


Camus使用过程中业务方反映从Kafka导入至HDFS中的数据有中文乱码问题,且业务方确认写入的数据编码为UTF-8,开始跟进。
问题重现:
(1)编写代码将带有中文的字符串以编码UTF-8写入Kafka的某个Topic;
(2)将该Topic的数据通过Camus导入HDFS;
(3)查看HDFS中导入的文件数据;
确认有中文乱码问题存在,与业务方无关。
(1)写入


这是一个写入的代码片段,ProducerRecord是以字符串的形式设置的,而ProducerRecord中的key和value会通过“key.serializer”和“value.serializer”被序列化,这其中就会有字符编码问题,查看org.apache.kafka.common.serialization.StringSerializer的源码:
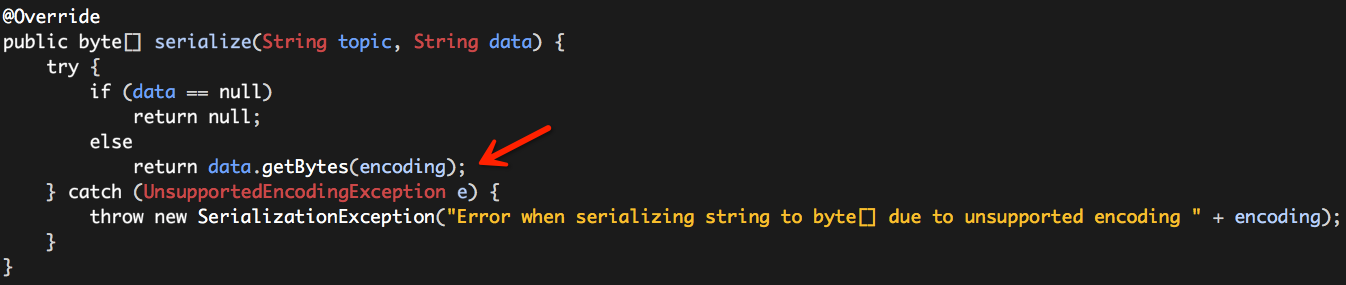
而“encoding”的值来源于下面的代码片段:
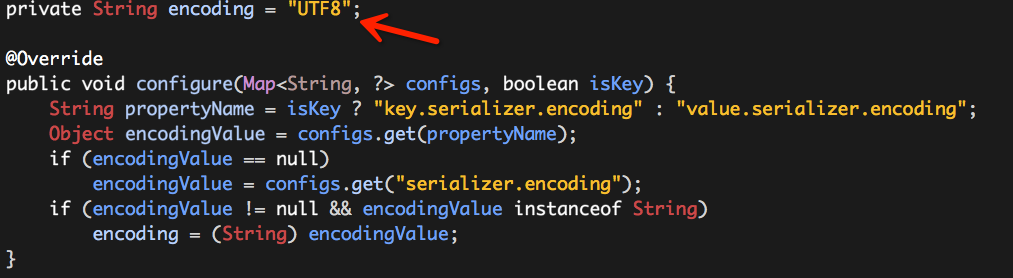
也就是说“encoding”在没有显示设置的情况下,默认就是“UTF8”。
(2)导入
通过查看Camus的相关配置文件,有两个属性需要注意:


从属性名称以及注释可以推断出,这两个属性值均与数据的编码、解码相关,查看它们的源代码。
com.linkedin.camus.etl.kafka.common.StringRecordWriterProvider
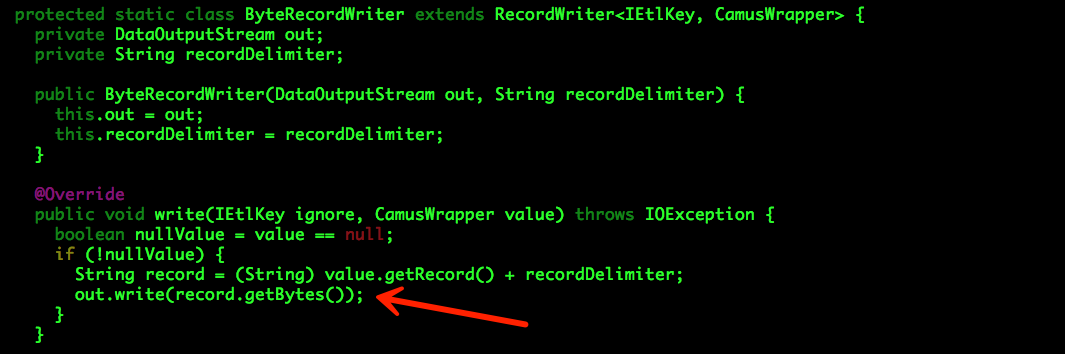
可以看出,StringRecordWriterProvider使用的是系统的默认编码,可能存在隐患。
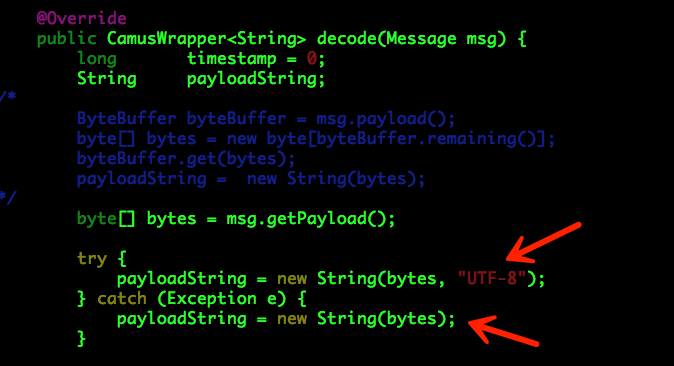
com.linkedin.camus.etl.kafka.coders.KafkaStringMessageDecoder(DIP自主开发)
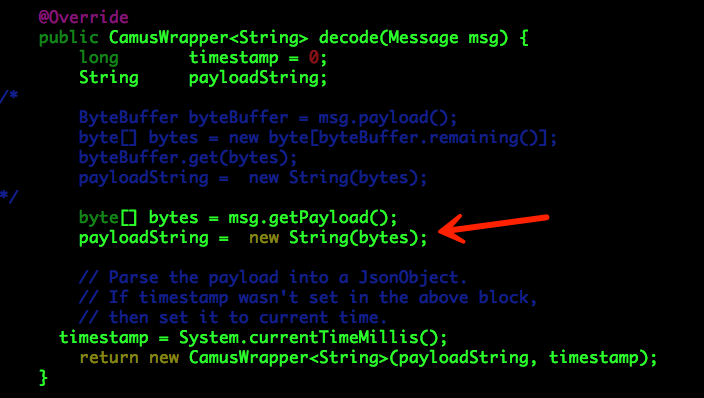
可以看出,KafkaStringMessageDecoder使用的是系统的默认编码,可能存在隐患。
综上所述,业务方写入时(默认)使用UTF-8编码进行导入,如果我们Hadoop集群的某些节点编码不是UTF-8就可以出现中文乱码问题(以前出现过类似的问题)。
解决方案:显示设置上述两个操作的编码。
com.linkedin.camus.etl.kafka.common.StringRecordWriterProvider
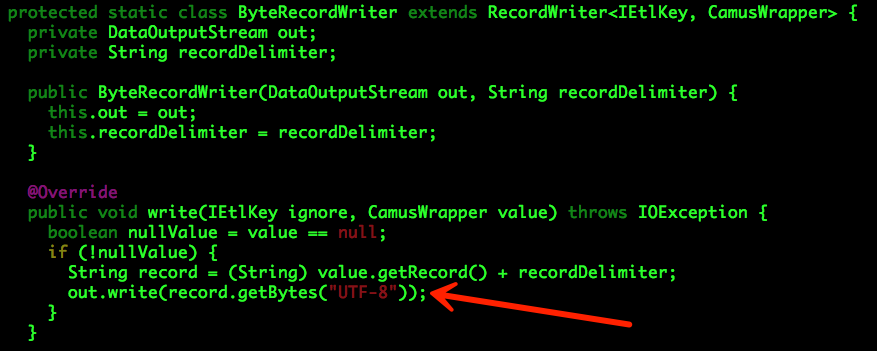
com.linkedin.camus.etl.kafka.coders.KafkaStringMessageDecoder
编译代码之前,需要修改以下两个地方:
./camus-schema-registry-avro/pom.xml

./pom.xml
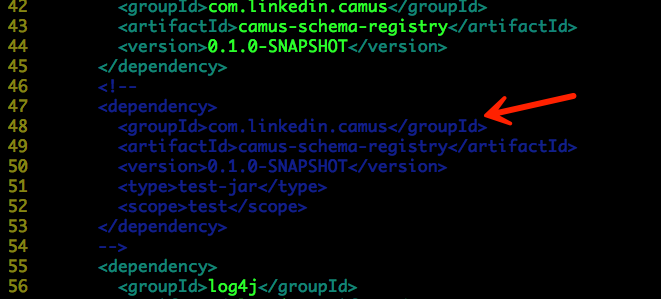
否则编译过程中会出现以下异常:

编译命令如下:
mvn clean package -Dmaven.test.skip=true
最终生成的部署包位于:dip_camus/camus-example/target/camus-example-0.1.0-SNAPSHOT-shaded.jar
测试命令如下:
sudo -u hdfs hadoop jar camus-example-0.1.0-SNAPSHOT-shaded.jar com.linkedin.camus.etl.kafka.CamusJob -P k1001_camus.properties
请验证,中文正常显示,问题解决。

