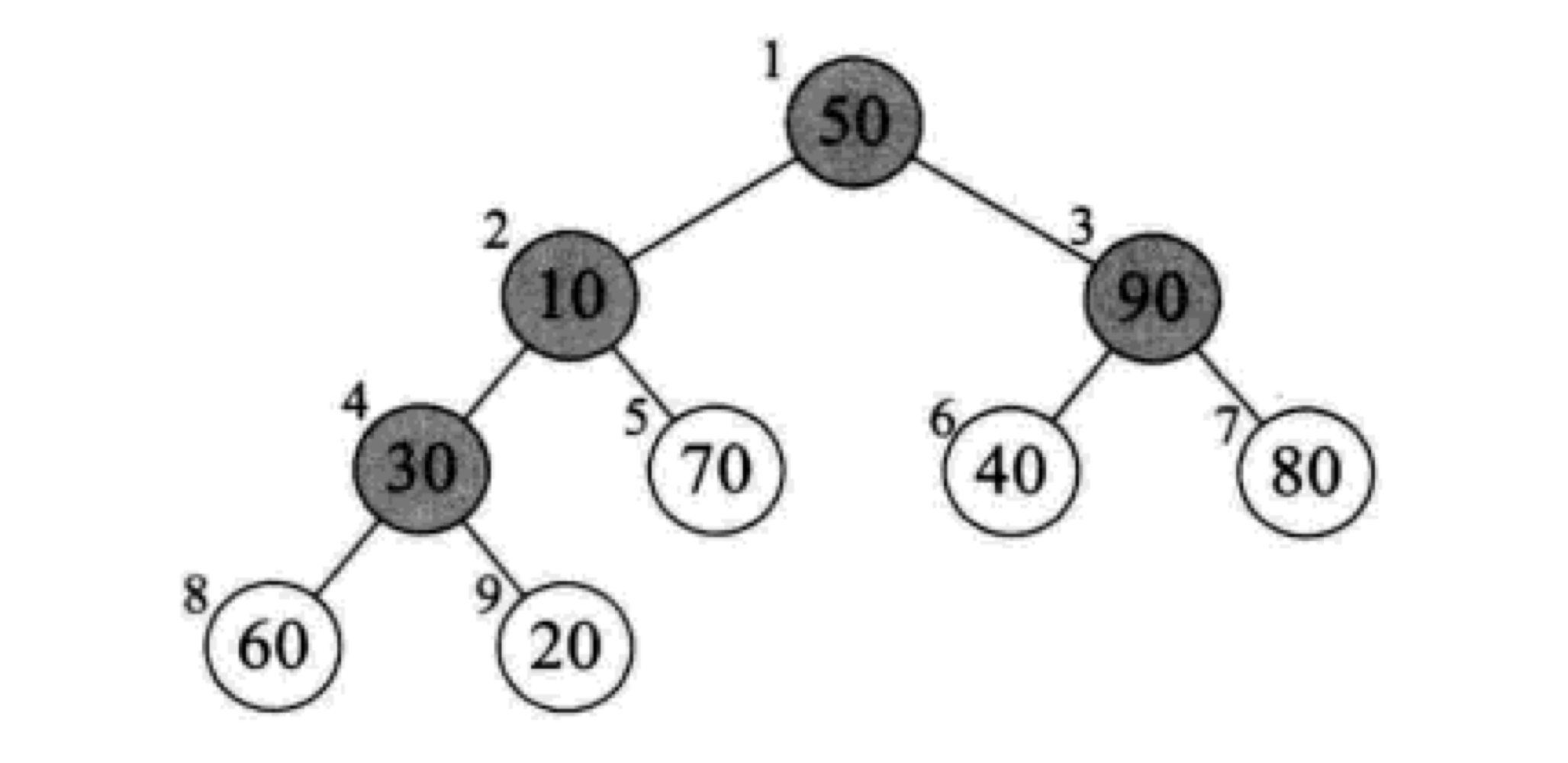
这次循环进行调整的是结点4,8,9组成的小子树(temp = r[4] = 30)
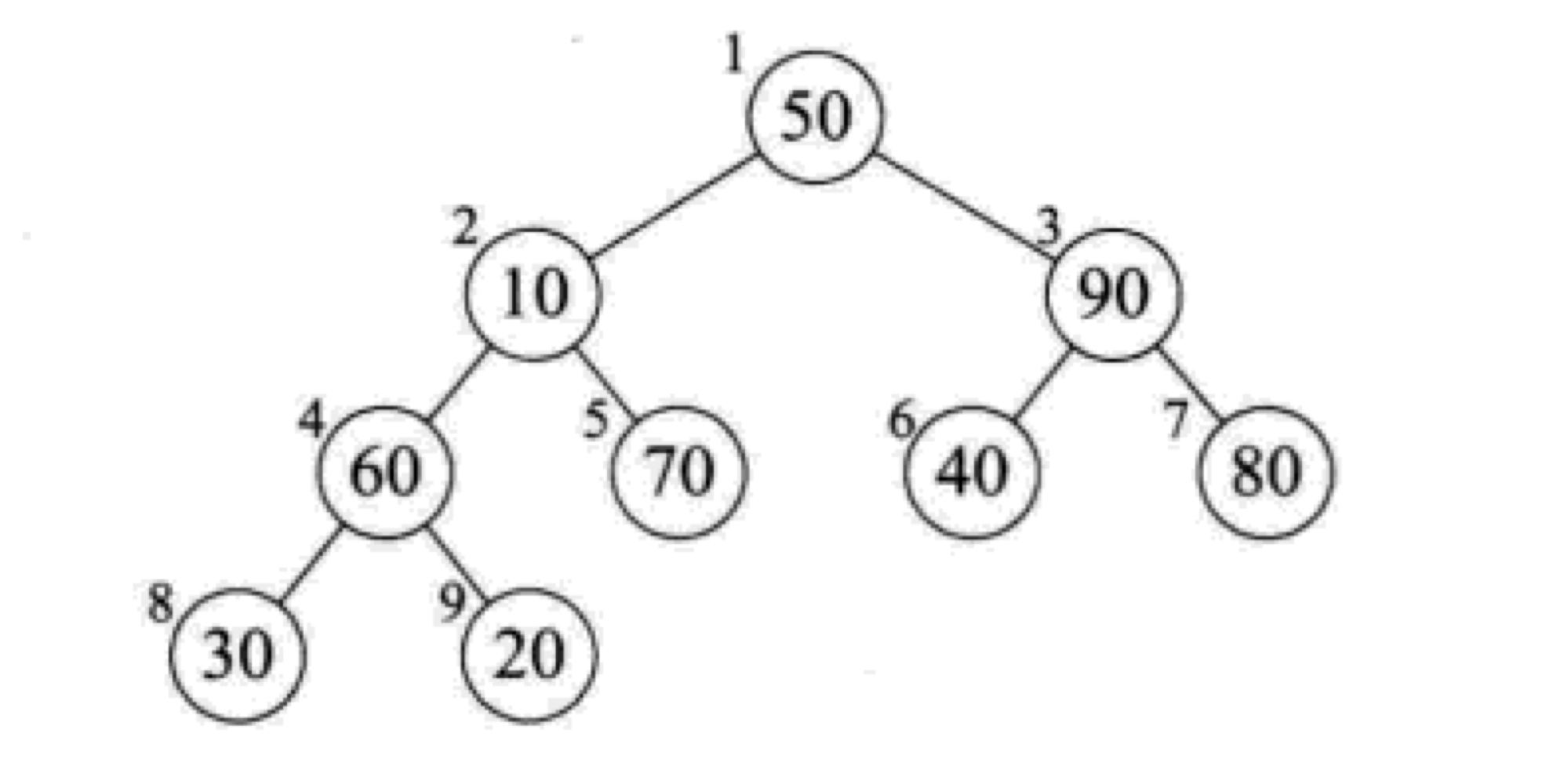
j选中较大的孩子结点(8结点),然后将8结点的值赋给4结点,最后将temp的值插入到r[8]
第一次循环之后的结果如下图:
第二次循环 s = 3
对以3结点为根节点的子树进行调整,此次循环并没有发生什么变化
第三次循环 s = 2
对以2结点为根节点的子树进行调整,此次循环之后将2结点和5结点进行交换,循环后的结果:
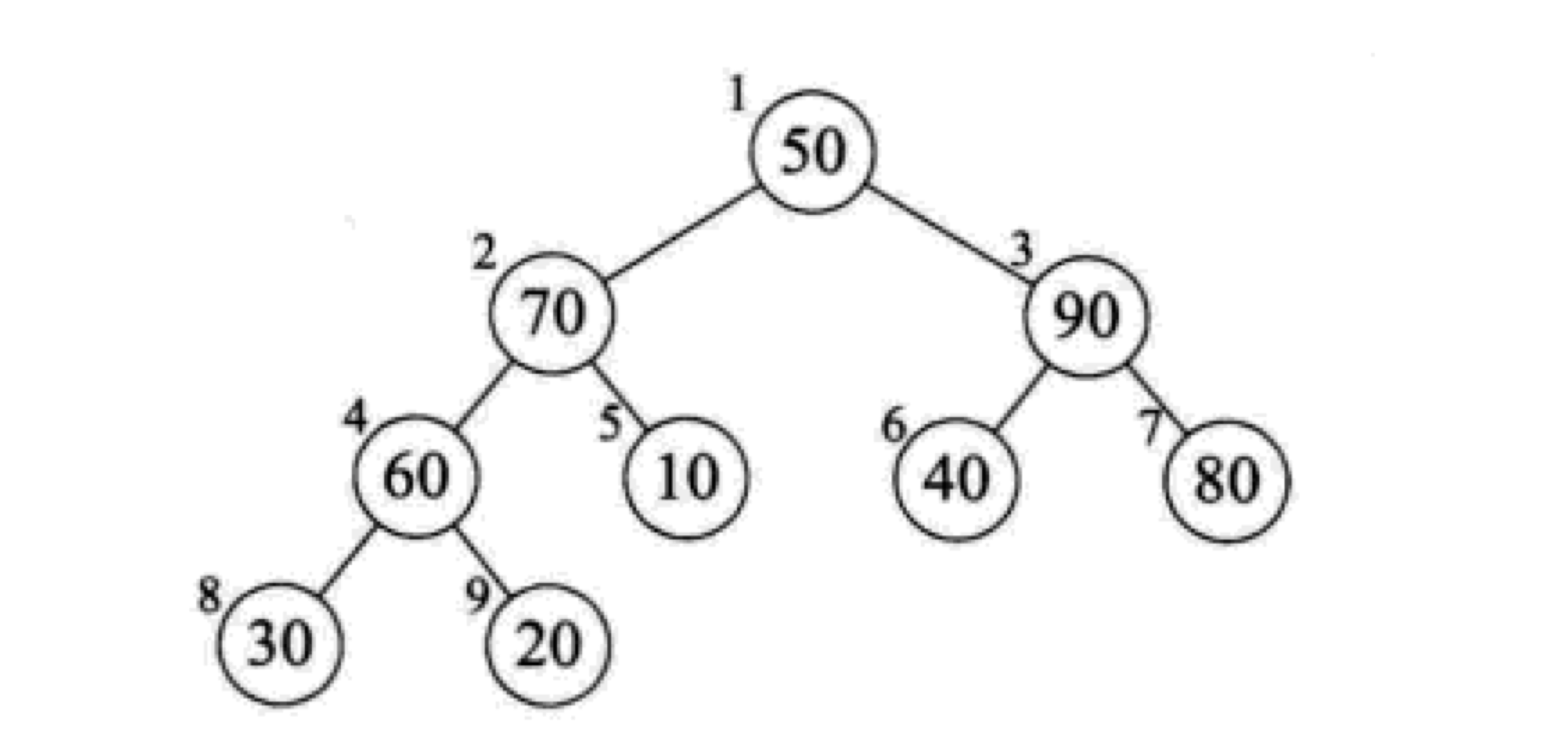
第四次循环 s = 1
对以1结点为根节点的子树进行调整,此次循环中操作对象不仅限于1,2,3三个结点
本次循环一共可以分为三个步骤进行理解,如下图所示:
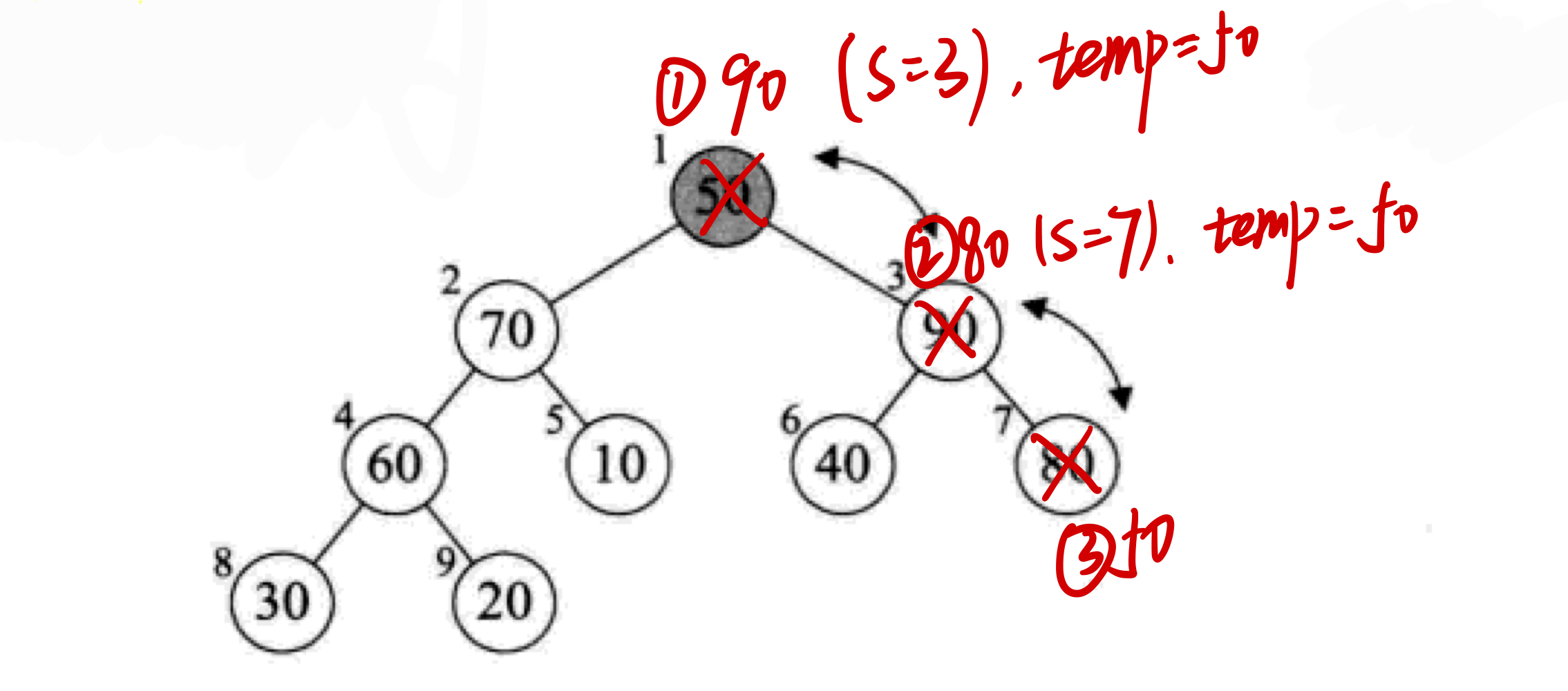
-
首先保存temp为1结点的值50,然后在1,2,3结点中进行调整,由于3结点的值为90,最大,因此将1结点赋值为90,此时s的值也修改为3
-
接下来由于s=3,则对3,6,7三个结点进行调整,由于7结点的值为80,最大(注意这里在3结点的两个孩子中,7结点最大,另外,在对三个结点进行调整的时候,较大的孩子需要与temp进行比较,80显然大于temp),因此我们将7结点的值赋给3结点(要避免一个误区:是将较大的孩子与temp对比,而不是与双亲结点对比,否则我们发现7结点为80,3结点为90,则不需要赋值,但是实际上,3结点的90已经赋给1结点,3结点临时继承了1结点的值吗,也就是temp=50),此时s的值也修改为7
-
将temp值插入7号结点,即完成了此次循环的调整,此次循环调整的是以1结点为根节点的子树,其实就是整棵树,可能在调整上层子树的时候会影响到下层的,因此我们有时需要深入到下层的子树进行调整(如此例一样,我们使得50,90,80进行了连续轮换)
至此,我们完成了大顶堆的构建过程,最终调整的结果为:
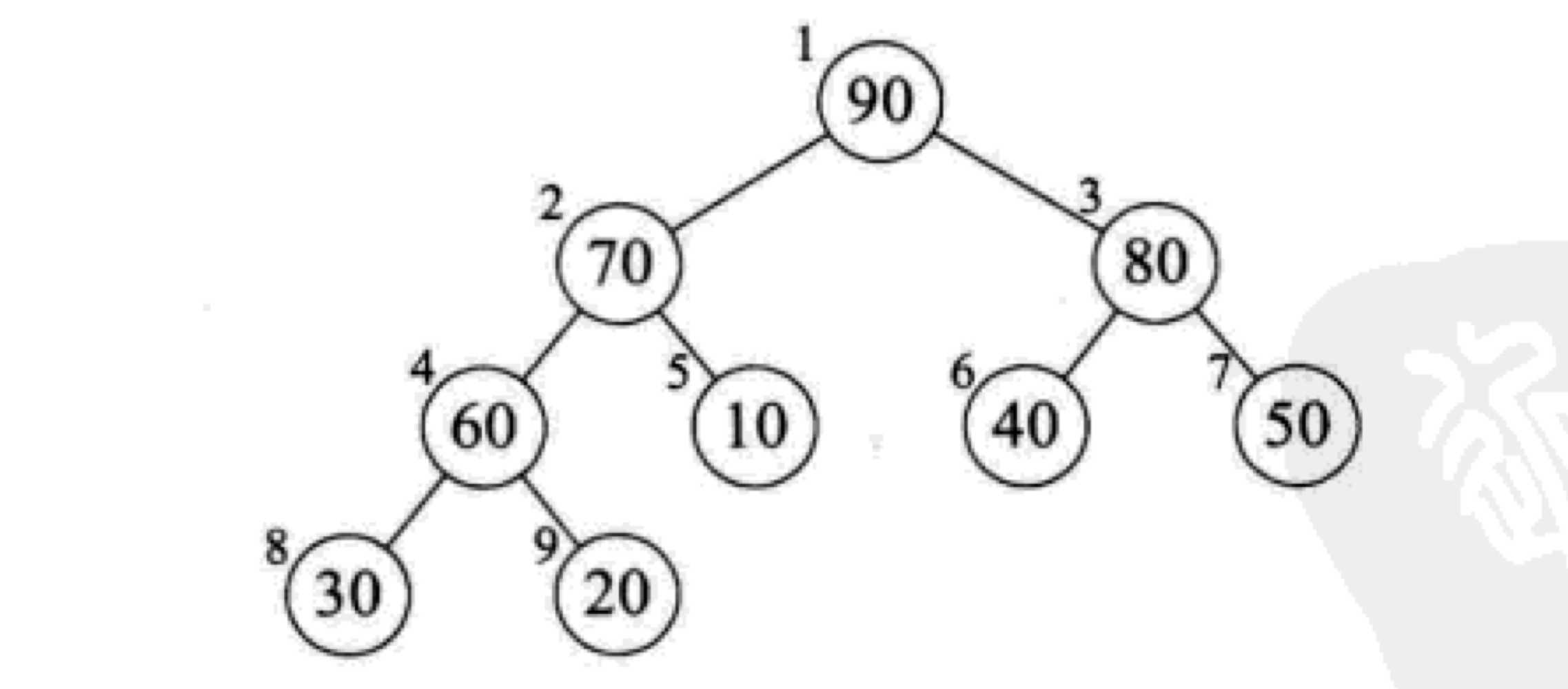
第一个for循环
上文的内容基本都在讲HeapSort()函数的第一个for循环(其中包括HeapAdjust()函数的讲解),这也是算法主要内容。
第一个for循环完成了大顶堆的构建过程,下面简要说明第二个for循环的内容:
第二个for循环就是将调整好的大顶堆的堆顶(也就是根节点)选出,将其与序列中的最后一个元素互换位置(也就达到了将最大元素放到末尾的效果,最后将获得一个由小到大顺序的序列)
然后将堆顶元素与最后的元素交换位置之后,我们对前length-1个元素再次进行调整,使其称为大顶堆,然后在下一次循环中再将堆顶与倒数第二个元素互换位置...如此循环
堆排序算法总结
运行时间主要是消耗在初始构建堆和在重建堆时的反复筛选上
堆排序的算法总体时间复杂度为O(nlogn)
空间复杂度上只有一个用来交换的暂存单元,也非常的不错
不过由于记录的比较与交换是跳跃式进行,堆排序也是一种不稳定的排序方法
由于初始构建堆所需的比较次数较多,不适合待排序序列个数较少的情况
