DS博客作业03--树
0.PTA得分截图

1.本周学习总结(0-5分)
1.1 总结树及串内容
一、串
-
串的定义:零个或多个字符组成的有限序列
-
串的存储结构
<1>定长顺序存储:用一组地址连续的存储单元存储串值的字符序列,称为顺序串。可用一个数组来表示。
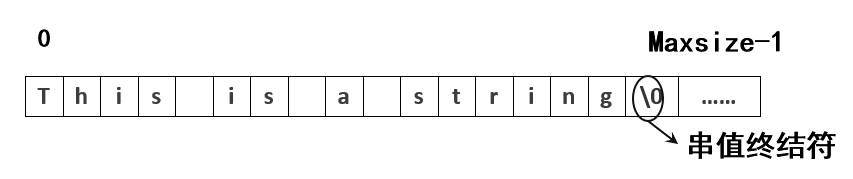
类型定义:
#define MaxSize 100 //MaxSize常量表示字符串最大长度。
typedef struct
{ char data[MaxSize];//data域存储字符串,
int length;//length域存储字符串长度,
} SqString;
<2>链式存储:链串中的一个结点可以存储多个字符。通常将链串中每个结点所存储的字符个数称为结点大小。
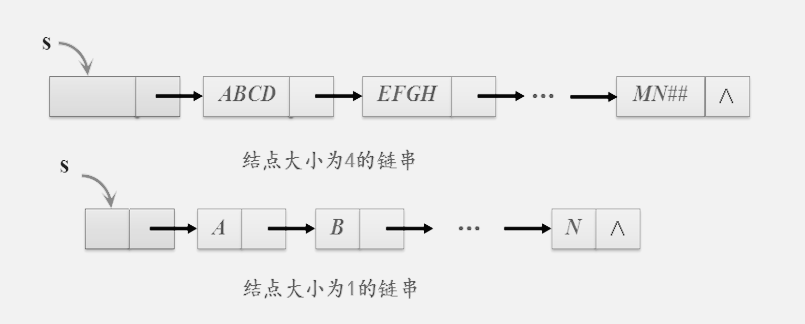
类型定义:
#define CHUNKSIZE 80 //可由用户定义的块大小
typedef struct Chunk{
char ch[CHUNKSIZE];
struct Chunk *next;
}Chunk;
typedef struct{
Chunk *head,*tail; //串的头指针和尾指针
int curlen; //串的当前长度
}LString;
- 串的基本运算
StrAssign(&s,cstr):将字符串常量cstr赋给串s,即生成其值等于cstr的串s。
StrCopy(&s,t):串复制。将串t赋给串s。
StrEqual(s,t):判串相等。若两个串s与t相等则返回真;否则返回假。
StrLength(s):求串长。返回串s中字符个数。
Concat(s,t):串连接:返回由两个串s和t连接在一起形成的新串。
SubStr(s,i,j):求子串。返回串s中从第i(1≤i≤n)个字符开始的、由连续j个字符组成的子串。
InsStr(s1,i,s2):插入。将串s2插入到串s1的第i(1≤i≤n+1)个字符中,即将s2的第一个字符作为s1的第i个字符,并返回产生的新串。
DelStr(s,i,j):删除。从串s中删去从第i(1≤i≤n)个字符开始的长度为j的子串,并返回产生的新串。
RepStr(s,i,j,t):替换。在串s中,将第i(1≤i≤n)个字符开始的j个字符构成的子串用串t替换,并返回产生的新串。
DispStr(s):串输出。输出串s的所有元素值。
- C++中的字符串(string)
-
C++中的字符串
-
是一个类-(string)
-
需要#include
-
包含很多常用的字符串处理函数
-
=,+,==,!=,>,>=,<,<=
-
size(),length()等
-
empty(),substr(),find(),compare(),append()等
-
-
-
比较:C++的string不必担心内存是否足够、字符串长度等等,集成了大部分常用函数
- 串的模式匹配算法
<1>BF算法(Brute-Force算法)
基本思路:
1.从目标串s=“s0s1…sn-1”的第一个字符开始和模式串t=“t0t1…tm-1”中的第一个字符比较
2.若相等,则继续逐个比较后续字符;
3.否则从目标串s的第二个字符开始重新与模式串t的第一个字符进行比较。
4.依次类推,若从模式串s的第i个字符开始,每个字符依次和目标串t中的对应字符相等,则匹配成功,该算法返回i;否则,匹配失败,函数返回-1。
算法展示:
int index(SqString s,SqString t)
{ int i=0, j=0;
while (i<s.length && j<t.length)
{ if (s.data[i]==t.data[j]) //继续匹配下一个字符
{ i++; //主串和子串依次匹配下一个字符
j++;
}
else //主串、子串指针回溯重新开始下一次匹配
{ i=i-j+1; //主串从下一个位置开始匹配
j=0; //子串从头开始匹配
}
}
if (j>=t.length)
return(i-t.length); //返回匹配的第一个字符的下标
else
return(-1); //模式匹配不成功
}
<2>KMP算法
基本思路:
1.对于每模式串 t 的每个元素 t j,都存在一个实数 k
2.使得模式串 t 开头的 k 个字符(t 0 t 1…t k-1)依次与 t j 前面的 k(t j-k t j-k+1…t j-1,这里第一个字符 t j-k 最多从 t 1 开始,所以 k < j)个字符相同
3.如果这样的 k 有多个,则取最大的一个。模式串 t 中每个位置 j 的字符都有这种信息,采用 next 数组表示,即 next[ j ]=MAX{ k }
4.KMP 算法永不回退 txt 的指针 i,不走回头路(不会重复扫描 txt),而是借助 dp 数组中储存的信息把 pat 移到正确的位置继续匹配,时间复杂度只需 O(N)
算法展示:
① next数组
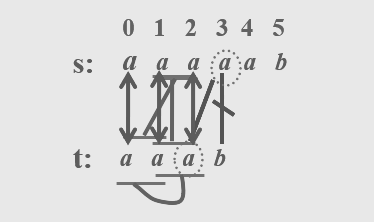
int KMPIndex(SqString s,SqString t)
{ int next[MaxSize],i=0,j=0;
GetNext(t,next);
while (i<s.length && j<t.length)
{ if (j==-1 || s.data[i]==t.data[j])
{ i++;
j++; //i,j各增1
}
else j=next[j]; //i不变,j后退
}
if (j>=t.length)
return(i-t.length); //匹配模式串首字符下标
else
return(-1); //返回不匹配标志
}
缺陷:相同字符重复匹配
② nextval数组
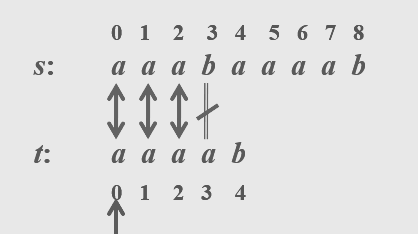
int KMPIndex1(SqString s,SqString t)
{ int nextval[MaxSize],i=0,j=0;
GetNextval(t,nextval);
while (i<s.length && j<t.length)
{ if (j==-1 || s.data[i]==t.data[j])
{ i++;
j++;
}
else
j=nextval[j];
}
if (j>=t.length)
return(i-t.length);
else
return(-1);
}
KMP算法的优点:不需回溯。对于从外设读入的庞大文件很有效可以边读入边匹配,无须回头重读。
二、二叉树
-
二叉树的定义:是n(n>=0)个结点的有限集合,它或为空树(n=0),或由一个根结点和至多两棵称为根的左子树和右子树的互不相交的二叉树组成。
-
基本术语:
根——即根结点(没有前驱)
叶子——即终端结点(没有后继)
森林——指m棵不相交的树的集合(例如删除A后的子树个数)
有序树——结点各子树从左至右有序,不能互换(左为第一)
无序树——结点各子树可互换位置。
双亲——即上层的那个结点(直接前驱)
孩子——即下层结点的子树的根(直接后继)
兄弟——同一双亲下的同层结点(孩子之间互称兄弟)
祖先——即从根到该结点所经分支的所有结点
子孙——即该结点下层子树中的任一结点
结点——即树的数据元素
结点的度——结点挂接的子树数,分支数目
结点的层次——从根到该结点的层数(根结点算第一层)
终端结点——即度为0的结点,即叶子
分支结点——即度不为0的结点(也称为内部结点)
树的深度(或高度)——指所有结点中最大的层数
- 两种特殊的二叉树类型
<1>满二叉树
在一棵二叉树中,所有分支结点都有双分结点,并且叶结点都集中在二叉树的最下一层。

<2>完全二叉树
深度为k的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k 的满二叉树中编号从1至n的结点一一对应,没有单独右分支结点。
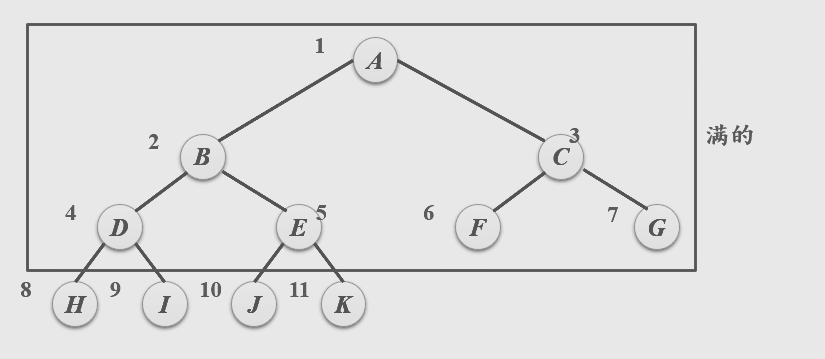
<3>满二叉树和完全二叉树的区别
- 满二叉树是叶子一个也不少的树,而完全二叉树虽然前n-1层是满的,但最底层却允许在右边缺少连续若干个结点。
- 满二叉树是完全二叉树的一个特例。
- 二叉树性质
1.非空二叉树上叶节点数等于双分支节点数加1。
2.在二叉树的第 i 层上至多有2^(i-1)个结点(i≥1)。
3.高度为h的二叉树至多有2^h-1个节点(h≥1)。
4.具有n个结点的完全二叉树的深度必为 [log2n] + 1
- 二叉树存储结构
<1>顺序存储结构
① 完全二叉树的顺序存储结构

结构定义:
typedef ElemType SqBTree[MaxSize];
SqBTree bt="ABCDEFGHIJK#####";
② 非完全二叉树的顺序存储结构

结构定义:
typedef ElemType SqBTree[MaxSize];
SqBTree bt="#ABD#C#E######F";
顺序存储结构的缺点:
-
对于完全二叉树来说,其顺序存储是十分合适
-
在最坏的情况下,一个深度为k且只有k个结点的单支树(树中不存在度为2的结点)却需要2k-1的一维数组。空间利用率太低!
-
数组,查找、插入删除不方便。
<2>链式存储结构

结构定义:
typedef struct TNode *Position;
typedef Position BinTree; /* 二叉树类型 */
struct TNode{ /* 树结点定义 */
ElementType Data; /* 结点数据 */
BinTree Left; /* 指向左子树 */
BinTree Right; /* 指向右子树 */
};
- 二叉树的基本运算及其实现
<1>树创建方法
① 顺序存储结构转成二叉链
BTree CreateBTree(string str,int i)
{
int len;
BTree bt;
bt=new TNode;
len=str.size();
if(i>len || i<=0) return NULL;
if(str[i]=='#') return NULL;
bt->data =str[i];
bt->lchild =CreateBTree(str,2*i);
bt->rchild =CreateBTree(str,2*i+1);
return bt;
}
② 先序遍历递归建树
BTree CreatTree(string str, int &i)
{
BTree bt;
if (i > len - 1) return NULL;
if (str[i] == '#') return NULL;
bt = new BTNode;
bt->data = str[i];
bt->lchild = CreatTree(str, ++i);
bt->rchild = CreatTree(str, ++i);
return bt;
}
③ 层次法建树
void CreateBTree(BTree &BT,string str)
{ BTree T;int i=0;
queue<BTree> Q;//队列
if( str[0]!='0' ){ /*分配根结点单元,并将结点地址入队*/
BT =new BTNode;
BT->data = str[0];
BT->lchild=BT->rchild=NULL;
Q.push(BT);
}
else BT=NULL; /* 若第1个数据就是0,返回空树 */
while( !Q.empty())
{
T = Q.front();/*从队列中取出一结点地址*/
Q.pop();
i++;
if(str[i]=='0' ) T->lchild = NULL;
else
{ /*生成左孩子结点;新结点入队*/
T->lchild = new BTNode;
T->lchild->data = str[i];
T->lchild->lchild=T->lchild->rchild=NULL;
Q.push(T->lchild);
}
i++; /* 读入T的右孩子 */
if(str[i]=='0') T->rchild = NULL;
else
{ /*生成右孩子结点;新结点入队*/
T->rchild = new BTNode;;
T->rchild->data = str[i];
T->rchild->lchild=T->rchild->rchild=NULL;
Q.push(T->rchild);
}
} /* 结束while */
}
④ 括号法字符串构造二叉树
void CreateBTNode(BTNode * &b,char *str)
{ //由str 二叉链b
BTNode *St[MaxSize], *p;
int top=-1, k , j=0;
char ch;
b=NULL; //建立的二叉链初始时为空
ch=str[j];
while (ch!='\0') //str未扫描完时循环
{ switch(ch)
{
case '(': top++; St[top]=p; k=1; break; //可能有左孩子结点,进栈
case ')': top--; break;
case ',': k=2; break; //后面为右孩子结点
default: //遇到结点值
p=(BTNode *)malloc(sizeof(BTNode));
p->data=ch; p->lchild=p->rchild=NULL;
if (b==NULL) //p为二叉树的根结点
b=p;
else //已建立二叉树根结点
{ switch(k)
{
case 1: St[top]->lchild=p; break;
case 2: St[top]->rchild=p; break;
}
}
}
j++; ch=str[j]; //继续扫描str
}
}
<2>树遍历方法
① 先序遍历
void PreOrder(BTree bt)
{ if (bt!=NULL)
{ printf("%c ",bt->data); //访问根结点
PreOrder(bt->lchild);
PreOrder(bt->rchild);
}
}
② 中序遍历
void InOrder(BTree bt)
{ if (bt!=NULL)
{ InOrder(bt->lchild);
printf("%c ",bt->data); //访问根结点
InOrder(bt->rchild);
}
}
③ 后序遍历
void PostOrder(BTree bt)
{ if (bt!=NULL)
{ PostOrder(bt->lchild);
PostOrder(bt->rchild);
printf("%c ",bt->data); //访问根结点
}
}
④ 层次遍历
初始化队列,先将根节点进队。
while(队列不空)
{ 队列中出列一个节点*p,访问它;
若它有左孩子节点,将左孩子节点进队;
若它有右孩子,将右孩子进队。
}
三、树
-
树的定义:非空时,m棵子树集合
-
树的性质
1.树中的结点数等于所有结点的度数之和加1。
2。度为m的树中第i层上至多有mi-1个结点(i≥1)。
- 树的存储结构
<1>双亲存储结构
typedef struct
{ ElemType data; //结点的值
int parent; //指向双亲的位置
} PTree[MaxSize];
缺点:找父亲容易,找孩子不容易.
<2>孩子链存储结构
typedef struct node
{ ElemType data; //结点的值
struct node *sons[MaxSons]; //指向孩子结点
} TSonNode;
缺点:1.空指针太多。2.找父亲不容易。
<3>孩子兄弟链存储结构
typedef struct tnode
{ ElemType data; //结点的值
struct tnode *son; //指向兄弟
struct tnode *brother; 2//指向孩子结点
} TSBNode;
缺点:每个结点固定只有两个指针域,类似二叉树,找父亲不容易。
**不同场景的选择**:
在一棵树T中最常用的操作是查找某个结点的祖先结点,采用双亲存储结构最合适。
如最常用的操作是查找某个结点的所有兄弟,采用孩子链存储结构或者孩子兄弟链存储结构最合适。
- 树的遍历
定义:树的遍历运算是指按某种方式访问树中的每一个结点且每一个结点只被访问一次。
<1>先根遍历:若树不空,则先访问根结点,然后依次先根遍历各棵子树。
<2>后根遍历:若树不空,则先依次后根遍历各棵子树,然后访问根结点。
<3>层次遍历:若树不空,则自上而下、自左至右访问树中每个结点。
- 二叉树与树、森林之间的转换
<1>森林
定义:
① n(n>0)个互不相交的树的集合称为森林。
② 只要把树的根结点删去就成了森林。
③ 反之,只要给n棵独立的树加上一个结点,并把这n棵树作为该结点的子树,则森林就变成了一颗树。
<2>森林、树转换为二叉树
① 相邻兄弟节点加一水平连线
② 除了左孩子和叶子节点,删掉连线
③ 水平连线以左边节点轴心旋转45度
<3>二叉树还原为一颗树
① 任一节点k,搜索所有右孩子
② 删掉右孩子连线
③ 若节点k父亲为k0,则k0和所有k右孩子连线
- 二叉树的构造
<1>先序和中序构造二叉树
BTRee CreateBT1(char *pre,char *in,int n)
{ BTNode *s; char *p; int k;
if (n<=0) return NULL;
s=new BTNode;
s->data=*pre; //创建根节点
for (p=in;p<in+n;p++) //在中序中找为*ppos的位置k
if (*p==*pre)
break;
k=p-in;
s->lchild=CreateBT1(pre+1,in,k); //构造左子树
s->rchild=CreateBT1(pre+k+1,p+1,n-k-1); //右子树
return s;
}
<2>后序和中序构造二叉树
BTRee CreateBT2(char *post,char *in,int n)
{ BTNode *s; char *p; int k;
if (n<=0) return NULL;
s=new BTNode;//创建节点
s->data=*(post+n-1); //构造根节点。
for (p=in;p<in+n;p++)//在中序中找为*ppos的位置k
if (*p==*(post+n-1))
break;
k=p-in;
s->lchild=CreateBT2(post,in,k); //构造左子树
s->rchild=CreateBT2(post+k,p+1,n-k-1);//构造右子树
return s;
}
- 线索二叉树
- 二叉链存储结构时,每个节点有两个指针域,总共有2n个指针域。
- 有效指针域:n-1(根节点没指针指向)
- 空指针域:n+1
- 利用这些空链域,指向该线性序列中的“前驱”和“后继”的指针,称作线索。
<1>结构体定义:
typedef struct node
{ ElemType data; //结点数据域
int ltag,rtag; //增加的线索标记
struct node *lchild; //左孩子或线索指针
struct node *rchild; //右孩子或线索指针
} TBTNode; //线索树结点类型定义
<2>结点操作
① 若结点有左子树,则lchild指向其左孩子;
否则, lchild指向其直接前驱(即线索);
② 若结点有右子树,则rchild指向其右孩子;
否则, rchild指向其直接后继(即线索) 。
<3>线索化类型
① 先序线索二叉树
② 后序线索二叉树
③ 中序线索二叉树(在线索二叉树中再增加一个头结点 )
<4>线索化操作
① 遍历线索化二叉树
void ThInOrder(TBTNode *tb)
{ TBTNode *p=tb->lchild; //p指向根结点
while (p!=tb)//tb头结点
{
while (p->rtag==0) p=p->lchild; //找开始结点
printf("%c",p->data); //访问开始结点
while (p->rtag==1 && p->rchild!=tb)
{ p=p->rchild;
printf("%c",p->data);
}
p=p->rchild;
}
}
② 中序线索二叉树创建
TBTNode *pre; //全局变量
TBTNode *CreatThread(TBTNode *b) //中序线索化二叉树
{ TBTNode *root;
root=(TBTNode *)malloc(sizeof(TBTNode)); //创建头结点
root->ltag=0; root->rtag=1; root->rchild=b;
if (b==NULL) root->lchild=root; //空二叉树
else
{ root->lchild=b;
pre=root; //pre是*p的前驱结点,供加线索用
Thread(b); //中序遍历线索化二叉树
pre->rchild=root; //最后处理,加入指向头结点的线索
pre->rtag=1;
root->rchild=pre; //头结点右线索化
}
return root;
}
void Thread(TBTNode *&p) //对二叉树b进行中序线索化
{ if (p!=NULL)
{
Thread(p->lchild); //左子树线索化
if (p->lchild==NULL) //前驱线索化
{ p->lchild=pre; p->ltag=1; } //建立当前结点的前驱线索
else p->ltag=0;
if (pre->rchild==NULL) //后继线索化
{ pre->rchild=p;pre->rtag=1;} //建立前驱结点的后继线索
else pre->rtag=0;
pre=p;
Thread(p->rchild); //递归调用右子树线索化
}
}
四、哈夫曼树
<1>定义:假设有m个权值{w1,w2,w3,...,wn},可以构造一棵含有n个叶子结点的二叉树,每个叶子结点的权为wi,则其中带权路径长度WPL最小的二叉树称做最优二叉树或哈夫曼树。
<2>构建哈夫曼树的过程
1.在 n 个权值中选出两个最小的权值,对应的两个结点组成一个新的二叉树,且新二叉树的根结点的权值为左右孩子权值的和;
2.在原有的 n 个权值中删除那两个最小的权值,同时将新的权值加入到 n–2 个权值的行列中,以此类推;
3.重复 1 和 2 ,直到所以的结点构建成了一棵二叉树为止,这棵树就是哈夫曼树。
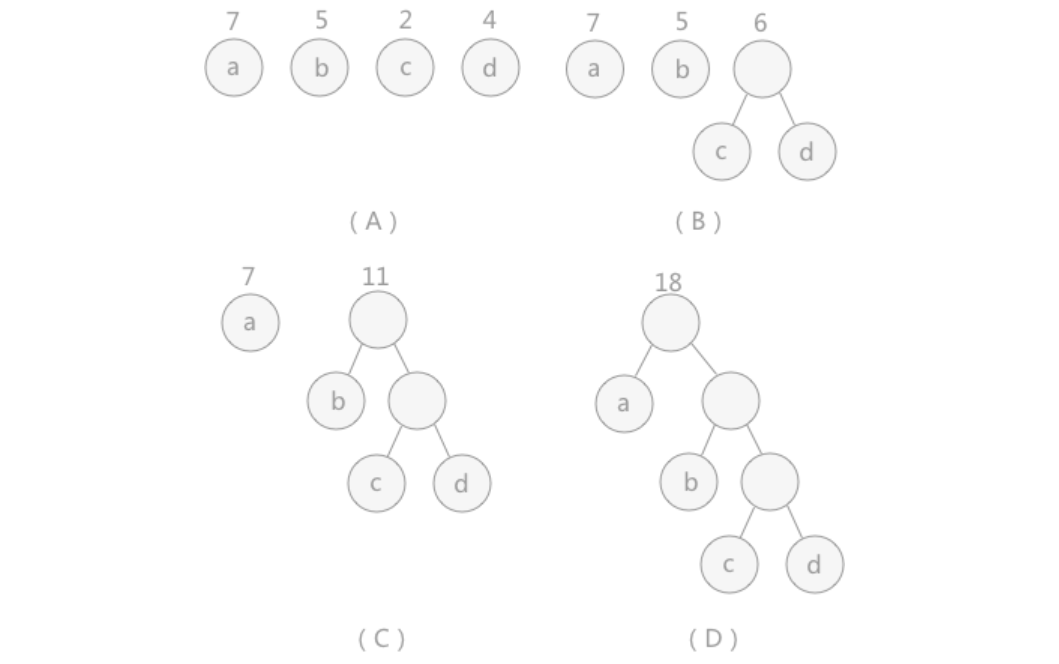
如上图中,(A)给定了四个结点a,b,c,d,权值分别为7,5,2,4;
第一步如(B)所示,找出现有权值中最小的两个,2 和 4 ,相应的结点 c 和 d 构建一个新的二叉树,树根的权值为 2 + 4 = 6,
同时将原有权值中的 2 和 4 删掉,将新的权值 6 加入;
进入(C),重复之前的步骤。
直到(D)中,所有的结点构建成了一个全新的二叉树,这就是哈夫曼树。
<3>结点定义类型
typedef struct {
char data;//结点值
int weight;//结点权重
int parent, left, right;//父结点、左孩子、右孩子在数组中的位置下标
}HTNode, *HuffmanTree;
<4>基本运算
① 选择权值最小的两颗树
void SelectMin(HuffmanTree hT, int n, int &s1, int &s2)
{
s1 = s2 = 0;
int i;
for(i = 1; i < n; ++ i){
if(0 == hT[i].parent){
if(0 == s1){
s1 = i;
}
else{
s2 = i;
break;
}
}
}
if(hT[s1].weight > hT[s2].weight){
int t = s1;
s1 = s2;
s2 = t;
}
for(i += 1; i < n; ++ i){
if(0 == hT[i].parent){
if(hT[i].weight < hT[s1].weight){
s2 = s1;
s1 = i;
}else if(hT[i].weight < hT[s2].weight){
s2 = i;
}
}
}
}
② 构造有n个权值(叶子节点)的哈夫曼树
void CreateHufmanTree(HuffmanTree &hT)
{
int n, m;
cin >> n;
m = 2*n - 1;
hT = new HTNode[m + 1]; // 0号节点不使用
for(int i = 1; i <= m; ++ i){
hT[i].parent = hT[i].lChild = hT[i].rChild = 0;
}
for(int i = 1; i <= n; ++ i){
cin >> hT[i].weight; // 输入前n个单元中叶子结点的权值
}
hT[0].weight = m; // 用0号节点保存节点数量
/****** 初始化完毕, 创建哈夫曼树 ******/
for(int i = n + 1; i <= m; ++ i){
//通过n-1次的选择、删除、合并来创建二叉树
int s1, s2;
SelectMin(hT, i, s1, s2);
hT[s1].parent = hT[s2].parent = i;
hT[i].lChild = s1; hT[i].rChild = s2; // 作为新节点的孩子
hT[i].weight = hT[s1].weight + hT[s2].weight; // 新节点为左右孩子节点权值之和
}
}
五、并查集
<1>简介
定义:查找一个元素所属的集合及合并2个元素各自专属的集合等运算
应用:亲戚关系、朋友圈应用。
分离集合树:在并查集中,每个分离集合对应的一棵树,称为分离集合树。整个并查集也就是一棵分离集合森林。
集合查找:在一棵高度较低的树中查找根结点的编号,所花的时间较少。同一个集合标志就是根是一样。
集合合并:两棵分离集合树A和B,高度分别为hA和hB,则若hA>hB,应将B树作为A树的子树;否则,将A树作为B树的子树。总之,总是高度较小的分离集合树作为子树。得到的新的分离集合树C的高度hC=MAX{hA,hB+1}。
<2>操作
① 结构体定义
typedef struct node
{
int dada; //结点对应人的编号
int rank; //结点秩:子树的高度,合并用
int parent; //结点对应双亲下标
}UFSTree;
② 并查集树的初始化
void MAKE_SET(UFSTree t[], int n)
{ int i;
for(i=1;i<=n;i++)
{ t[i].data=i; //数据为该人的编号
t[i].rank=0; //秩初始化为0
t[i].parent=i; //双亲初始化指向自己
}
}
③ 查找一个元素所属的集合
int FIND_SET(UFSTree t[], int x)
{ if(x!=t[x].parent) //双亲不是自己
return(FIND_SET(t, t[x].parent)); //递归在双亲中找x
else
return(x); //双亲是自己,返回x
}
④ 两个元素各自所属的集合的合并
void UNION(UFSTree t[], int x, int y)
{
x=FIND_SET(t, x);
y=FIND_SET(t, y);
if(t[x].rank>t[y].rank)
t[y].parent=x;
else
{
t[x].parent=y;
if(t[x].rank==t[y].rank)
t[y].rank++;
}
}
1.2.谈谈你对树的认识及学习体会。
经过这两周的学习,主要学习了关于树方面的知识。
在涉及到非线性结构、层次结构关系的问题中可以很好地应用树的知识,同时树还可以用于网页中的信息爬取等。
在刚开始学习树时感觉内容会有点抽象,不过随着对树的不断编程应用,对树操作也越来越熟练,逐渐懂得了树的运行模式。
在很多地方都可以看到树的应用,可以说树即是数据结构的重点,也是难点。
只有通过对树内容的不断探索与分析,才能熟练地操作树结构。
在接下来的学习中,结合之前所学的内容,进行下一步拓展。
2.阅读代码(0--5分)
2.1 题目及解题代码
题目

解题代码
class Solution {
public:
vector<vector<int>> res;
vector<vector<int>> zigzagLevelOrder(TreeNode* root)
{
addVector(root,0); //调用递归函数
return res;
}
void addVector(TreeNode* root,int level)
{
if(root == NULL) return;
if(res.size()==level) res.resize(level+1); //level表示层数,也对应二维数组的第一层索引,
if(level %2==0)
res[level].push_back(root->val); //如果为偶数行则顺序加入,如果为奇数行则将数字每次插入到最前面
else
res[level].insert(res[level].begin(),root->val);
addVector(root->left,level+1);
addVector(root->right,level+1);
}
};
2.1.1 该题的设计思路
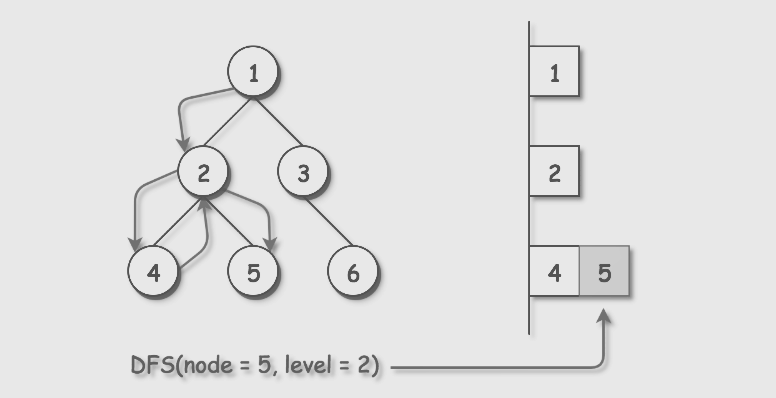
-
时间复杂度:O(N),其中N是树中节点的数量。
-
空间复杂度:O(H),其中H是树的高度。
2.1.2 该题的伪代码
vector<vector<int>> zigzagLevelOrder(TreeNode* root)
{
调用递归函数
返回res
}
void addVector(TreeNode* root,int level)
{
level表示层数,也对应二维数组的第一层索引,
如果为偶数行
顺序加入
如果为奇数行
将数字每次插入到最前面
调用递归函数
}
2.1.3 运行结果

2.1.4分析该题目解题优势及难点。
解题优势:不需要维护双端队列,调用堆栈大小刚好等于节点所在层数,因此空间复杂度要小于其他解题方法。
难点:队列的调用比较精密抽象,需要形象理解。
2.2 题目及解题代码
题目
解题代码
class Solution {
public:
Node* connect(Node* root) {
if (root == NULL ) return root;
queue<Node*> q;
q.push(root);
while ( ! q.empty() ){
int q_size = q.size();
Node *tmp = NULL;
while ( q_size-- ){
Node* node = q.front();
q.pop();
if ( node == NULL ) continue;
node->next = tmp;
tmp = node;
q.push(node->right);
q.push(node->left);
}
}
return root;
}
};
2.2.1 该题的设计思路
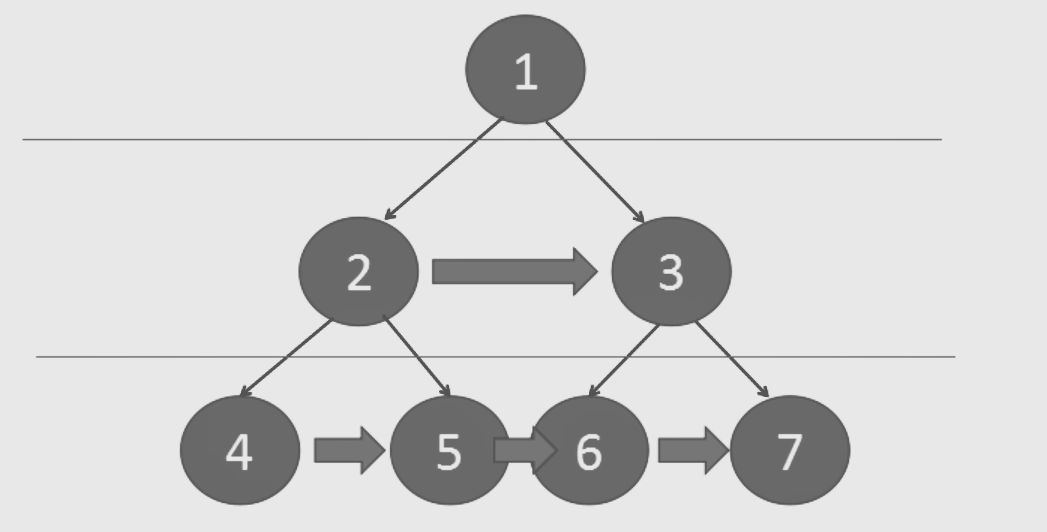
-
时间复杂度:O(n)
-
空间复杂度:O(n)
2.2.2 该题的伪代码
Node* connect(Node* root)
{
外层循环,遍历所有的node
获取当前层的Node数
创建一个临时tmp,赋值为NULL
内层循环,根据Node数,遍历当前层所有Node
获取当前的node
如果node为空,跳过后续操作
如果node不为空,将当前节点的next指向tmp
将tmp赋值为当前节点
加入当前节点的right和left
}
2.2.3 运行结果

2.2.4分析该题目解题优势及难点。
解题优势:使用广度优先遍历,可以将同一层级的所有节点连接起来。
难点:这种方法节点多了一个层级属性,需要创建一个新的数据结构,效率很低。还会创建与层级数量相同个数的 NULL 元素,造成过多内存消耗。
2.3 题目及解题代码
题目
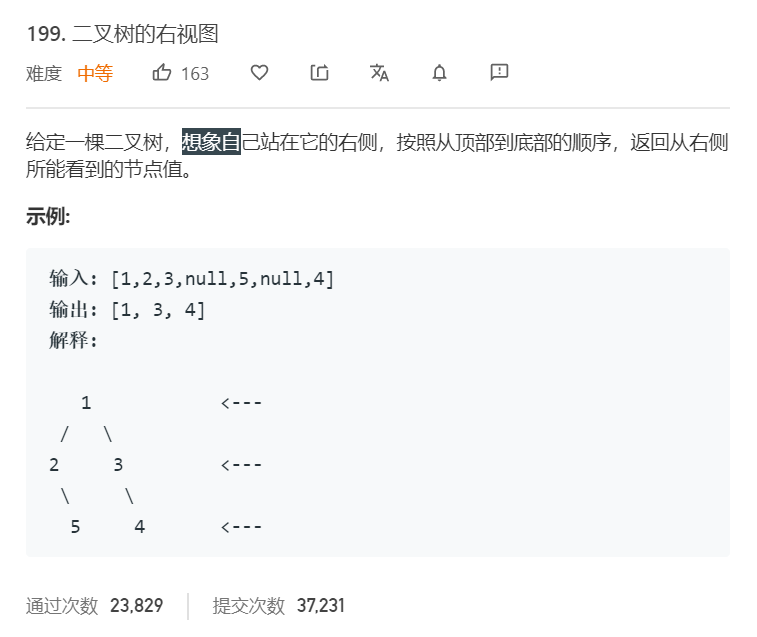
解题代码
class Solution {
public:
vector<int> ans;
vector<int> rightSideView(TreeNode* root) {
if(root == NULL) return ans;
queue<pair<TreeNode*, int>> tq;
tq.push({root, 0});
int tmp = 0;
int cur = root->val;
while(!tq.empty()){
auto pr = tq.front(); tq.pop();
TreeNode *root = pr.first;
int h = pr.second;
if(h > tmp){
tmp = h;
ans.push_back(cur);
}
cur = root->val;
if(root->left) tq.push({root->left, h+1});
if(root->right) tq.push({root->right, h+1});
}
ans.push_back(cur);
return ans;
}
};
2.3.1 该题的设计思路
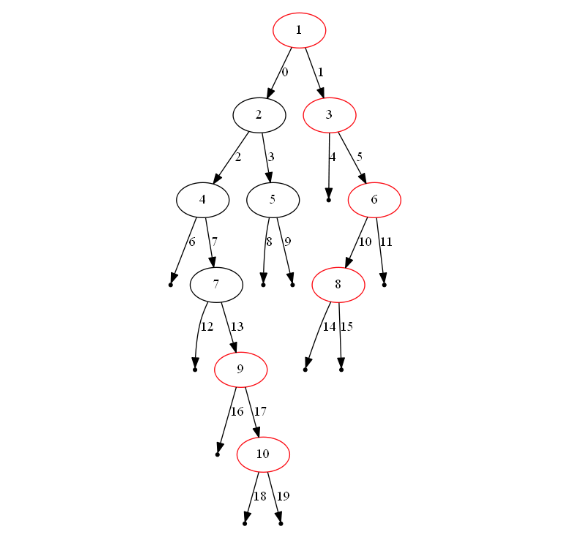
时间复杂度:O(n)
空间复杂度:O(n)
2.3.2 该题的伪代码
vector<int> rightSideView(TreeNode* root)
{
定义一个队列存储节点及其深度
初始时队列只有一个元素{root,0}
定义备选右视图元素
初始为树根的值
弹出队首元素
若已经进入了下一层
将上一层的最后那个右视图备选元素加入到结果集ans中
循环执行步骤2.,直到队列为空
返回结果集ans
}
2.3.3 运行结果
2.3.4分析该题目解题优势及难点。
解题优势:通过执行将左结点排在右结点之前的广度优先搜索,对每一层都从左到右访问。因此,通过只保留每个深度最后访问的结点,就可以在遍历完整棵树后得到每个深度最右的结点。
难点:由于广度优先搜索逐层访问整棵树,在访问最大的层之前,队列将最大。该层最坏的情况下可能有0.5n=O(n)大小(一棵完整的二叉树)。
2.4 题目及解题代码
题目
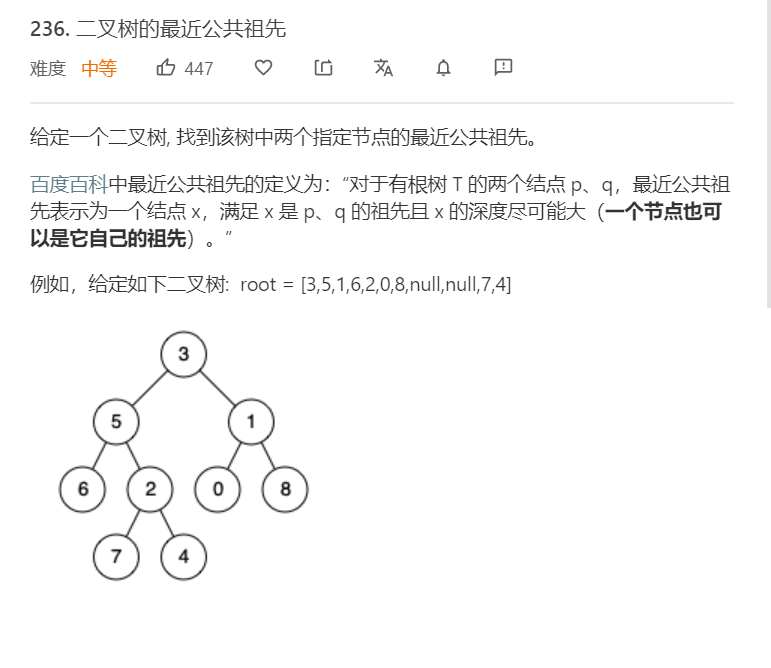
解题代码
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (!root || root == p || root == q) return root;
TreeNode *left = lowestCommonAncestor(root->left, p, q);
TreeNode *right = lowestCommonAncestor(root->right, p, q);
if (left && right) return root;
return left ? left : right;
}
};
2.4.1 该题的设计思路
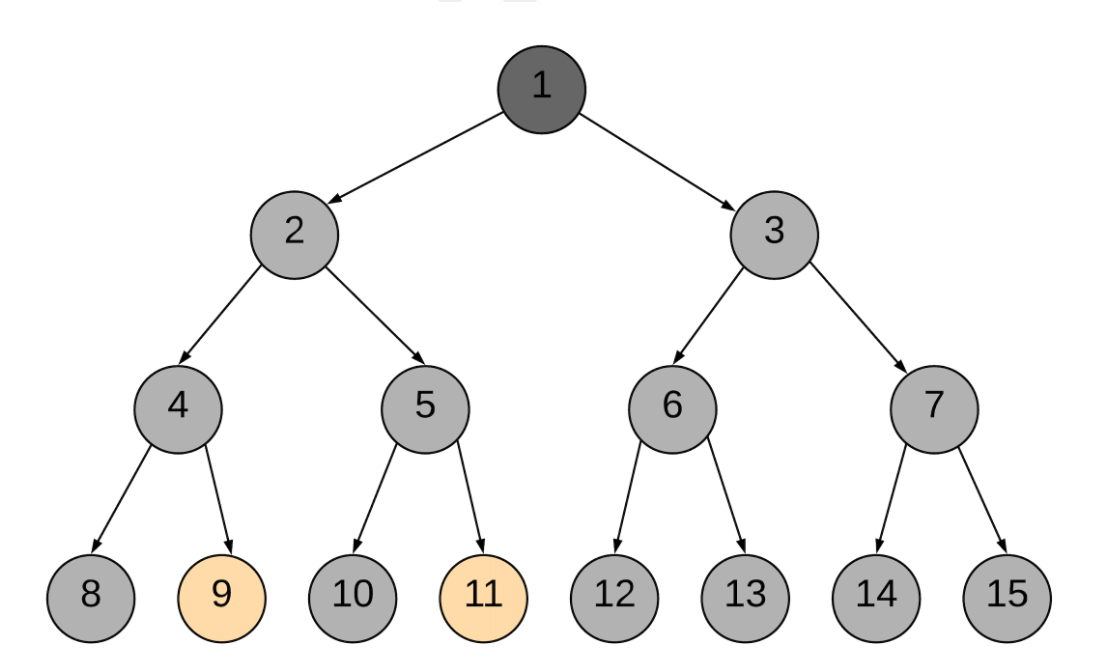

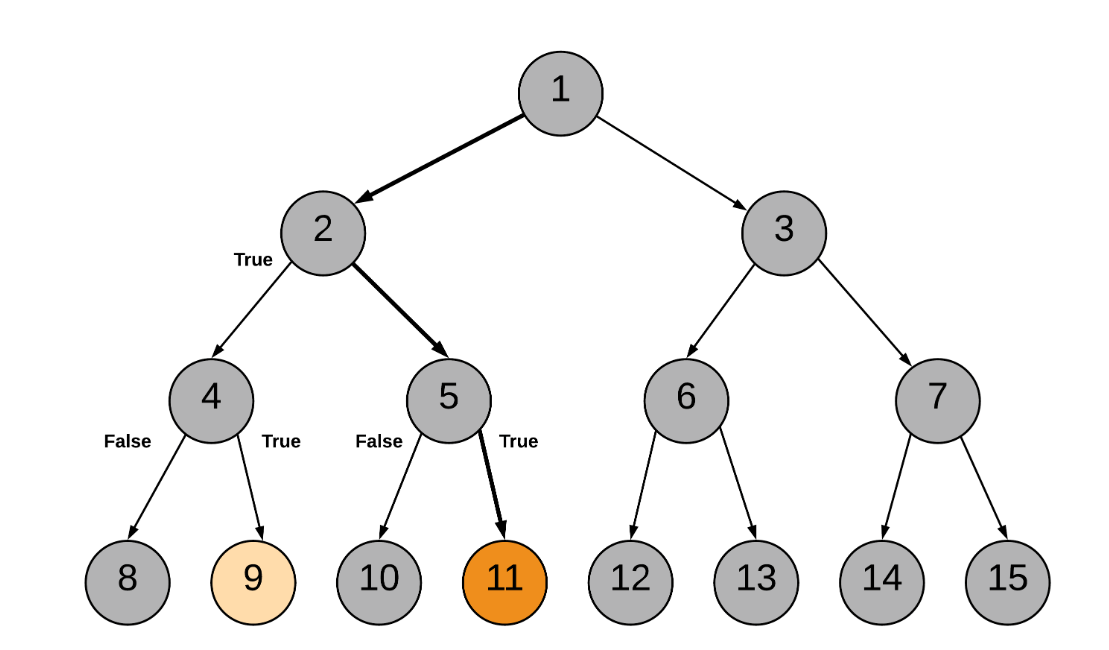
时间复杂度:O(n)
空间复杂度:O(n)
2.4.2 该题的伪代码
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{
如果当前节点为空或等于p或q
返回当前节点,递归终止
递归遍历左右子树
如果左右子树查到节点都不为空
表明p和q分别在左右子树中,当前节点即为最近公共祖先;
如果左右子树其中一个不为空
返回非空节点。
}
2.4.3 运行结果

2.4.4分析该题目解题优势及难点。
解题优势:解题思路清晰。从是否在一颗子树角度想,在不同子树时就返回root,当p为q的祖先节点时,搜索一侧子树只能返回p,这时候搜另一边是搜不到q的,但节点又一定在树中,所以一定是p是q的祖先的情况,直接返回p即为答案。
难点:就算在中途就找到了最近公共祖先节点,也仅仅是记录下来,整个递归过程并没有因此中断,还是会执行到最后,直到将所有节点全部访问一遍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号