Python+selenium 【第十一章】封装底层页面操作类
本章题要:
本章节主要是封装底层操作类,将页面操作都封装到一个操作中,并结合我们之前的element_excel_utils中的部分信息结合使用
- 实现demo
demo_base_page_23.py
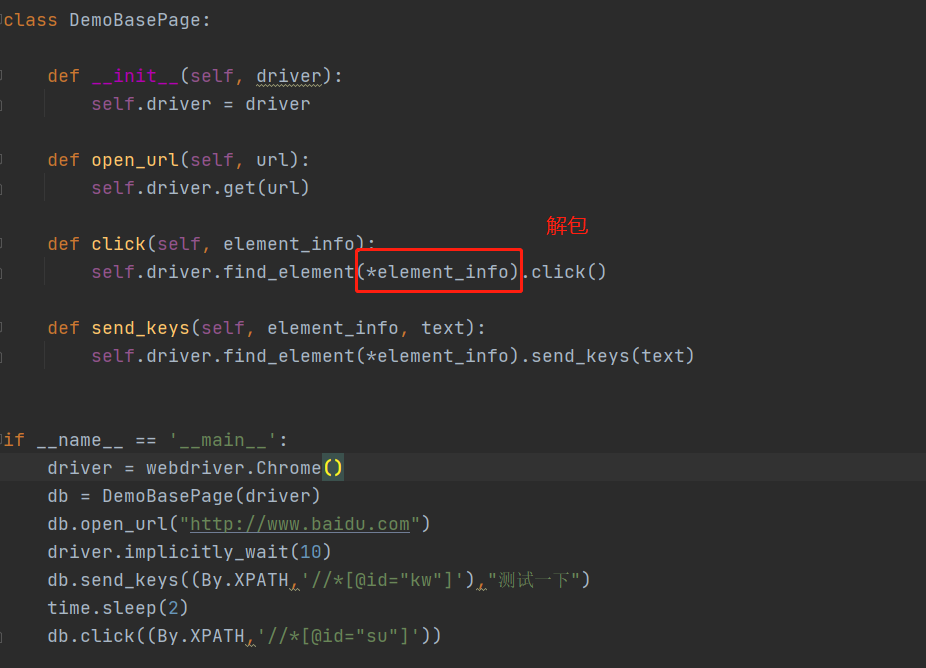
# -*- coding: utf-8 -*- # @Time : 2022/1/5 11:05 # @Author : Limusen # @File : demo_base_page_23 import time from selenium import webdriver from selenium.webdriver.common.by import By class DemoBasePage: def __init__(self, driver): self.driver = driver def open_url(self, url): self.driver.get(url) def click(self, element_info):
#*号是解包 self.driver.find_element(*element_info).click() def send_keys(self, element_info, text): self.driver.find_element(*element_info).send_keys(text) if __name__ == '__main__': driver = webdriver.Chrome() db = DemoBasePage(driver) db.open_url("http://www.baidu.com") driver.implicitly_wait(10) db.send_keys((By.XPATH,'//*[@id="kw"]'),"测试一下") time.sleep(2) db.click((By.XPATH,'//*[@id="su"]'))
在此我们先了解一下匿名函数的用法,匿名函数有哪些优点?
- 不用取名称,因为给函数取名是比较头疼的一件事,特别是函数比较多的时候
- 可以直接在使用的地方定义,如果需要修改,直接找到修改即可,方便以后代码的维护工作
- 语法结构简单,不用使用def 函数名(参数名):这种方式定义,直接使用lambda 参数:返回值 定义即可
举例:比方说,我要写一个函数用于两个数相乘
1 # -*- coding: utf-8 -*- 2 # @Time : 2022/1/5 13:16 3 # @Author : Limusen 4 # @File : demo_lambda_24 5 6 7 # 阶层 8 def x(y, z): 9 return y * z 10 11 print(x(3, 2)) 12 13 # 用匿名函数写的话 14 xx = lambda x, y: x * y 15 16 print(xx(3, 3))
- demo_base_page_23.py
# -*- coding: utf-8 -*- # @Time : 2022/1/5 11:05 # @Author : Limusen # @File : demo_base_page_23 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait class DemoBasePage: def __init__(self, driver): self.driver = driver def open_url(self, url): self.driver.get(url) def find_element(self, element_info): """ 通过分离处理的元素识别字典信息,返回一个元素 :param element_info: 元素信息,字典类型{} :return: element对象 """ try: locator_type = element_info["locator_type"] locator_value = element_info["locator_value"] locator_timeout = element_info["timeout"] if locator_type == "name": locator_type = By.NAME elif locator_type == "css": locator_type = By.CSS_SELECTOR elif locator_type == "xpath": locator_type = By.XPATH elif locator_type == "id": locator_type = By.ID elif locator_type == "class": locator_type = By.CLASS_NAME elif locator_type == "linktext": locator_type = By.LINK_TEXT elif locator_type == "partiallink": locator_type = By.PARTIAL_LINK_TEXT elif locator_type == "tag": locator_type = By.TAG_NAME # 采用匿名函数 将元素存在x变量当中,然后去查找页面是否存在当前元素 element = WebDriverWait(self.driver, locator_timeout).until( lambda x: x.find_element(locator_type, locator_value)) except Exception: raise return element def click(self, element_info): # 优化 element = self.find_element(element_info) element.click() def send_keys(self, element_info, text): # 优化 element = self.find_element(element_info) element.send_keys(text) if __name__ == '__main__': driver = webdriver.Chrome() db = DemoBasePage(driver) db.open_url("http://www.baidu.com") driver.implicitly_wait(10) # db.send_keys((By.XPATH, '//*[@id="kw"]'), "测试一下") # time.sleep(2) # db.click((By.XPATH, '//*[@id="su"]')) # 优化代码 读取excel中的数据 element_info = { 'input_text': {'element_name': '输入框', 'locator_type': 'xpath', 'locator_value': '//*[@id="kw"]', 'timeout': 5.0}, 'click_button': {'element_name': '点击按钮', 'locator_type': 'xpath', 'locator_value': '//*[@id="su"]', 'timeout': 5.0}} input_t = element_info['input_text'] click_b = element_info['click_button'] db.send_keys(input_t, "测试一下") db.click(click_b)
- 在common文件夹下新建base_page.py 将写好的代码copy进去
# -*- coding: utf-8 -*- # @Time : 2022/1/5 13:50 # @Author : Limusen # @File : base_page from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait class BasePage: def __init__(self, driver): self.driver = driver def open_url(self, url): self.driver.get(url) def find_element(self, element_info): """ 通过分离处理的元素识别字典信息,返回一个元素 :param element_info: 元素信息,字典类型{} :return: element对象 """ try: locator_type = element_info["locator_type"] locator_value = element_info["locator_value"] locator_timeout = element_info["timeout"] if locator_type == "name": locator_type = By.NAME elif locator_type == "css": locator_type = By.CSS_SELECTOR elif locator_type == "xpath": locator_type = By.XPATH elif locator_type == "id": locator_type = By.ID elif locator_type == "class": locator_type = By.CLASS_NAME elif locator_type == "linktext": locator_type = By.LINK_TEXT elif locator_type == "partiallink": locator_type = By.PARTIAL_LINK_TEXT elif locator_type == "tag": locator_type = By.TAG_NAME # 采用匿名函数 将元素存在x变量当中,然后去查找页面是否存在当前元素 element = WebDriverWait(self.driver, locator_timeout).until( lambda x: x.find_element(locator_type, locator_value)) except Exception: raise return element def click(self, element_info): # 优化 element = self.find_element(element_info) element.click() def send_keys(self, element_info, text): # 优化 element = self.find_element(element_info) element.send_keys(text) if __name__ == '__main__': driver = webdriver.Chrome() db = BasePage(driver) db.open_url("http://www.baidu.com") driver.implicitly_wait(10) # 优化代码 读取excel中的数据 element_info = { 'input_text': {'element_name': '输入框', 'locator_type': 'xpath', 'locator_value': '//*[@id="kw"]', 'timeout': 5.0}, 'click_button': {'element_name': '点击按钮', 'locator_type': 'xpath', 'locator_value': '//*[@id="su"]', 'timeout': 5.0}} input_t = element_info['input_text'] click_b = element_info['click_button'] db.send_keys(input_t, "测试一下") db.click(click_b)
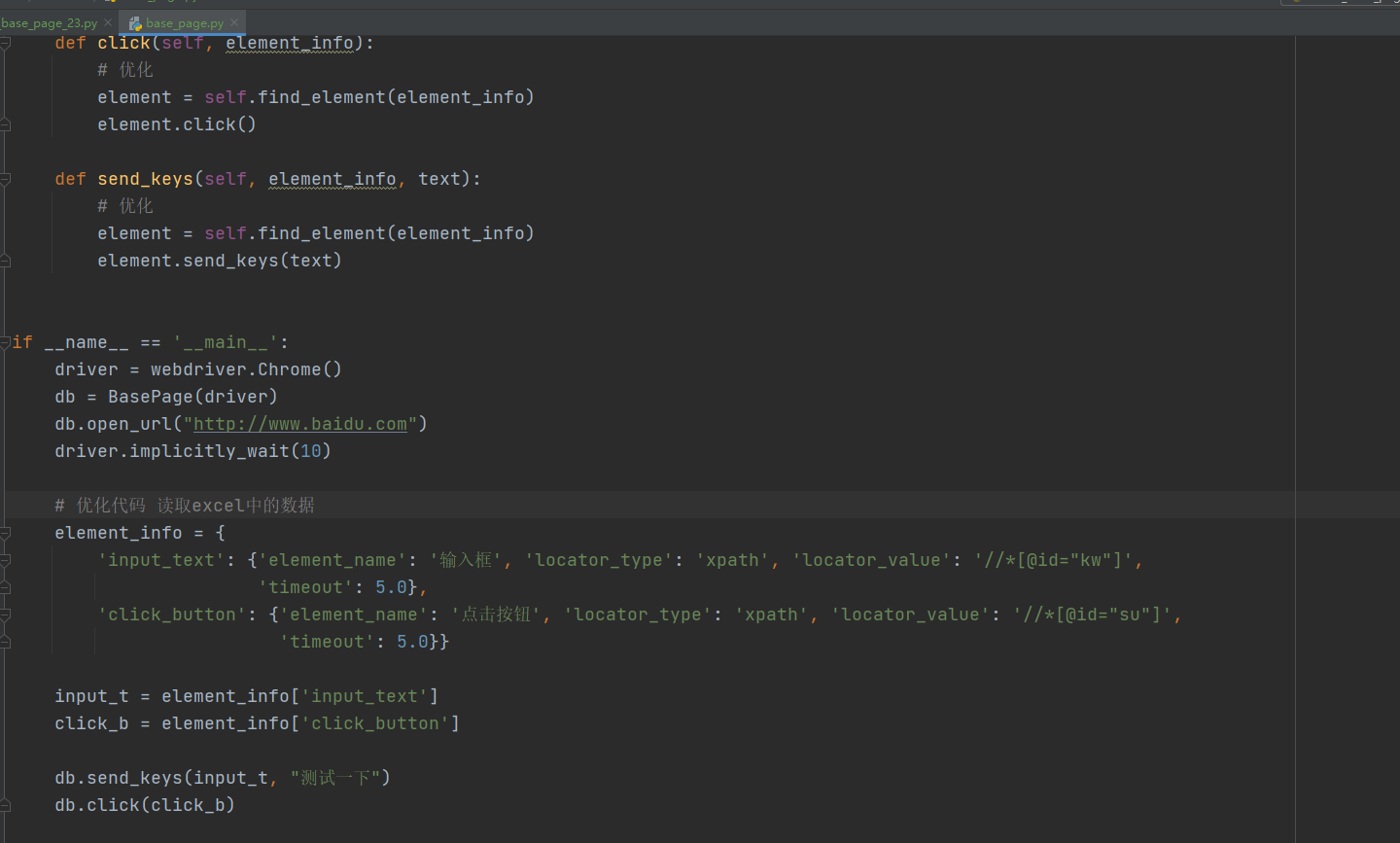
基本上的封装方式就是这样的,大家可以自己根据项目的情况封装一些使用的方法
