(译)用于多选式阅读理解任务的基于BERT的模型
A BERT based model for Multiple-Choice Reading Comprehension
Abstract
在本文中,我们提出了一个基于BERT的深度协同匹配网络(DCN),该网络的性能与RACE数据集上的基线模型相比有了显著的提高。我们的DCN方法通过计算文章/问句之间的注意力权重来获得问句感知的文章表示,同理,我们也通过计算文章/选项之间的注意力权重来获得选项感知的文章表示。我们对基线模型的超参进行了微调,并应用了简单数据扩张策略。我们的DCN模型在RACE上实现了66.2%的准确率。最终,我们基于所有的模型建立了集成模型,该模型实现了67.9的准确率,此性能在RACE数据集上排第6名。
1 Introduction
自动阅读理解可被广泛应用于商业领域中,例如技术支持和故障排除、客户服务、医疗记录和金融报告的理解等。本报告将探索如何使得计算机在文本理解任务中达到人类水平。如果智能代理真的可以通过学习算法在无人类监督的情况下快速高效地理解文本,那么许多依赖于自动化的行业都将从中受益。在众多文本理解任务中,本项目主要集中于RACE数据集上的自动多选式阅读理解任务。与SQuAD那种文本写作风格固定且单一的数据集相比,RACE数据集中的答案并不能从原文中直接提取,这是因为回答这些问题需要更高水平的理解和推理。具体来说,它有以下挑战:
(1) 它是由人类专家创建用于测试高中和初中学生的阅读理解技能的,因此它要求更高水平的推理和计算技术。
(2) 它包含的问题类型多样,比如总结、推理、数值计算和内容匹配。
(3) 它的文章涉及多个领域,写作风格迥异。
因此,为解决上述挑战,本报告将以四种方式处理机器阅读理解问题:一种是通过预训练的BERT算法,其他的分别是通过我们提出的DCN方法、AOA方法以及将上述三种进行集成的模型。我们对这些基础模型的超参进行了微调,并且应用了简单数据扩张的策略。我们通过集成技术将所有模型结合起来,希望在多选式阅读理解中能实现最优性能。
1.1Problem definitions
我们算法的输入是由一篇文章、一个问题和一个选项组成的一个序列。随后我我们使用BERT、AOA、DCN和集成模型去预测该问题的正确答案。
为了测试该模型在给定文章和问题的情况下预测出正确答案的成功性,我们将根据模型预测出的正确答案的数量与数据集中的问题总数之间的百分比来评估模型的性能。因此,整个项目中都是用accuracy作为评测指标来验证我们模型的性能,该指标定义如下:
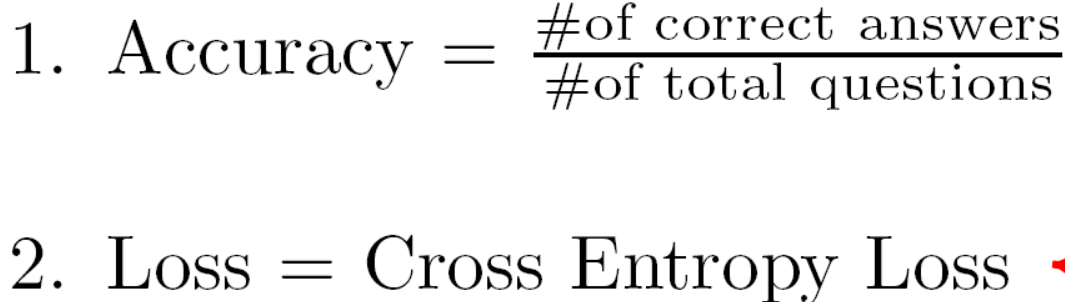
2 Related Work
已经有很多机器学习模型成功解决了阅读理解问题。也有很多数据集(AQuAD、NEWSQA和METest)被广泛用于测试这些模型。然而,这些数据集的内容均来自一个特定领域或以一种固定的写作风格得到的,并且还有基于范围的答案。因此,我们通过选择一个相对较新的数据集来挑战自己,RACE包含了多种主题和写作风格的文章,因此,我们模型的目的是要接近人类的逻辑思维和理解能力。
先前的论文主要关注成对序列匹配以提高神经网络的阅读理解能力。无论是匹配一篇文章和相应问题、选项的联接结果,还是匹配一篇文章与问题,然后去选择答案,这些方式都是有效的。在这些文献中,许多类型的注意力被提出去强化神经网络在文章级别的推理能力。Xu等人使用多跳推理机制从而提出了动态融合网络。Zhu等人提出了分层注意力流用于建模文章、问题和选项之间的交互。BERT实现了七个NLP任务的最优结果。受双协同匹配注意力的启发,我们提出了基于BERT的DCN。
3 Dataset and Features
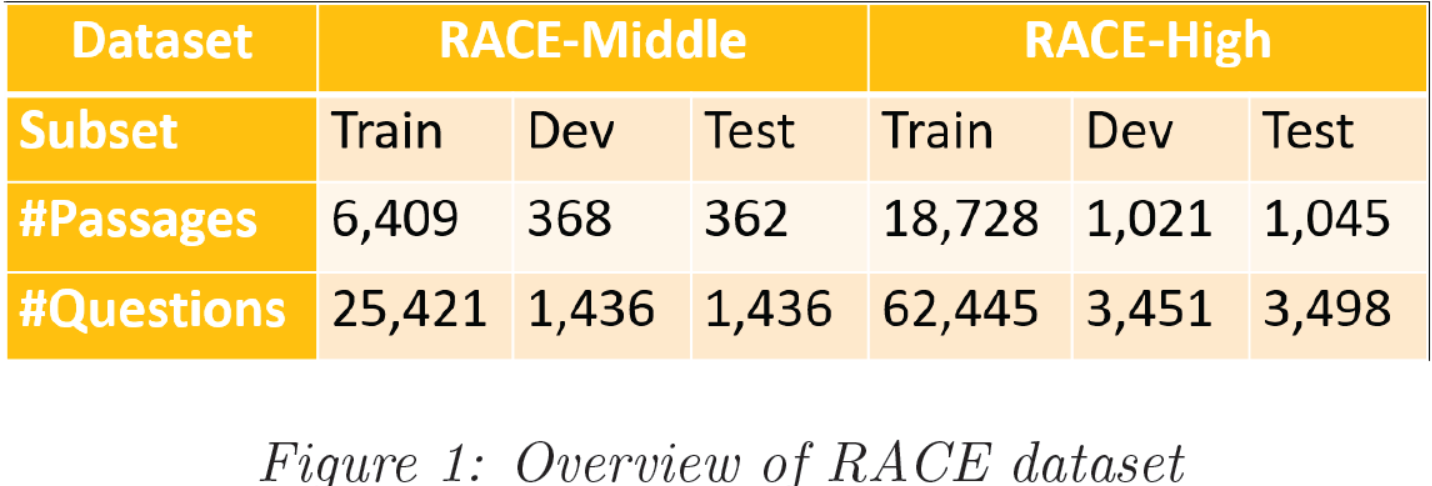
RACE数据集包含初中部分和高中部分。如图1所示,RACE-Middle中有7139篇文章,RACE-High中有20794篇文章。此外,文章加起来总共27933,问题加起来总共97687。如果我们想看一下每个子数据集的情况,我们可以很轻松的观察到这两个子集的训练集:测试集:验证集为9:0.5:0.5。我们也计算了初中集部分的文章平均约为250个词,高中集部分的文章平均约为350个词,这将为基线模型选择正确的最大序列长度提供很好的参考。
3.1 Data Preprocess
我们将一篇文章、一个问题和一个选项及特殊标记CLS和SEP联接起来作为BERT模型的输入序列。因此,对于每个问题,我们将有4个这样的输入,并将正确选项的标签作为真实标签并预测答案。

3.2 Data Augmentation
简单数据扩张(EDA)原本是用于强化小规模数据集上的文本分类任务的。EDA打算通过以下操作来创建新文章和增强文章:
(1) 通以此替换:随机选择一些非停用词。用它们的同义词来替换它们。
(2) 词插入:找到一句话中某个非停用词。在这句话中的随机位置插入其同义词。
(3) 词交换:随机选择两个词进行位置交换。
(4) 词删除:以指定的概率随机删除句子中的单词。
因此,EDA扩大了现有数据集的大小和多样性。我们希望这可以训练过程中的过拟合问题,有助于建立更健壮的模型。
4 Methods
如前所述,我们探索了AoA模型、BERT、DCN和集成模型。
4.1 BERT
2018年BERT在11个NLP任务上实现了最优性能。我们的多选模型是基于HuggingFace实现的pytorch版本的BERT构造的,在BERT之后添加一个全连接层和一个softmax函数去预测正确答案。然后我们在RACE数据集上微调pre-trained uncased BERT作为我们的基线方法。基础版BERT和增大版BERT的编码层数量分别为12和24。

BERT通过多头注意力进一步完善了自注意力层。它在两方面提高了性能。一方面,它使得模型可以捕获长距离词义依赖。另一方面,它提供了表示子空间的能力。
最后,在我们实现的BERT模型中总共有15个超参。其中,我们选择了5个对模型性能影响最显著的超参进行实验。
(1) Learning rate:Adam优化器的初始学习率。
(2) Freeze layers:冻结BERT的部分编码层。该参数的取值取决于BERT的类型,因此其取值可能是6或12。
(3) L2 regularization:权重衰减率被设置为0.1,0.01,或0.001。
(4) Batch size:训练集中用于估计误差梯度的样本数。
(5) Max sequence length:输入序列的最大长度。长于此数值的序列被截断,小于此数值的序列被填充。
4.2 Attention over Attention
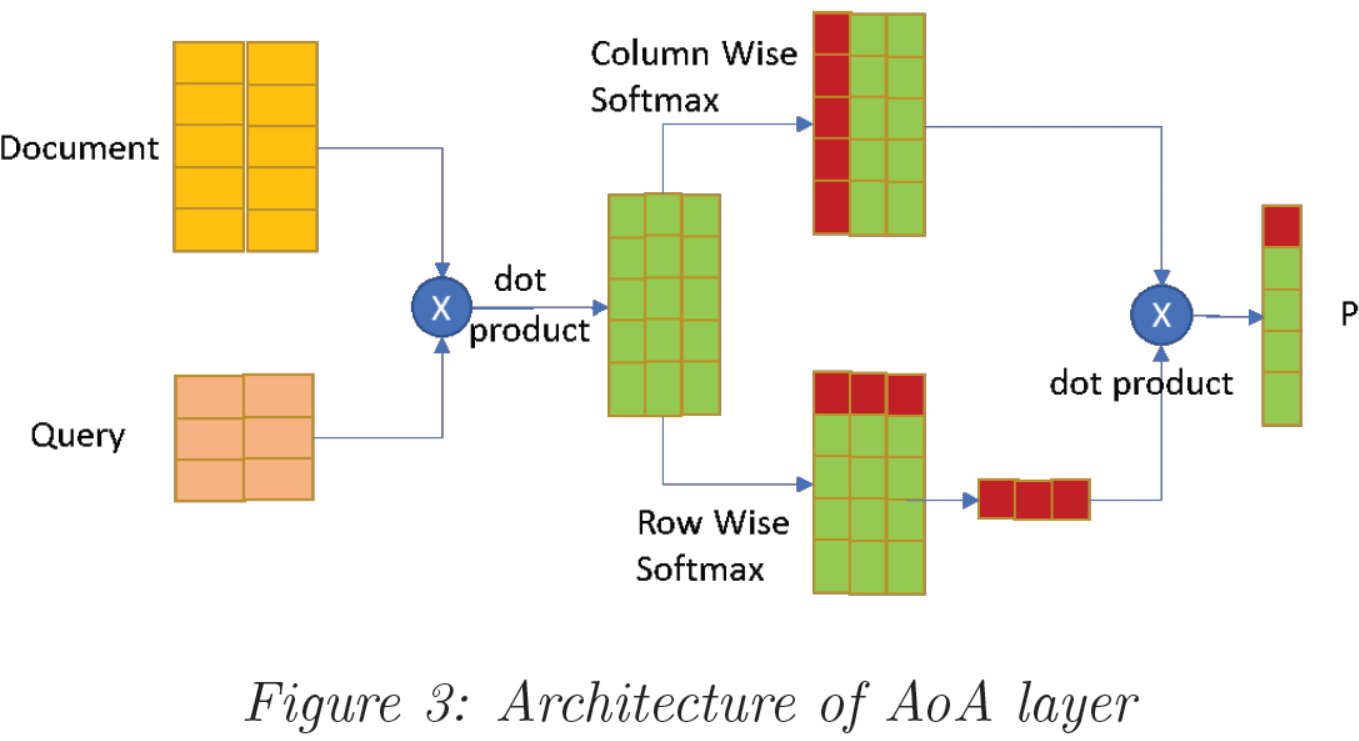
我们在此项目中的最初动机是进一步推动BERT中的注意力概念并引入AoA层到原始的BERT中去。这是一个相对较新的神经网络结构,它致力于在现有的文档级别的注意力之上使用另一种注意力机制。而不是仅仅为每个词汇总或平均单个注意力以获得最终的注意得分,在查询中执行额外的“重要性”分布,以确定在给定单个文档单词的情况下,哪些查询单词更重要。因此,它增加了可有效用于神经网络的信息。
我们可以得到按行softmax和按列softmax的结果,随后可获得一个新的变量Si。每个选项是正确答案的最终概率由如下公式获得:
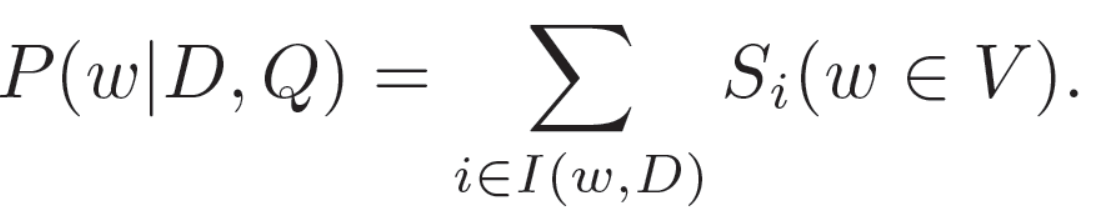
然而,我们很快意识到由于BERT结构的性能,AoA很难被集成到原始的BERT中去。
4.3 Deep Comatch Network
相反,我们通过引入问句感知的文章表示和选项感知的文章表示设计了DCN结构,以充分挖掘{文章、问句、选项}间的有效信息。在进入comatch层之前,网络先通过5层P2Q/Q2P和P2A/A2P coattention。该结构的输入就是BERT编码层输出的文章、问句和选项的隐状态。最后,分类层将在comatch块中的最大池化层之后输出预测的答案。
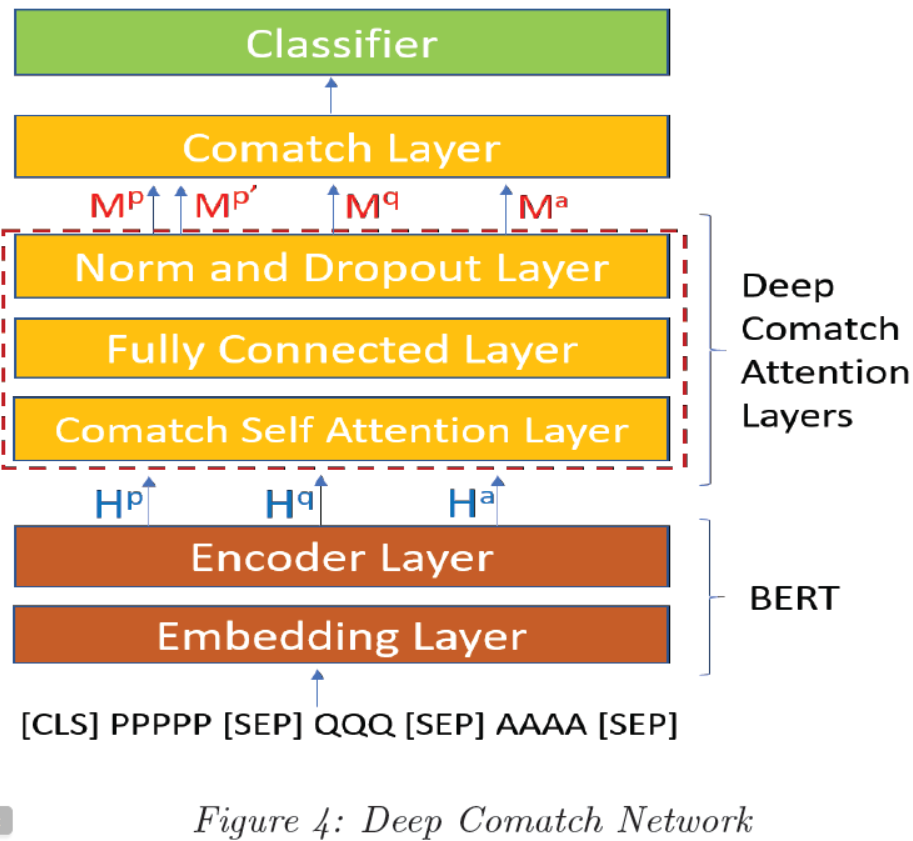
首先,文章、问句和选项有BERT进行编码:
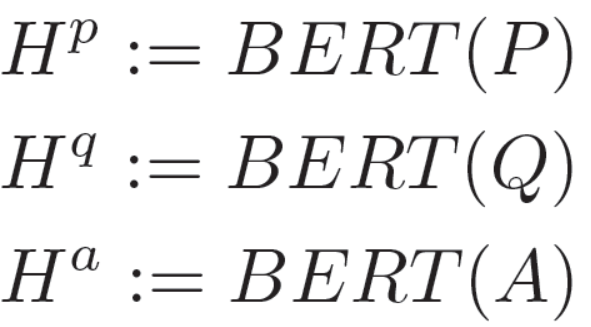
这里的Hp∈RP*L,Hq∈RQ*L,Ha∈RA*L是由BERT生成的隐状态。这里的P、Q、A分别是文章、问句和选项的序列长度,L是BERT隐状态的维度。
然后,我们使用如下公式处理P2Q/Q2P和P2A/A2P之间的coattention操作。注意,这里与先前的论文不同;在我们的模型中,我们还探索了文章和选项之间的(注意力)关系。

这里的-和.分别表示矩阵按元素相减和按元素相乘。[;]表示矩阵按行联接。我们用了不同的权重,因此我们获得了Sp和Sp`。然后我们联接经最大池化操作后的结果:
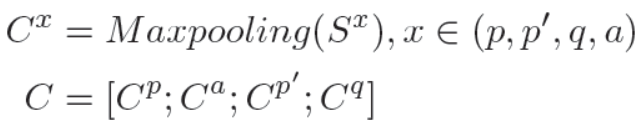
最后,我们计算分类其层输出结果的交叉熵损失函数值。
4.4 Ensemble
为进一步提高性能,我们也探索了集合所有上述技术的集成模型。在通过不同超参建立不同的BERT模型之后,我们将DCN和EDA数据集进行合并以得到一个集成模型。之后,我们将探索每个模型的相对权重并调整权重以获得更好的性能。
5 Experiments/Results
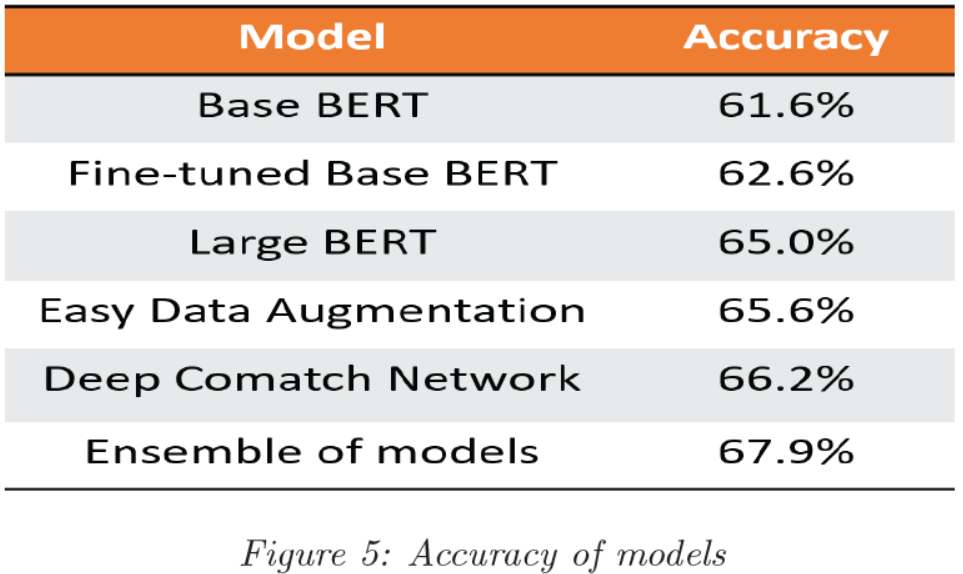
我们对基线模型的超参进行微调得到了62.2%的准确率。我们应用EDA得到了0.6%的提升。加上我们的DCN模型得到了66.2%的准确率。最终,我们建立的集成模型达到了67.9%的准确率,它在RACE排行榜上可排到第6名。
5.1 BERT
在本项目中,我们队BERT基础模型中的以下超参进行了实验。
5.1.1 Learning rate
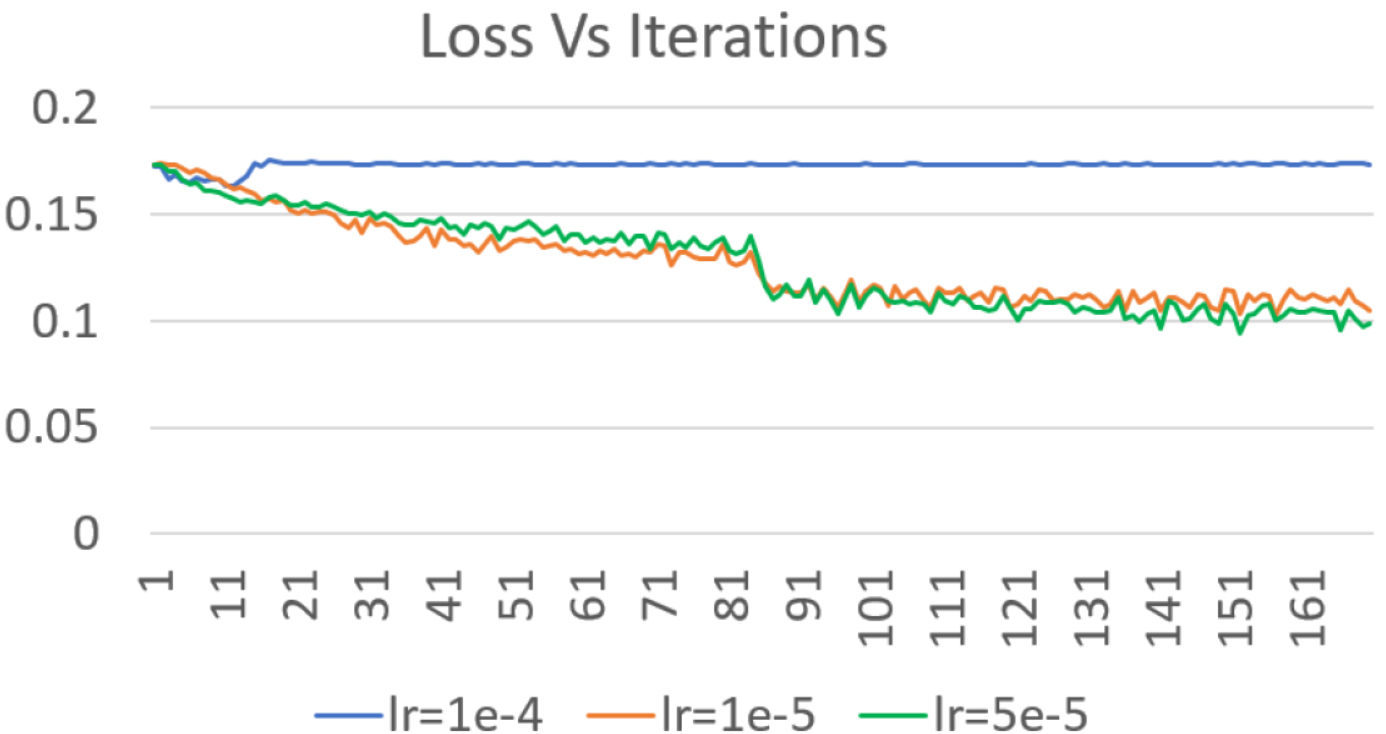
基于基线模型,我们尝试了三种初始学习率,即1e-5、5e-5和1e -4。结果如图4所示。学习率1e-4用蓝线表示,其损失先下降后上升并稳定在一个较高值,表明学习率太大。对于1e-5和5e-5这两个学习率,其损失都随着迭代次数的增加而减小。但是显然学习率5e-5可以获得更小的损失并提供最佳性能。迭代的单位是1K个样本。在学习过程中,由于学习率会动态变化,所以损失下降地会很大。
5.1.2 Freeze BERT encoder layers
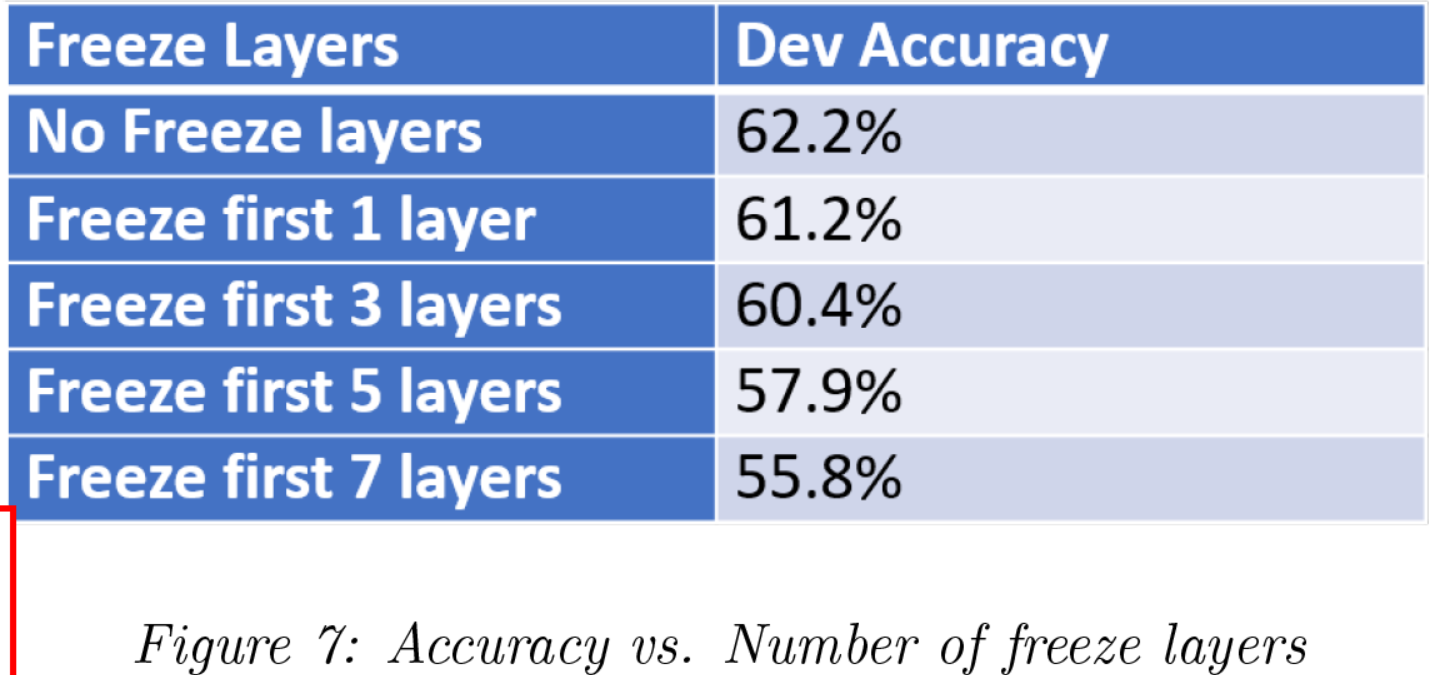
我们探讨了冻结层的数量对模型性能的影响。由于GPU内存限制,最大序列为320,batch size为8,结果如上表所示。从表中可以看出,随着冻结数的增加,性能越来越低。当冻结层数超过3层时,性能会下降地更快。
5.1.3 L2 regularization
此外,我们设置L2正则化系数分别为0.1、0.01和0.001探索了权重衰减参数。 我们获得了相应的性能,分别为62.1%,62.2%和62.1%。 因此,L2正则化为0.01时可获得最佳性能。
5.1.4 Batch size
由于BERT是一个庞大的网络,因此我们使用梯度累加技术来减少GPU内存需求。我们尝试了四种不同的批次大小:16、24、32和64。我们先将用于BERT训练的batch size大小设置为32,获得了61.9%的性能;但是,随着我们将batch size大小分别减小到24和16,准确性都提高了一点,分别达到62.3%和62.5%。 同样,当我们将批次大小增加到64时,准确性会降低。因此,似乎batch size大小在32、24和16间取值时可以达到最佳模型,但是batch size大小为16的模型性能最佳,这比batch size大小为24时高0.22%,比batch size大小为32时高0.65%。
5.1.5 Max sequence length
最大序列长度是一个超参数,在基于BERT的模型中起着至关重要的作用。最大序列长度从320增加到450时,性能提高了1.5%。我们先在BERT基本模型上对等于320的最大序列长度进行了测试,得出的准确度为61.1%。随着最大序列长度的增加,模型的性能也随之提高。对于最大序列长度分别取值380、420和480时,我们分别获得了61.3%,61.8%和62.6%的准确度。 因此,我们得出结论,更大的最大序列长度可以提高模型的准确性。从直觉上讲,这是正确的,因为某些段落的长度超过了400个单词。但是,模型大小与最大序列长度成比例,因此会导致更多的显存需求。由于资源有限,我们无法探索更多的长度。
5.2 Data Augmentation
我们将训练集整体提高了10%,一半是基于RACE-middle,另外一半是基于RACE-high的。我们仅对随机选择的段落应用了增强,并通过将其与原始问题和选项连接在一起进行了相同的预处理。在EDA中,有一个参数指示通过每种增强技术在每个段落中更改的单词百分比。例如,如果设置为0.1,我们的EDA实现将把10%的单词更改为其同义词,随机单词插入和交换将发生在单词总数的10%上,而10%的单词将被随机删除。我们将该参数分别设置为0.1、0.2、0.3和0.5进行了实验,每个参数分别实现了65.2%,65.6%,64.9%和64.9%的精度。因此,尽管精度差异不是很大,但取值0.2时得到了最佳性能。但是,与不使用EDA的大型BERT模型所获得的准确性相比,添加增加参数0.2的训练数据的10%可以使模型准确性提高0.6%。
因此,我们发现最好的性能达到了65.6%,如图5所示,与原始的RACE数据集相比,大约是获得了0.6%的提升。有两个可能的原因使得提高的并不多。一种是我们可能需要调整EDA的超参数,对不同的操作使用不同的比率,同义词替换应该噪声较小,但其他3种操作会增加更多的噪声。另一个原因是简单的数据扩充倾向于在一个小的数据集上很好地工作,但是我们的比赛包含6400篇文章,相对来说是一个大的数据集。
5.3 Deep Comatch Network
我们尝试将一些新的注意力应用于多选式阅读理解中。首先探讨的是在基础BERT模型中添加AoA层。然而却只获得了25.1%的准确率,该结果很低,这是由于当两个层在编码器层结合时,BERT的自注意层与AoA层相冲突。
然后,我们受深度comatch网络的启发设计了DCN。我们根据BERT隐藏输出创建了多层深度匹配网络。在深度网络中,我们设计了一个新的协同注意层,在BERT编码之后,我们又设计了5层协同注意层。我们的DCN通过关注文章/问题和文章/答案之间的关系,从问题感知的文章表示和答案感知的文章表示中获益。然而,由于GPU资源的限制,我们对DCN进行了三层训练,在DCN的单模模式下,训练精度达到了66.2%。
5.4 Ensemble
在探索了所有这些不同的模型之后,我们按照最初的计划创建了集成模型,因为我们确信集成学习可以帮助实现最佳性能。在保持模型最佳性能的前提下,采用随机搜索的方法来衡量基本和large-BERT、EDA和DCN之间的精度。最后,在集合模型中得到了67.9%的精度,如图5所示。换句话说,与DCN相比,我们的准确率提高了1.7%。这一结果保证了适当权重的集成学习可以提高机器学习的效果。
6 Analysis
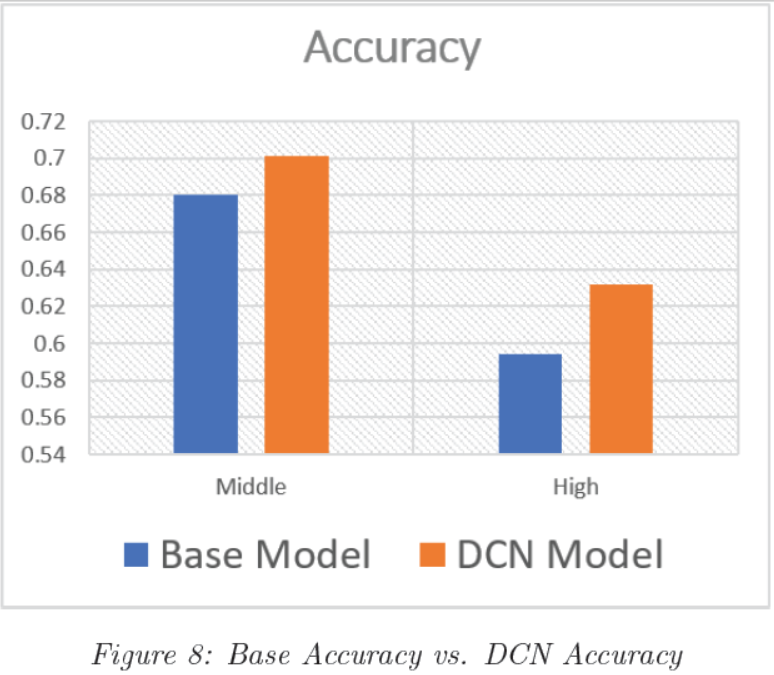
下图显示了DCN和基本模型之间的比较。DCN在高中和初中两个子数据集中的性能都优于基线。DCN在处理高中数据集中这种长而复杂的文章,其性能更为优越。
关键是,通过对BERT错误回答的问题的分析,发现该模型不能进行简单的数值推理。例如,在以下错误标记的情况下,第一个选项是正确的。虽然预测的(第二个)选项有更高的概率,但答案应该是45-18=27年前。
![]()
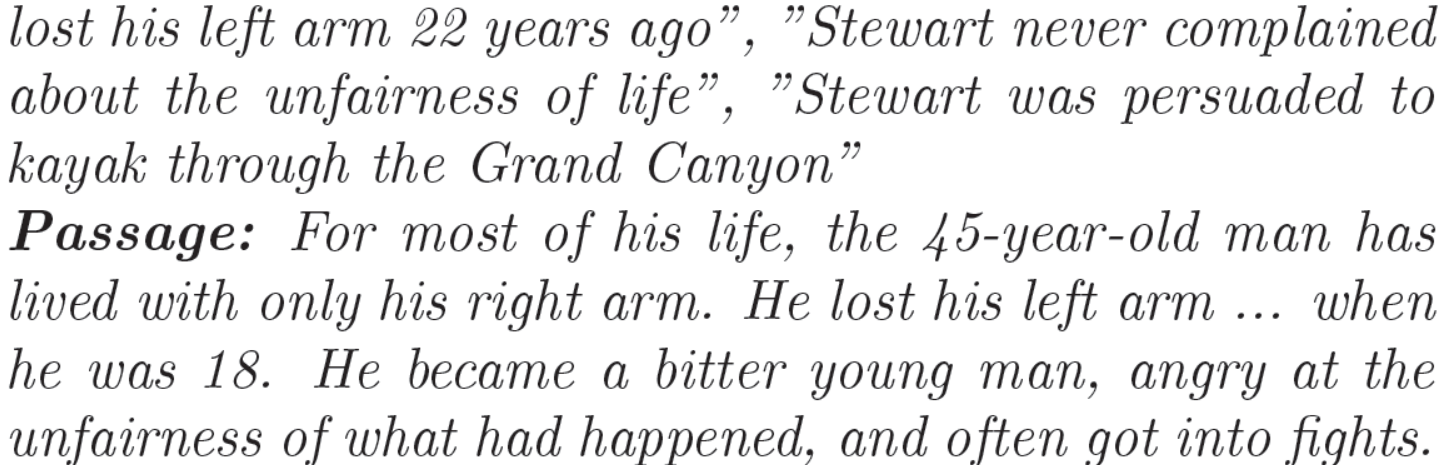


7 Conclusion/Future Work
在Dual Comatch Network的基础上,我们提出了一种新的深度匹配网络,该网络在BERT输出的隐状态之后添加多个匹配注意层。最终,我们在单个模型中获得了66.2%的准确率,在整体模型中获得了67.9%的准确率。因此,在我们测试的四种算法中,集成模型的性能最好。
与目前最先进的69.7%的性能相比,我们落后了一点的原因可能是由于GPU资源的限制,我们不得不冻结几个层,无法以更高的序列长度进行探索。即使是使用多个teslav100gpu的分布式训练也面临着内存分配的问题,因此我们无法进一步探讨,尽管我们发现使用更大的序列长度有助于建立更精确的模型。
我们的模型和数据集太大,每个实验都需要很长时间来训练和测试。在未来,随着时间和GPU内存的增加,探索更深层的DCN和更大的最大序列长度将是一件有趣的事情。我们还想花更多的时间在超参数调优EDA、DCN和集成模型上,并尝试在另一个数据集上先进行训练,以便在RACE数据集上进行迁移学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号