The Explanation: TensorFlow consumed all memory of all GPUs
When runing a TensorFlow or Keras script (as script 1) on a computer with multiple GPUs, the nvidia-smi -l command shows all the memory resource of all GPUs is consumed, as:
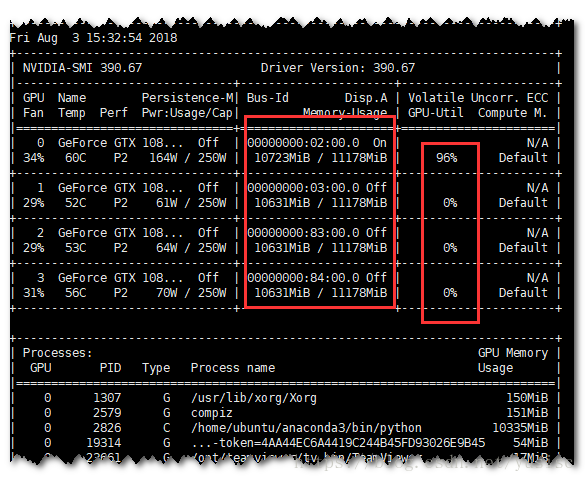
But, there is only one GPU is doing the calculation. In fact, the TensorFlow just made use of 1 GPU. Running script 2, the resource monitor shows
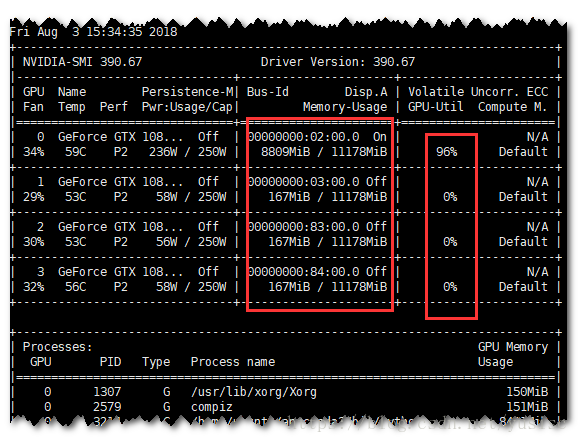
It’s easy to obtain that conclusion.
Inferred from python - How to prevent tensorflow from allocating the totality of a GPU memory? - Stack Overflow
Currently, this fraction is applied uniformly to all of the GPUs on the same machine; there is no way to set this on a per-GPU basis.
If tf.ConfigProto().gpu_options.allow_growth = False ( by default), TensorFlow is going to declare to consume the same percentage (the upper band) of memory of all visible GPUs.
As a summary, if the task is not written for multiple GPUs, it would be helpful to apply import setGPU to distribute the Tensorflow task to a certain GPU. In that scenario, there would be a free GPU, one could create another process for another task on the free GPU.
script 1
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
# @Time : 2018/8/3 15:24
# @File : explore_tensorflow_gpu_usage.py
# @Author : yusisc (yusisc@gmail.com)
# import setGPU
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, LSTM
from keras.optimizers import SGD
# import tensorflow as tf
# from keras.backend.tensorflow_backend import set_session
# config = tf.ConfigProto()
# config.gpu_options.allow_growth = True
# # config.gpu_options.per_process_gpu_memory_fraction = 0.3
# set_session(tf.Session(config=config))
# Generate dummy data
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000,)), num_classes=10)
# build model
model = Sequential()
model.add(Dense(1024*16, activation='relu', input_dim=20))
model.add(Dense(1024*16, activation='relu'))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
# train model
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
script 2
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
# @Time : 2018/8/3 15:24
# @File : explore_tensorflow_gpu_usage.py
# @Author : yusisc (yusisc@gmail.com)
# import setGPU
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, LSTM
from keras.optimizers import SGD
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
# config.gpu_options.per_process_gpu_memory_fraction = 0.3
set_session(tf.Session(config=config))
# Generate dummy data
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000,)), num_classes=10)
# build model
model = Sequential()
model.add(Dense(1024*16, activation='relu', input_dim=20))
model.add(Dense(1024*16, activation='relu'))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
# train model
model.fit(x_train, y_train,
epochs=20,
batch_size=128)ref
python - How to prevent tensorflow from allocating the totality of a GPU memory? - Stack Overflow
https://stackoverflow.com/questions/34199233/how-to-prevent-tensorflow-from-allocating-the-totality-of-a-gpu-memory
Limit the resource usage for tensorflow backend · Issue #1538 · keras-team/keras
https://github.com/keras-team/keras/issues/1538


 浙公网安备 33010602011771号
浙公网安备 33010602011771号