


背景
平台HDFS数据存储规则是按照“数据集/天目录/小时目录/若干文件”进行的,其中数据集是依据产品线或业务划分的。
用户分析数据时,可能需要处理以下五个场景:
(一)分析指定数据集、指定日期、指定小时、指定文件的数据;
(二)分析指定数据集、指定日期、指定小时的数据;
(三)分析指定数据集、指定日期的数据(24个小时目录的数据);
(四)分析多个数据集、多个日期或多个小时的数据;
(五)多种存储格式(textfile、sequencefile、rcfile等)。
目前我们平台提供给用户的分析工具为PySpark(Spark、Spark SQL、Python),本文讨论的就是使用PySpark如果应对上述场景。
示例
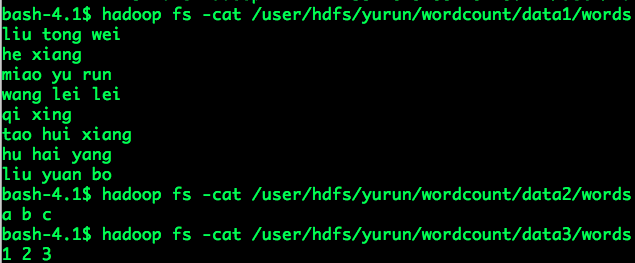
假设HDFS存在一个wordcount目录,包含三个子目录:data1、data2、data3,

这三个子目录下均含有一个文本文件words,各自的内容如下:
解决方案
这里我们暂时只考虑文本文件。
1. 分析指定数据集、指定日期、指定小时、指定文件的数据;
2. 分析指定数据集、指定日期、指定小时的数据;
SparkContext textFile默认情况下可以接收一个文本文件路径或者仅仅包含文本文件的目录,使用该方法可以应对场景(一)、(二)。
(1)分析指定文本文件的数据,这里我们假设待分析的数据为“/user/hdfs/yurun/wordcount/data1/words”:
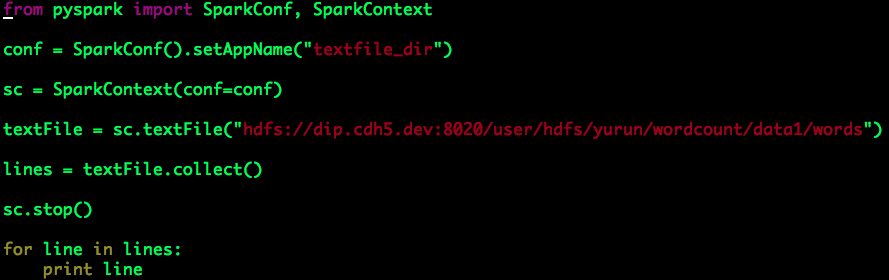
可以得到如下输出:

(2)分析指定目录的数据,且该目录仅包含文本文件,这里我们假设待分析的数据为“/user/hdfs/yurun/wordcount/data1/”:
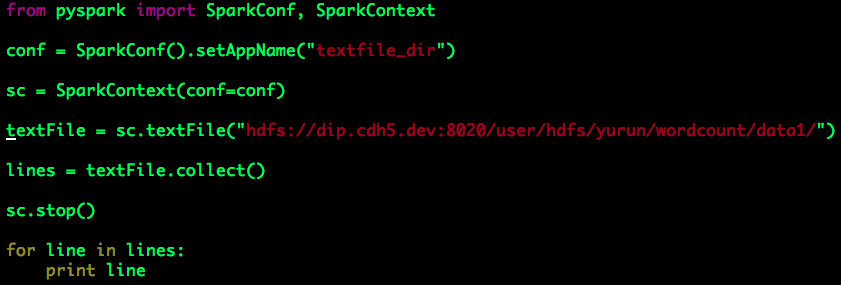
运行上述代码会得到与(1)相同的结果。
3. 分析指定数据集、指定日期的数据(24个小时目录的数据);
针对我们的示例,也就是需要“递归”分析wordcount目录下三个子目录data1、data2、data3中的数据。我们尝试将上面示例中的输入路径修改为“/user/hdfs/yurun/wordcount/”,
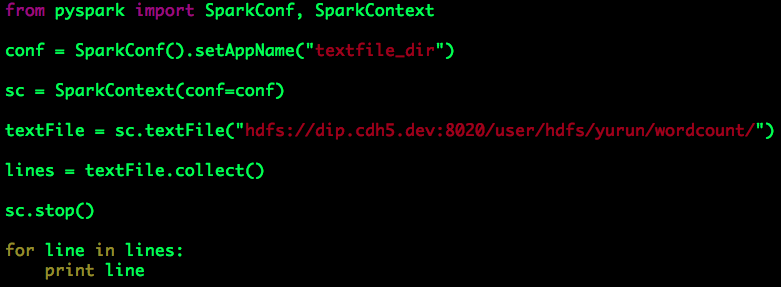
运行上述代码会出现异常:

根据1、2、3中的示例,如果我们指定的输入路径是一个目录,而这个目录中存在子目录就会出现上述异常。究其原因,实际上与FileInputFormat(org.apache.hadoop.mapred.FileInputFormat)的“某个”配置属性值有关。
注意:源码中有两个模块中都包含这个类,

这里使用的是模块hadoop-mapreduce-client中的类。
根据抛出的异常信息,我们可以在FileInputFormat的源码中找到如下代码块:
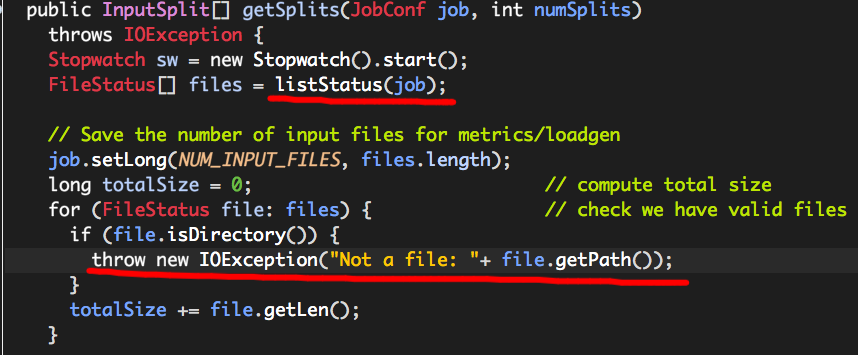
可以看出,如果files中的任何一个FileStatus实例(由file表示)为目录,便会引发“Not a file”的异常,而files来源于方法listStatus,
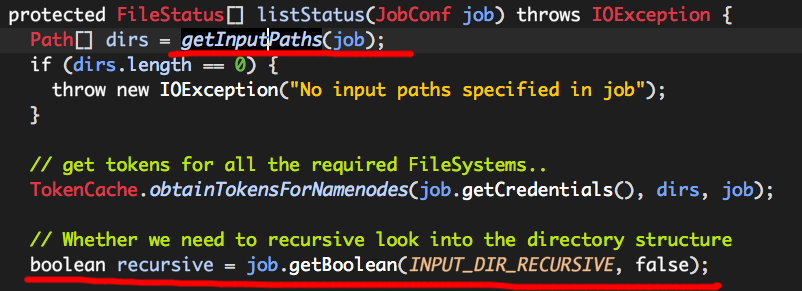
我们需要注意两个很重要的变量:
(1)dirs
dirs为我们指定的输入文件或目录,它是由getInputPaths计算而来的,
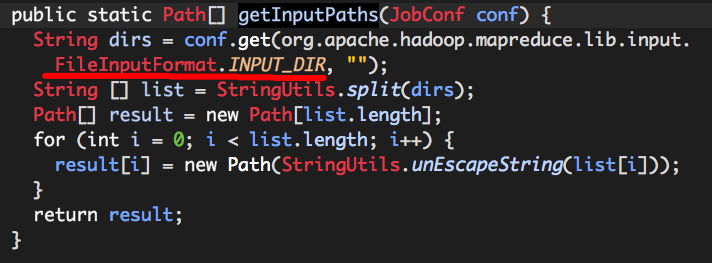
可以看出,我们通过SparkContext textfile指定的输入路径实际是保存在Configuration中的,以属性FileInputFormat.INPUT_DIR(mapreduce.input.fileinputformat.inputdir)表示,从代码逻辑可知,它的值可以为多个以“,”分隔的字符串。
与就是说,理论上我们是可以指定多个输入文件或目录的(SparkContext textfile仅支持单个文件路径或目录路径)。
(2)recursive
如果我们指定的是一个目录路径,recursive表示着是否允许在后续的切片计算过程中“递归”处理该路径中的子目录,它的值由属性INPUT_DIR_RECURSIVE(mapreduce.input.fileinputformat.input.dir.recursive)决定,默认值为false。
也就是说,默认情况下,FileInputFormat是不会以“递归”的形式处理指定目录中的子目录的,这也是引发上述异常的根本原因。
如果我们需要处理“递归”目录的场景,可以采用下述两个方法:
(1)在Hadoop的配置文件mapred-site.xml中添加属性mapreduce.input.fileinputformat.input.dir.recursive,并指定值为true;

仅仅需要在Spark Client(提交Spark Application的机器)相关机器上操作即可,不需要修改Hadoop集群配置。
修改配置文件后,再次提交上述程序,即可正常执行。
(2)使用hadoopRDD;

这种方式不需要修改配置文件,而是在代码中通过Hadoop Configuration(hadoopConf)直接指定相关属性:
mapreduce.input.fileinputformat.inputdir:hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/wordcount/;
mapreduce.input.fileinputformat.input.dir.recursive:true;
此外还需要注意hadoopRDD的几个参数:
inputFormatClass:org.apache.hadoop.mapred.TextInputFormat
keyClass:org.apache.hadoop.io.LongWritable
valueClass:org.apache.hadoop.io.Text
这仅仅是针对textfile设置的参数值,对于其它的数据格式会有所不同,后面会讨论。
使用hadoopRDD的运行结果会有所不同:
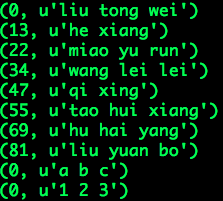
这是因为SparkContext textfile省略了TextInputFormat中的“key”,它表示每一行文本在各自文件中的起始偏移量。
4. 分析多个数据集、多个日期或多个小时的数据;
这种场景要求我们能够指定多个目录或文件,其中还可能需要“递归”处理子目录,SparkContext textfile只能接收一个目录或文件,此时我们只能使用hadoopRDD。
前面提到过,“mapreduce.input.fileinputformat.inputdir”可以以“,”分隔的形式接收多个目录或文件路径。假设我们需要分析的数据为“hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/wordcount/data1”、“hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/wordcount/data2”、“hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/wordcount/data3/words”,代码示例如下:

运行结果同上。
5. 多种存储格式;
1-4的讨论仅仅局限于textfile,textfile易于人的阅读和分析,但存储开销很大,即使采用相应的压缩,效果也并是很理想。在实践中我们发现rcfile采用列式压缩效果显著,因此也需要考虑如何使得PySpark支持rcfile。
为什么这个地方要有专门的“考虑”?
简单来讲,Hadoop是使用Java构建的,Spark是使用Scala构建的,而我们现在使用的开发语言为Python,这就带来一个问题:Java/Scala中的数据类型如何转换为相应的Python数据类型?
如TextInputFormat返回的键值对类型为LongWritable、Text,可以被“自动”转换为Python中的int、str(基本数据类型均可以被“自动”转换),RCFileInputFormat返回的键值对类型为LongWritable、BytesRefArrayWritable,BytesRefArrayWritable不是基本数据类型,它应该如何被转换呢?
我们查看SparkContext hadoopRDD的文档可知,

keyConverter、valueConverter就是用来负责完成键值类型的转换的。
假设我们有一个RCFile格式的文件:

RCFileInputFormat的键类型为LongWritable,可以自动被转换;
RCFileInputFormat的值类型为BytesRefArrayWritable,无法被自动转换,需要一个Converter,这里我们把每一个BytesRefArrayWritable实例转换为一个Text实例,其中三列数据以空格分隔。
我们将Converter定义为BytesRefArrayWritableToStringConverter(com.sina.dip.spark.converter.BytesRefArrayWritableToStringConverter),代码如下:
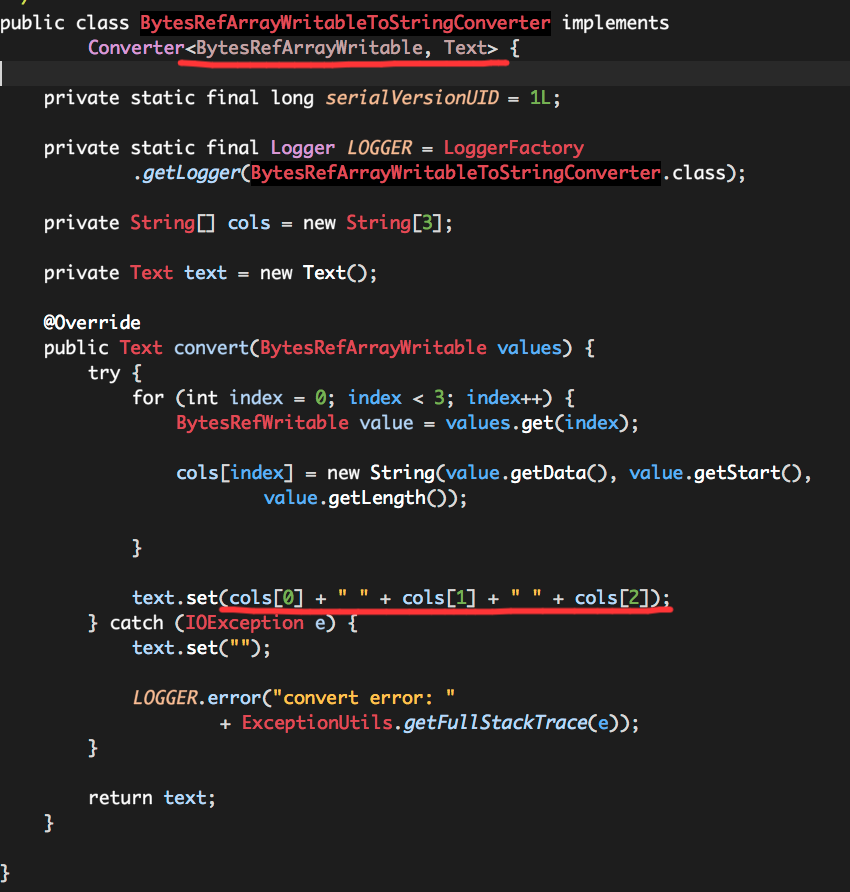
其实Converter的逻辑非常简单,就是将BytesRefArrayWritable中的数据提取、转换为基本数据类型Text。
将上述代码编译打包为converter.jar。
PySpark代码如下:

重点注意几个参数值:
mapreduce.input.fileinputformat.inputdir:hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/rcfile/data
inputFormatClass:org.apache.hadoop.hive.ql.io.RCFileInputFormat
keyClass:org.apache.hadoop.io.LongWritable
valueClass:org.apache.hadoop.io.Text
valueConverter:com.sina.dip.spark.converter.BytesRefArrayWritableToStringConverter
执行命令:

结果输出:
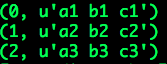
三行数据,每行数据均为字符串输出,且以空格分隔,可见数据得到正常转换。
通过上述方式,我们可以通过SparkContext hadoopRDD支持多种数据格式数据的分析。
总结
本文通过五种常见应用场景的讨论,可以得出使用PySpark可以支持灵活的数据输入路径,还可以根据需求扩展支持多种数据格式。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构