


背景
最近Hadoop集群的小量节点偶尔会因“/var/cache/logwatch”目录战胜空间过大(约3 - 5 GB左右),引发磁盘报警;最早开始是春节假期期间出现的,一开始的时候没太当回事儿,认为是个例,随手清除了事;后面有其它机器也不定时的会出现类似情况,觉得有问题,安排团队的一个小朋友跟进排查,最后大致的方案:“大家有没有使用logwatch的,如果没有的话,我就把它给停了”。
方案当时被我给否定了,建议还是继续研究,主要有两方面的考虑:
logwatch应该是系统(公司统一预装)内置服务,应该已经默默地正常运行好长时间,最近才出现异常,肯定是有一些原因导致的;
logwatch是干什么的,不知道;
然后,然后,...,没有音信。
过程
今天早上的时候,大概有3-5台左右的机器同时出现“/var”磁盘报警,想想就是因为“/var/cache/logwatch”导致的,同时也验证之前的一个假设:问题不是个例,需要研究明白。考虑到问题不是很紧急,于是按部就班地健身,喝牛奶,然后坐到桌前,打开电脑...。在群里问了一下小朋友,logwatch相关的进展,因为时间还比较早,没有收到回应。一直以来,我自己对报警的容忍程度是比较低的,那就自己先看看吧。
登录有报警的1-2台机器,确认是“/var/cache/logwatch”的问题。因为之前完全不知道logwatch是什么,百度一下,大致了解到:
logwatch是用来搜集汇总系统服务日志的,具体哪些服务,可以通过配置文件指定;
logwatch是通过Crontab定时调度的,每天一次;
“/var/cache/logwatch”是logwatch的临时目录,应该就是logwatch运行过程中用于存储临时文件的;
关于“/var/cache/logwatch”为什么会占用大量空间,临时文件没有自动清理机制?百度+Google,没有查到有用的信息。既然它是通过Crontab定时调度的,自己就手动试试呗。大概看了一下定时调度的配置,本质就是执行命令:“logwatch”。
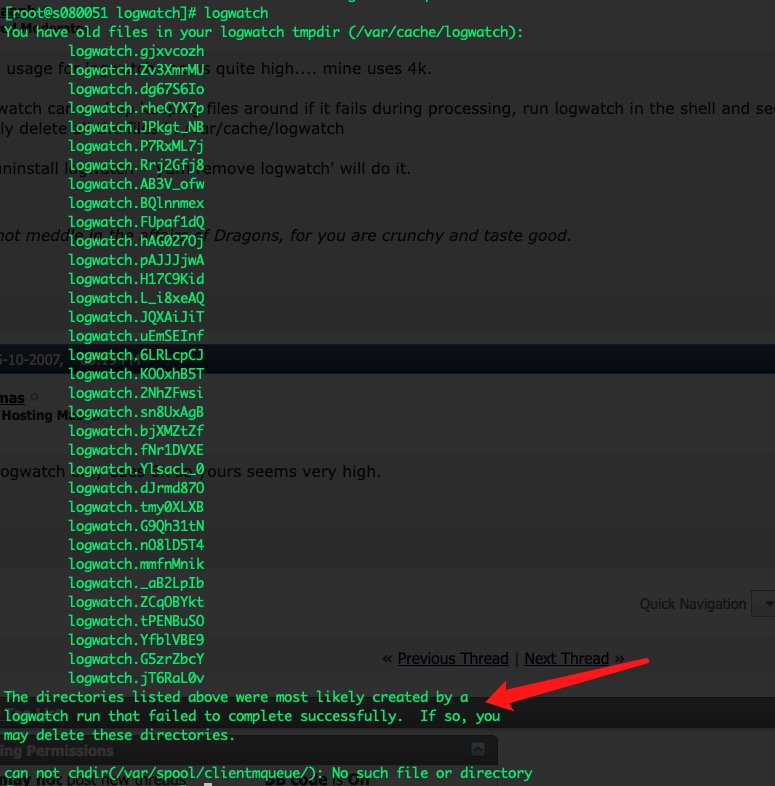
命令输出的其中一句话引起了我的注意:“The directories listed above were most likely created by a logwatch run that failed to complete successfully.”。简单理解,这些目录(临时文件目录)是因为logwatch没有正常执行成功才产生的。果然是有原因的!
然后,又注意到末尾的一个提示:“can not chdir(/var/spool/clientmqueue/): No such file or directory”,找不到这个目录,一下子明白问题了。
目录“/var/spool/clientmqueue”下面经常会有大量的小文件(具体原因,自查),有时会导致INode被耗尽,导致其它一些服务异常。集群的大部分节点是部署有相应的清理脚本的,会每天删除目录里的临时文件。同时,有少量历史节点是没有部署清理脚本的,估计春节前做服务保障的时候,正好有异常情况出现,上面的小朋友直接把整个集群的“/var/spool/clientmqueue”给删除了!
小朋友也“招供”了,自己默默地修复!
结论
系统服务异常的时候,不要轻易放过,很多同学都会有偷懒的心理(我自己也有),怎么省事怎么来;作为负责人,一定要负责,细节可以不细纠,但最起码也应该弄清楚个大概(具体的度自己理解);解决方式也不能太过简单粗暴,还是谨慎稳妥比较好。

