How to make TensorFlow employ multiple GPUs
The content of this essay may not be true. It’s just a short note.
As far as I know, recent versions of TensorFlow do not automatically distribute work load to multiply GPUs, even the GPUs are visible to it.
If one want to make the multiple GPUs share the work load, he should distribute the work load to different GPUs manually. The distribution operation is called tower in some way.
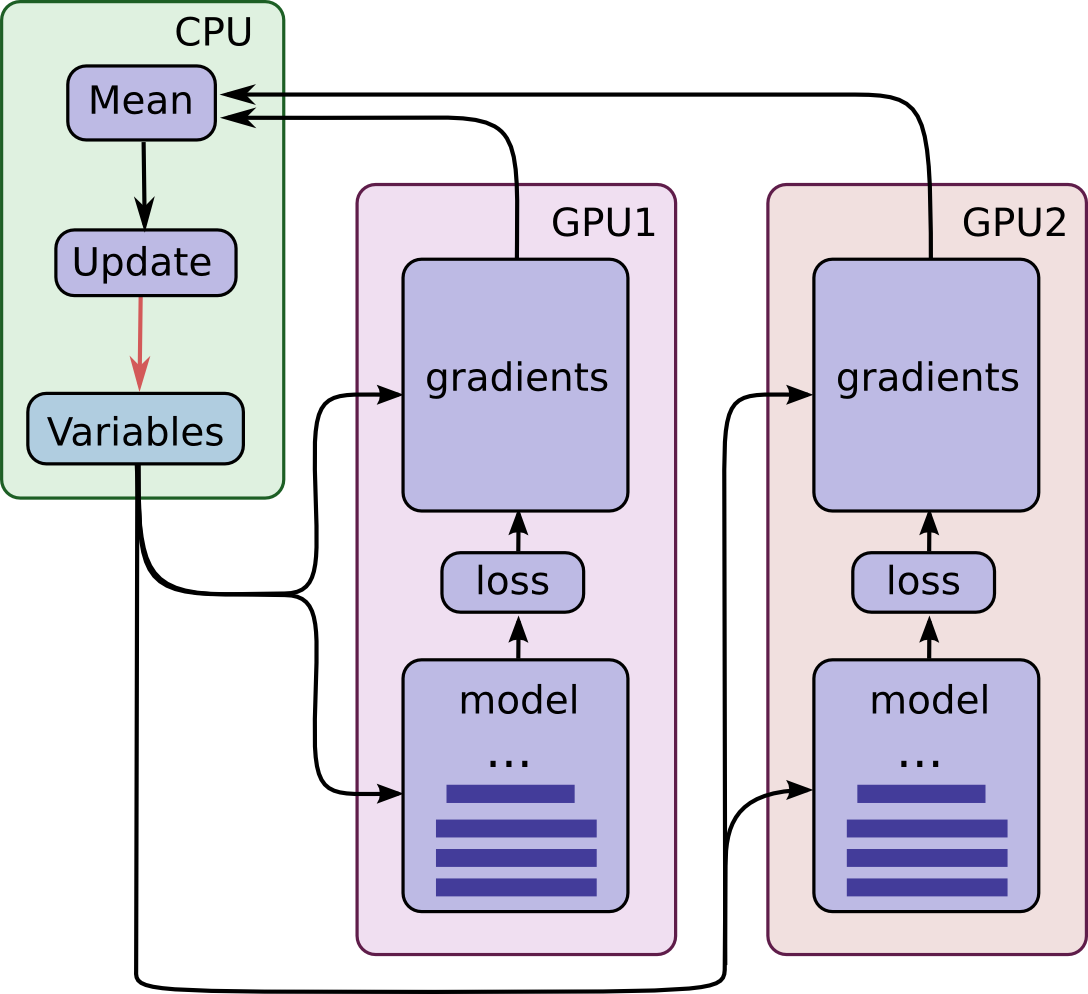
Placing Variables and Operations on Devices
Placing operations and variables on devices requires some special abstractions.
The first abstraction we require is a function for computing inference and gradients for a single model replica. In the code we term this abstraction a “tower”.
ref: Advanced Convolutional Neural Networks | TensorFlow
example
# golbin/TensorFlow-Multi-GPUs: Samples for Multi GPUs in TensorFlow
# https://github.com/golbin/TensorFlow-Multi-GPUs
import datetime
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.python.client import device_lib
def check_available_gpus():
local_devices = device_lib.list_local_devices()
gpu_names = [x.name for x in local_devices if x.device_type == 'GPU']
gpu_num = len(gpu_names)
print('{0} GPUs are detected : {1}'.format(gpu_num, gpu_names))
return gpu_num
def model(X, reuse=False):
with tf.variable_scope('L1', reuse=reuse):
L1 = tf.layers.conv2d(X, 64, [3, 3], reuse=reuse)
L1 = tf.layers.max_pooling2d(L1, [2, 2], [2, 2])
L1 = tf.layers.dropout(L1, 0.7, True)
with tf.variable_scope('L2', reuse=reuse):
L2 = tf.layers.conv2d(L1, 128, [3, 3], reuse=reuse)
L2 = tf.layers.max_pooling2d(L2, [2, 2], [2, 2])
L2 = tf.layers.dropout(L2, 0.7, True)
with tf.variable_scope('L2-1', reuse=reuse):
L2_1 = tf.layers.conv2d(L2, 128, [3, 3], reuse=reuse)
L2_1 = tf.layers.max_pooling2d(L2_1, [2, 2], [2, 2])
L2_1 = tf.layers.dropout(L2_1, 0.7, True)
with tf.variable_scope('L3', reuse=reuse):
L3 = tf.contrib.layers.flatten(L2_1)
L3 = tf.layers.dense(L3, 1024, activation=tf.nn.relu)
L3 = tf.layers.dropout(L3, 0.5, True)
with tf.variable_scope('L4', reuse=reuse):
L4 = tf.layers.dense(L3, 256, activation=tf.nn.relu)
with tf.variable_scope('LF', reuse=reuse):
LF = tf.layers.dense(L4, 10, activation=None)
return LF
if __name__ == '__main__':
# need to change learning rates and batch size by number of GPU
batch_size = 20000
learning_rate = 0.001
total_epoch = 1000
gpu_num = check_available_gpus()
X = tf.placeholder(tf.float32, [None, 28, 28, 1])
Y = tf.placeholder(tf.float32, [None, 10])
losses = []
X_A = tf.split(X, int(gpu_num))
Y_A = tf.split(Y, int(gpu_num))
'''
Multi GPUs Usage
Results on P40
* Single GPU computation time: 0:00:22.252533
* 2 GPU computation time: 0:00:12.632623
* 4 GPU computation time: 0:00:11.083071
* 8 GPU computation time: 0:00:11.990167
Need to change batch size and learning rates
for training more efficiently
Reference: https://research.fb.com/wp-content/uploads/2017/06/imagenet1kin1h5.pdf
'''
for gpu_id in range(int(gpu_num)):
with tf.device(tf.DeviceSpec(device_type="GPU", device_index=gpu_id)):
print(f'***1111** tf.get_variable_scope *********** {tf.get_variable_scope()}')
with tf.variable_scope('kkkkk', reuse=(gpu_id > 0)):
# with tf.variable_scope(tf.get_variable_scope(), reuse=(gpu_id > 0)):
"""
The usage of previous line is reusing the variables within different GPUs. This is relatively easy to
understand. But the usage of the `tf.variable_scope()` statement for the `name` of
the `tf.variable_scope` may be confusing to someone not familiar with this.
The purpose of previous line is keep the `tf.variable_scope()` be same to the recent environment,
while making share variables with different groups of operations, meaning it makes `variable` reusing
with different groups of operations without wrapping each group into a new wrapper.
To make it more clear, you could make use of `tensorboard` to visualize the `graph`s of different
conditions, which will make the differences obvious.
"""
print(f'**2222*** tf.get_variable_scope *********** {tf.get_variable_scope()}')
cost = tf.nn.softmax_cross_entropy_with_logits(
logits=model(X_A[gpu_id], gpu_id > 0),
labels=Y_A[gpu_id])
losses.append(cost)
loss = tf.reduce_mean(tf.concat(losses, axis=0))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(
loss, colocate_gradients_with_ops=True) # Important!
init = tf.global_variables_initializer()
writer = tf.summary.FileWriter('logs')
sess = tf.Session(config=tf.ConfigProto(log_device_placement=False))
sess.run(init)
writer.add_graph(graph=sess.graph)
writer.flush()
mnist = input_data.read_data_sets('/tmp/tensorflow/mnist/input_data', one_hot=True)
total_batch = int(mnist.train.num_examples / batch_size)
print("total: %s, %s, %s" % (mnist.train.num_examples, total_batch, batch_size))
start_time = datetime.datetime.now()
for epoch in range(total_epoch):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape(-1, 28, 28, 1)
_, cost_val = sess.run([optimizer, loss],
feed_dict={X: batch_xs,
Y: batch_ys})
total_cost += cost_val
print("total cost : %s" % total_cost)
print("--- Training time : {0} seconds /w {1} GPUs ---".format(
datetime.datetime.now() - start_time, gpu_num))
example repo
golbin/TensorFlow-Multi-GPUs: Samples for Multi GPUs in TensorFlow
https://github.com/golbin/TensorFlow-Multi-GPUs
models/tutorials/image/cifar10 at master · tensorflow/models
https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号