(译)用于多选式阅读理解的协同匹配模型
A Co-Matching Model for Multi-choice Reading Comprehension
Abstract:
多选式阅读理解是一项具有挑战性的任务,它包含了文章和问答对间的匹配。针对这个问题,本文提出了一种新的协同匹配方法,对一篇文章能否同时对问题和答案实现匹配进行了联合建模。在RACE数据集上的实验结果证明我们的方法实现了最优性能。
1.Introduction
使得机器能够理解自然语言文本可以说是自然语言处理任务的终极目标,而机器阅读理解任务则是通向这个最终目标的中间环节。近期,Lai等人发表了一个名为RACE的新的多选式阅读理解数据集,该数据集中的数据来自中国高中和初中的英语考试。表1展示了RACE中一篇文章和两个相关问题的样例。RACE与先前发表的一些机器阅读理解数据集(例如the CNN/Daily Mail dataset (Hermann et al.,2015) and SQuAD (Rajpurkar et al., 2016))的关键区别是RACE数据集中的答案通常无法直接在给定的原文中进行提取,例如表1中展示的两个问题(Q1&Q2)的答案并未在原文中直接出现。因此,回答RACE中的问题有更多的挑战,也需要更多的推理。
先前针对机器阅读理解的方法通常是基于对成对序列的匹配,比如文章与问句和候选答案的联接结果进行匹配,或者是文章与问句做完匹配后,用这个匹配结果再与候选答案进行匹配,以选出最终答案。然而,由于问句和答案是同样重要的,因此上述方法可能并不适合于多选式阅读理解问题。如表1中的第一个问题样例,如果仅将文章与问句进行匹配可能并无意义,并且可能会导致原始文章中的信息丢失。另外,将问句和候选答案联接成一个序列再与文章进行匹配可能也是无效的,这是因为这种方式缺少问句与候选答案间的交互。正如表1中的第二个问题样例,模型为了选择c作为正确答案,可能需要参考问句来识别“he”和“it”所指代的对象。RACE中的这种现象说明我们面对的挑战是三元组(文章、问句和答案)间的匹配而不是二元组间的匹配。

在本文中,我们提出了一个新的模型,该模型针对给定的文章可对问答对进行匹配。我们的协同匹配方法明确地将问题和候选答案视为两个序列,并针对给定的文章,对它们进行联合匹配。具体来说,针对文章中的每个位置,我们都计算两个注意力权重,一个来自问句,一个来自候选答案。随后构造两个匹配表示:第一个用问句表示去匹配文章表示,而另一个用候选答案表示匹配去匹配文章表示。这两个新构造的匹配表示一起形成了协同匹配状态。直观上来说,它对与文章中特定内容相匹配的问句和候选答案的位置信息进行编码。最终,我们对文章中不同位置的协同匹配状态序列应用分层LSTM。信息从词级聚合为句子级,然后从句子级聚合为文档级。通过这种方式,我们的模型可以更好地处理那些证据分散在不同句子中的问题。我们的模型比RACE数据集上的最优模型提高了3个百分点。我们的代码公开在https://github.com/shuohangwang/comatch。
2.Model
多选式阅读理解任务:给定机器一篇文章、一个问题和一系列候选答案,它的目标是在这些候选答案中选出正确答案。我们将文章、问题和候选答案分别表示为P∈Rd*P,Q∈Rd*Q和A∈Rd*A,这里的每一个序列都被表示为一个嵌入向量。d表示嵌入维度,P、Q和A表示上述各个序列的长度。
总的来说,我们的模型如下。对于每个候选答案,我们的模型都会构造一个向量,该向量表示P与Q和A的匹配。所有候选答案的向量用于正确答案的选择。因为我们同时对P与Q和A做匹配,所以我们成这个模型为协同匹配。我们在2.1节介绍词级协同匹配机制,然后再2.2节介绍分层聚合方法,最后再2.3节介绍目标函数。我们协同匹配模型图展示在图1中。
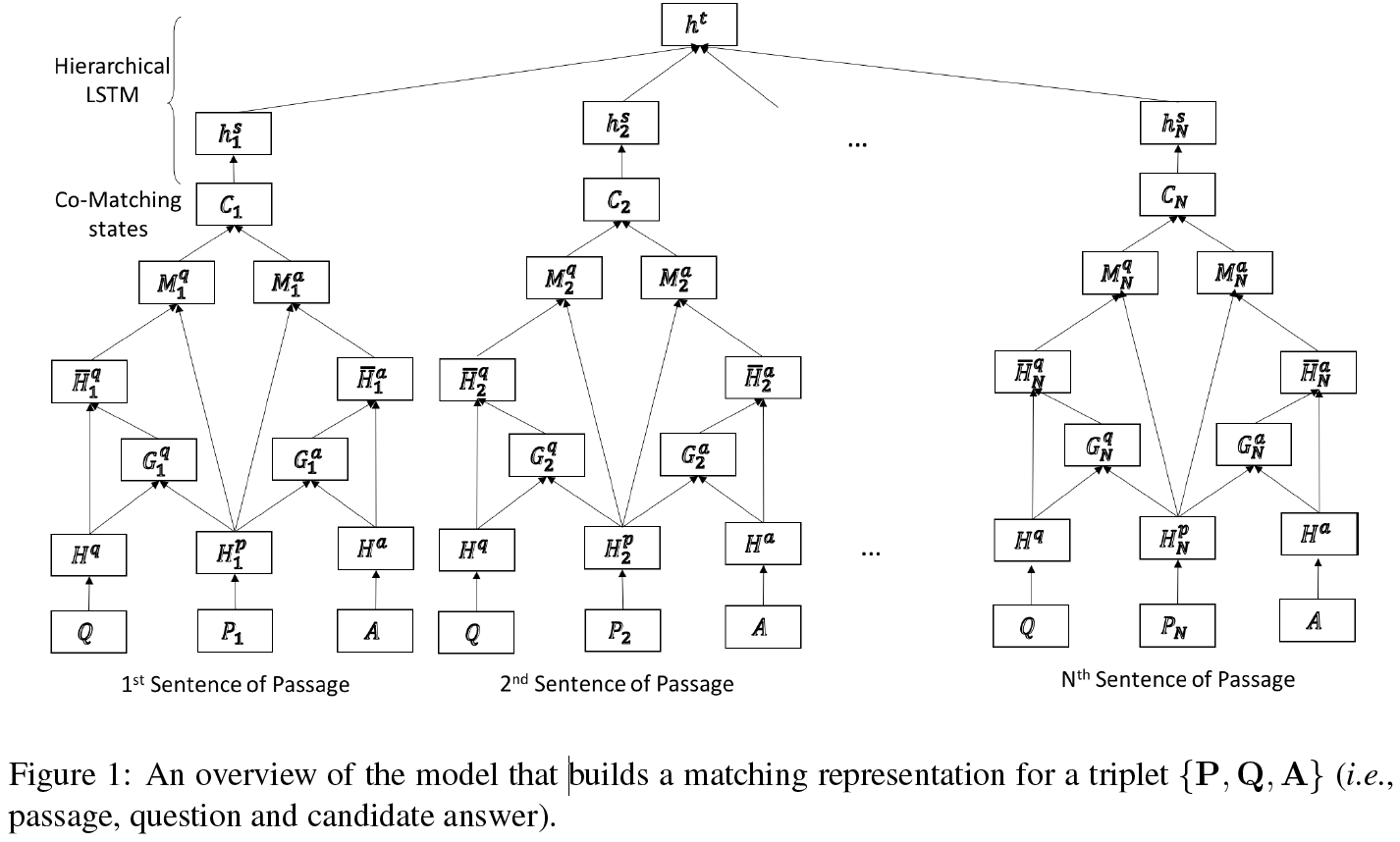
2.1 协同匹配
我们模型中的协同匹配部分致力于在词级上对文章与问题和答案进行匹配。受先前工作的启发,我们先用BiLSTM对这三者进行预处理:
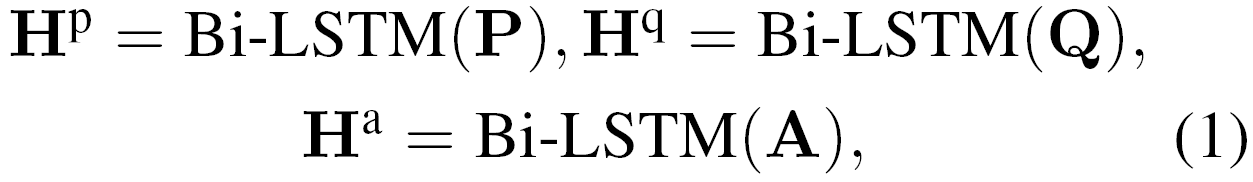
这里的Hp∈Rl*P,Hq∈Rl*Q和Ha∈Rl*A是BiLSTM处理完成后生成的序列表示。我们使用注意力机制将文章中的每个状态与问句和候选答案的聚合表示进行匹配。注意力向量计算如下:
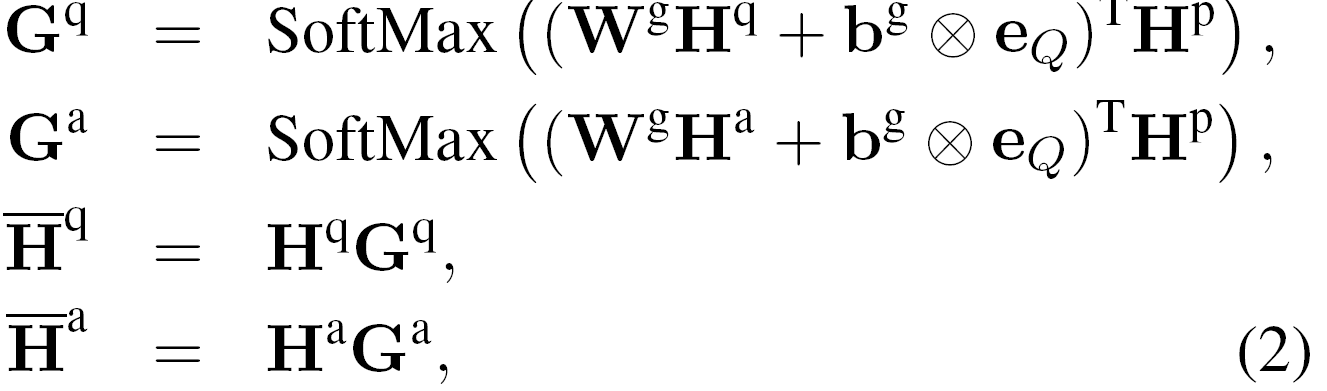
这里的Wg∈Rl*l和bg∈Rl是待学习的参数。eQ是所有1s的向量,它被用于将偏置向量重复到矩阵中。Gq∈RQ*P和Ga∈RA*P是分别分配到问题和候选答案序列中不同隐状态的注意力权重。![]() 是所有问题隐状态的加权和,它表示问题是如何与文章的每个隐状态对齐的。
是所有问题隐状态的加权和,它表示问题是如何与文章的每个隐状态对齐的。![]() 亦是如此。最后我们能协同匹配文章状态与问题和候选答案,公式如下:
亦是如此。最后我们能协同匹配文章状态与问题和候选答案,公式如下:
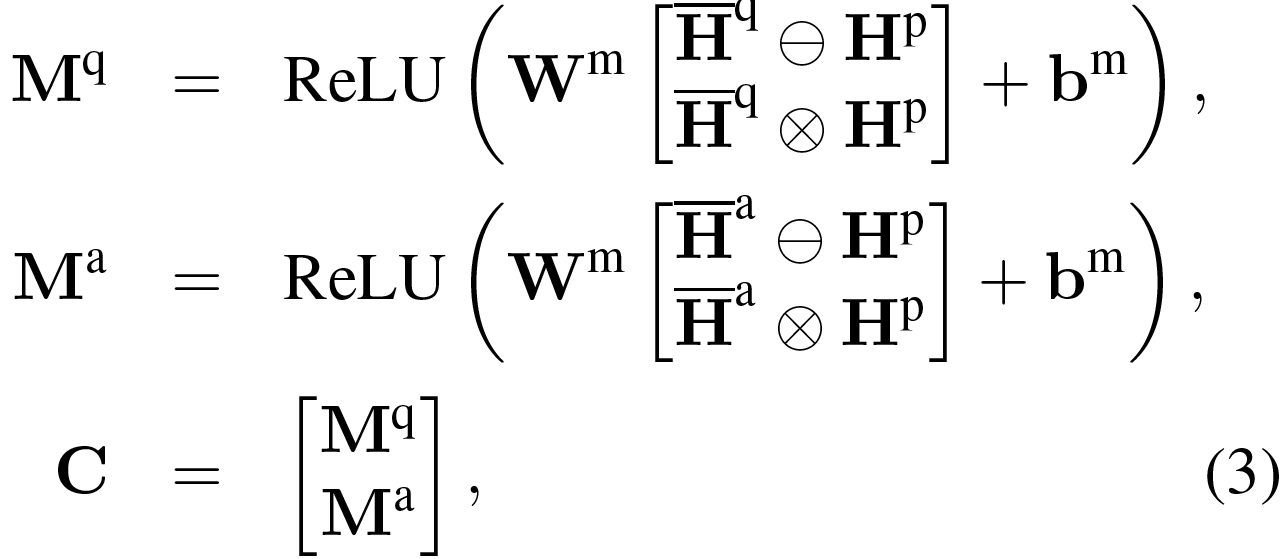
这里的Wg∈Rl*2l和bg∈Rl是待学习的参数。![]() 是按列联接两个矩阵,
是按列联接两个矩阵,![]() 和
和![]() 是对两个矩阵进行按元素相减和按元素相乘,通过这两个操作可获得更好的矩阵表示。Mq∈Rl*P表示文章隐状态和问句中相应的注意力权重的匹配表示。相似地,我们用Ma∈Rl*A表示文章隐状态和候选答案中相应的注意力权重的匹配表示。最后,C∈R2l*P是Mq∈Rl*P和Ma∈Rl*A的联接结果,它表示每一个文章是如何与问句和候选答案进行匹配的。我们将C∈R2l*P(C是单列的)称为协同匹配状态,它将文章状态同时与问句和候选答案进行匹配。
是对两个矩阵进行按元素相减和按元素相乘,通过这两个操作可获得更好的矩阵表示。Mq∈Rl*P表示文章隐状态和问句中相应的注意力权重的匹配表示。相似地,我们用Ma∈Rl*A表示文章隐状态和候选答案中相应的注意力权重的匹配表示。最后,C∈R2l*P是Mq∈Rl*P和Ma∈Rl*A的联接结果,它表示每一个文章是如何与问句和候选答案进行匹配的。我们将C∈R2l*P(C是单列的)称为协同匹配状态,它将文章状态同时与问句和候选答案进行匹配。
2.2 分层聚合
为了捕获文章中的句子结构,我们对上面提到的模型进行了进一步的修改,并在协同匹配状态之后应用了分层LSTM。具体来说,我们先将文章分为若干个句子,并用P1,P2,…,PN(N表示文章中的句子数量)来表示这些句子。对于每个三元组{Pn,Q,A},n∈[1,N],我们都能通过公式1-公式3得到一个对应的协同匹配状态Cn。随后我们对每个协同匹配状态Cn应用BiLSTM进行编码,并通过最大池化操作进行处理,公式如下:
![]()
这里的MaxPooling(.)是指逐行最大池化操作。![]() 是协同匹配状态的句子级聚合。所有这些表示都将通过另一个BiLSTM进行进一步地处理,以得到最终的三元匹配表示:
是协同匹配状态的句子级聚合。所有这些表示都将通过另一个BiLSTM进行进一步地处理,以得到最终的三元匹配表示:
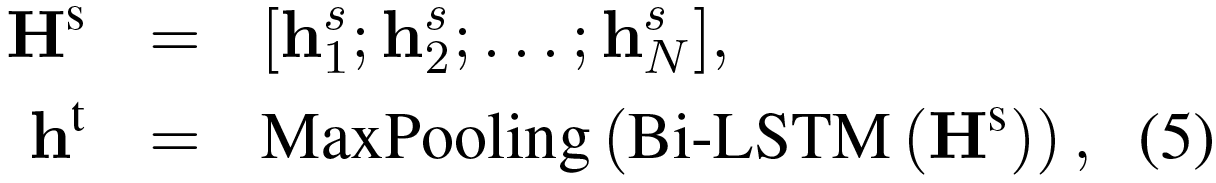
Hs∈Rl*N是所有句子级表示的联接结果,也是最后一个LSTM的输入。ht∈Rl是最终的输出结果,它是文章、问题和候选答案的匹配表示。
2.3 目标函数
对于每个候选答案Ai,我们都能通过公式5得到它与文章和问题的匹配表示hit∈Rl。我们的目标函数如下:
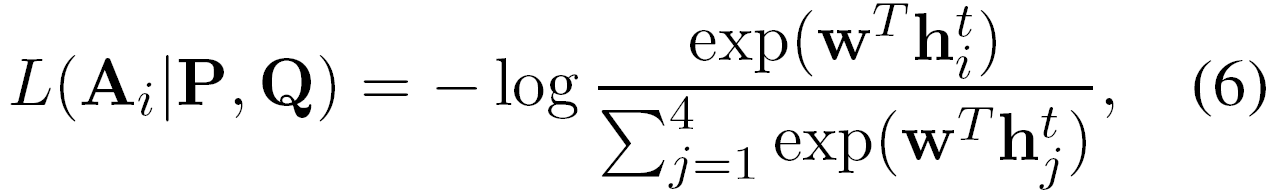
这里的W∈Rl是待学习的参数。
3. 实验
我们使用RACE数据集来验证我们提出的分层协同匹配模型的有效性,该数据集包含两部分:RACE-M来自初中考试题,RACE-H来自高中考试题,RACE表示包含这两部分的完整数据集。
我们将我们的模型与一些基准模型进行了比较,并且也对我们模型的两个消融模型进行了比较。
对比方法:我们将我们的模型与以下模型进行了比较:
Sliding Window:该方法根据问答对和每个特定尺寸窗口的子文章间匹配词的tf-idf值的加和进行匹配。
Stanford Attentive Reader (AR):该方法先用注意力机制生成一个与问题相关的文章表示,随后与每个候选答案进行匹配,给出每个候选答案的可能性。
GA:该方法使用多跳门控注意力机制提取与问句相关的文章信息与候选答案进行匹配。
ElimiNet:该方法先排除最不相关的答案,然后选择最优的答案。
HAF:该方法不仅考虑了三者(文章、问句和答案)间的匹配,而且还对候选答案之间也进行了匹配。
MUSIC:该方法整合了不同的匹配策略并使用多步推理单元进行答案选择。
此外,我们还报道了两个结果作为参考:Turkers是由Amazon Turkers回答RACE测试集中随机抽取的问题的准确率。Ceiling是测试集的子集中有明确的正确答案的问题所占的百分比。
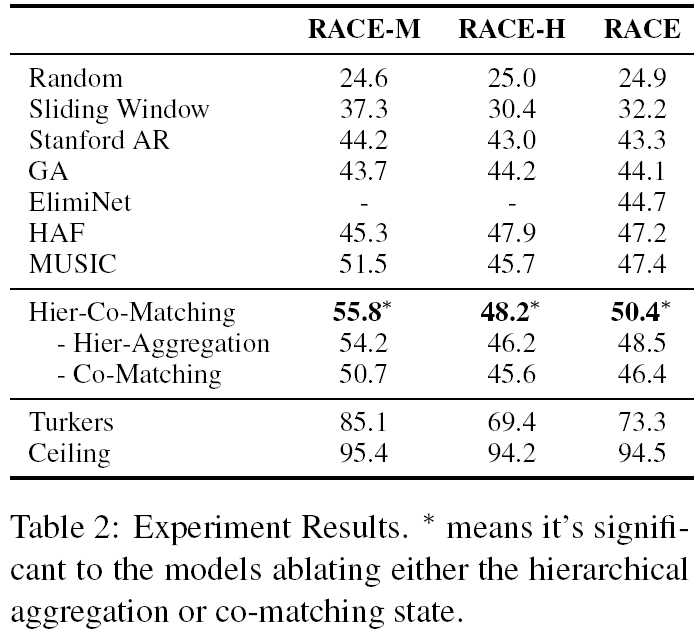
我们模型的性能和上述基准方法均被展示于表2中。从表中可以看出,我们提出的分层协同匹配模型在所有公开结果的基准方法中实现了最优性能。但是,它仍无法与人类的表现相提并论,这说明该研究仍具有很大的提升空间。
消融研究:
另外,针对我们的模型结构,我们还构造了消融研究。在该项研究中,我们对每个组件对最终结果有多少贡献很感兴趣。我们探究了两个关键组件:(1)协同匹配模块,(2)分层聚合方法。我们发现通过单匹配状态(比如只保留公式3中的Ma)替换掉协同匹配状态,并将问句和每个候选答案直接联接会使得最终结果下降4%。我们还发现我们将原有的分层LSTM结构换为将文章视为一个完整的序列,并在两层LSTM(为了保证待训练参数数量是一致的)上运行模型会使得最终结果大约下降2%。
问题类型分析:
我们还探究了我们的模型可以更好地处理哪类问题。我们发现我们的模型对于以“wh”开头的问题具有差不多的表现,比如“why,” “what,” “when” and “where”,在这类问题上,我们模型的性能在50%左右。我们还验证了合理性性问题,像关键词为“true”的问题(例如“Which of the following statements is true”),关键词为否定词“not”的问题(例如“which of the following is not true”),关键词“title”的总结性问题(例如“what is the best title for the passage?”),在这些问题上的性能分别为51%,52%和48%。可以看到我们的模型在RACE中的各类问题上的表现都是差不多的。然而,我们的模型仅基于词级匹配,这可能导致没有推理能力。为了能回答这些总结类问题、推理类问题和原因类问题,我们将会进一步探究该数据集并提高我们的模型。最后,我们进一步对我们模型与基准方法进行了比较,当将问题和每个候选答案进行联接后,我们模型在各类问题上均实现了更好地性能。例如在名词类问题的子集中,我们的模型可以实现49.8%和47.9的准确率。类似的,在关键词为“true”的合理性问题中,我们的模型可以实现51%和47%的更优性能。
4. 总结
在本文中,针对多选式阅读理解任务,我们提出了一个协同匹配模型。该模型包括协同匹配模块和分层聚合组件。我们展示了我们的模型在RACE数据集上已经实现了最优性能。在未来,我们将把协同匹配和分层聚合的思想应用于标准开放域问答中。我们也将进一步探究如何对RACE数据集中的推理和原因类问题进行建模。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号