
query-doc 匹配
2.1.1DRMM
2.2.1Position-Aware Neural IR Model
3.1DC-BERT
3.2polybert
一、语义匹配
1 基于特征表示
特点:学习 query 和 doc ( 放在推荐里就是 user 和 item ) 的 representation 表示,然后通过定义 matching score 函数,是个经典的双塔结构。
整个学习过程可以分为两步:
① 表示层:计算 query 和 doc 各自的 representation,包括DNN、CNN 或者 RNN
② 匹配层:根据上一步得到的 representation,计算 query-doc 的匹配分数,包括两类:
1、直观无需学习的计算,向量点积、cosine 距离;
2、引入了参数学习的网络结构,如 MLP 网络结构(接一个或者多个MLP,最后一层的输出层只有一个节点,那么最后一层的输出值就可以表示匹配分),或者 CNTN 模型(Neural Tensor Network)。
1.1DSSM
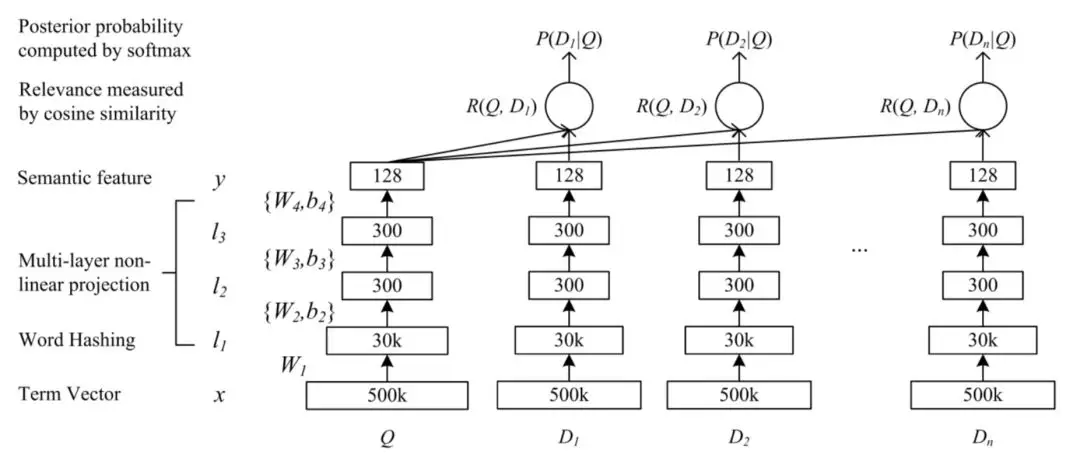
-
word hash:输入层对于英文提出了word hash的方法,大大减少了原始one-hot输入空间,中文最小单位就是单字了
-
表示层:词到句的表示构建,或者说将序列的孤立的词语的 embedding 表示,转换为具有全局信息的一个或多个低维稠密的语义向量
-
匹配层:使用cosine表示query和doc的匹配分数
-
端到端学习:模型是个完全end-2-end的框架,包query和doc的embedding向量直接通过训练得到不需要经过预训练
-
缺点:对query和doc的表示都是bow,丢失了序列信息和上下文信息
原论文:based on<query, doc title >pairs,但也有based on the full text of the documents
1.2CNN_DSSM
特点:无论是 bow 的表示还是 DNN 全连接网络结构的特点,都无法捕捉到原始词序和上下文的信息,因而在表示层用CNN来替代DSSM的DNN层
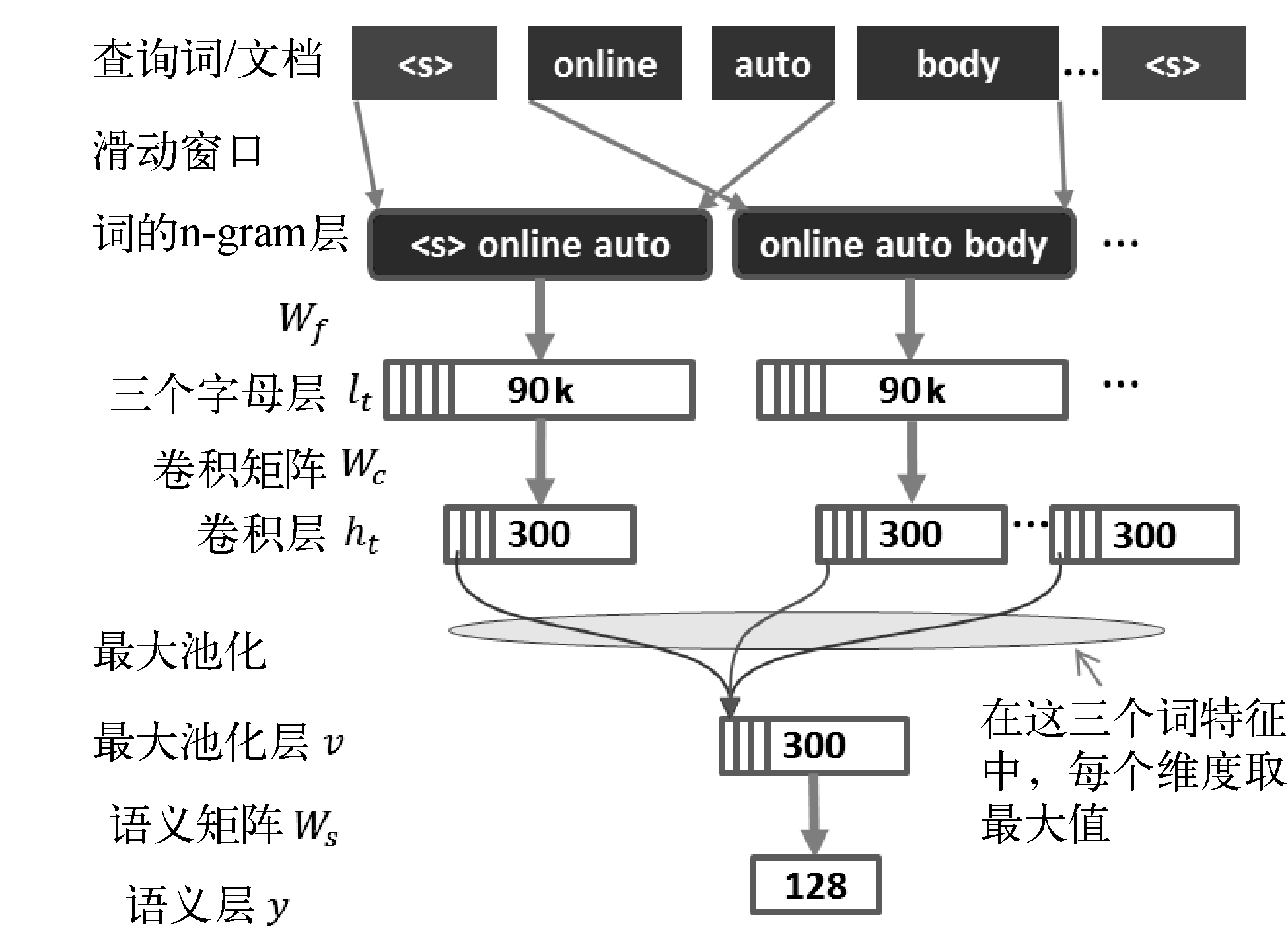
总结下 CNN-DSSM 模型,对比原始 DSSM 模型主要区别如下:
-
输入层除了letter-trigram,增加了word-trigram,提取了词序局部信息
-
表示层的卷积层采用textCNN的方法,通过n=3的卷积滑动窗口捕获query和doc的上下文信息
-
表示层中的池化层通过max-pooling,得到卷积层提取的每个feature map的最大值,从而一定程度的捕获了全局上下文信息
卷积的时候,就类似抓取trigram信息,这个过程是保持局部的词序信息的(局部统筹)。但是max-pooling的时候,又把次序信息丢失了,max-pooling类似一个全局统筹的操作,抓取最强的语义信息。也可以用其它的pooling操作,可以部分的保留次序信息,这里先不展开。另外,pooling还有一个作用,可以将变长的东西,变成定长的,因为神经网络的神经元数目需要预先设定好,所以这个pooling的操作特别巧妙。但是max-pooling有个缺点是,例如query是ABCD,很有可能query是ABCDEFG的时候,max-pooling的结果不变,这个特性和很多匹配任务的场景是不一致的。
1.3LSTM-DSSM
总结 LSTM-RNN 模型的几个特点:
-
相比于DSSM模型引入了LSTM网络结构来捕捉次序的关系
-
LSTM最后一个隐层的输出作为query和doc的representation
https://ai.51cto.com/art/201909/603290.htm LSTM-DSSM文本匹配模型在苏宁商品语义召回上的应用
1.1.4bert
双塔的方式, 把预训练好的Bert当成一个编码器,把query输进去得到query的向量,把doc输进去得到doc的向量,然后接一个简单的match func(cosine 或者MLP)。
1.2.基于交互
特点:这种方法是不直接学习query和doc的语义表示向量,而是在底层,就让query和doc提前交互,建立一些基础的匹配信号,例如term和term层面的匹配,再想办法把这些基础的匹配信号融合成一个匹配分。更强调待匹配两端更充分的交互,以及交互基础上的匹配。所以不会在表示层将文本转换成唯一的一个整体表示向量,而一般会保留和词位置相对应的一组表示向量。一般来说效果更好一些,但计算成本会增加非常多,适合一些效果精度要求高但对计算性能要求不高的应用场景
1.2.1ARC-ii
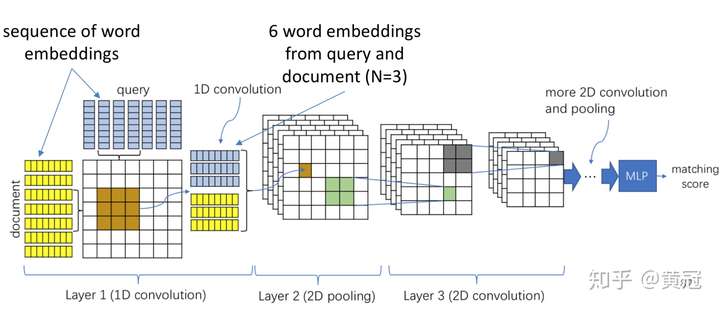
-
让两个句子在得到它们各自的句子向量表示之前,提前交互,使用1D conv:
-
-
例如窗口大小为N=3,那么每次从两个句子中分别取1个trigram,然后把两个trigram的向量concat起来,然后使用一个卷积核进行卷积得到一个值
-
那么每两个trigram进行卷积,就会得到一个矩阵,这个矩阵是两个句子的基础的匹配信号,这个矩阵类似图像,是个2维的向量。
-
使用多个卷积核,就会得到多个矩阵,即tensor
-
-
得到多个有关两个句子的基础匹配信号的矩阵后,就可以像处理图像一样,处理每一个矩阵。常见的操作就是使用2D的卷积核。不断的卷积,就会得到一个定长的向量,然后再接MLP,最后一层的输出节点数目只有1,就得到了它们的匹配分。
优点是,有基础的匹配信号矩阵,可解释性强,而且卷积操作是保留次序信息的
缺点是,基于trigram的匹配,没有unigram的匹配信号,不过这个稍微改一下就可以了;
另外没有特别区分精确匹配(sim=1.0)和普通匹配信号(sim<1.0)
1.2.2MatchPyramid

-
-
和上文类似,只是这里不是trigram的基础匹配信号,而是使用unigram的匹配信号,即word-level的匹配信号,每两个词的向量算cosine即得到两个词的相似度。那么两个句子中每两个词都计算一遍相似度,就可以得到一个匹配矩阵,然后就可以像处理图像一样处理这个矩阵(用2D-CNN来提取匹配模式,或者更大片段的匹配信号):
-
1.2.3Match-SRNN
1.2.4bert
把query和title拼接,输进去Bert,类似Bert里的NSP任务那样,然后由最后一层的表示做pooling,或者由cls的表示,然后接MLP得到匹配分
用Bert来做匹配的好处是:
a.基于字粒度,减少OOV(未登录词)的影响,减轻分词错误的风险,增强泛化能力。
b.使用positional embedding建模顺序信号。
c.深层transformer结构,有足够强的交互和建模能力。
d.使用海量无监督数据预训练,在有监督样本少的任务场景就是神一般的存在。
缺点是:
a.模型结构复杂,预测性能是瓶颈。
b.训练耗GPU。
c.在有监督的训练数据本来就有海量的时候,预训练的方式优势不明显
总结一下:
-
Representation based:
-
-
重点是学习文本的句子表示;可以提前把文本的语义向量计算好,在线预测时,不用实时计算。
-
在学习出句子向量之前,两者没有任何交互,细粒度的匹配信号丢失。学习出来的向量可能是两个不同向量空间的东西,通过上层的融合层和loss,强制性的拉近两个向量。
-
-
interaction based:
-
-
有细粒度、精细化的匹配信号,上层进行更大粒度的匹配模式的提取;可解释性好
-
在线计算代价大。
-
1.3改进方向
为了更好实现语义匹配、逻辑推理,需要 model 深度信息,可以从如下角度改进上述基础 SE、SI 网络:
-
结合 SE 与 SI 网络:两者的作用并非谁是谁子集的关系,是相互补充的关系,简单加权组合即可。
-
考虑词语的多粒度语义信息:即在基础模型基础上分别对 unigram、bigram、trigram 进行建模,从而 model 文本的word、term、phrase 层面的语义信息,融合的方式不唯一,在输入层、表示层、匹配层都可以尝试,通常来说越早融合越好提升效果,因为更早发挥了多粒度间的互补性。可参考腾讯的 MIX,百度的SImnet
-
引入词语的多层次结构信息:即引入 term weight、pos、word position、NER 等层面的 element-wise 信息到语义信息中。可参考腾讯的 MIX。
-
引入高频 bigram 和 collocation 片段:比基本切词更大的短语片段粒度会不会进一步提升效果?理论上越大的文本片段,表义越精确,但也越稀疏。词语粒度下的词表已可达百万量级,再增加更大片段压力太大,而且还会面临训练不充分问题。我们设计了一种巧妙的统计量度量方式,基于大数据只挑选少量对匹配任务有很好信息量的高频共现 Term 组合,作为 Bigram 词加入字典,进一步显著提升了模型效果。举个例子,我们输入语料「汽车蓝牙自动连接」,利用基本分词工具,可以把序列分割为「汽车 蓝牙 自动 连接」四个 Term。此时,我们依据大数据下的统计分析,可以发现「汽车-蓝牙」的统计量得分最高,「自动-连接」次之,「蓝牙-自动」最小,那么依照设定的统计量阈值,我们就得到了基于 Bigram 粒度的输出。
以上方式比较适合于连续 Term 共现组合,而对文本语义来讲,有时候一些跨词的 Collocation 搭配也非常重要。我们使用依存句法分析工具来获得相应的 Collocation 片段。还是上面的例子,输入语料「汽车蓝牙自动连接」。此时,我们对输入语料构建依存分析树,统计父节点和子节点共现频率,最终认为「蓝牙-连接」显得比「自动-连接」重要,因此最终输出就成了「汽车-蓝牙 蓝牙-连接」。
-
参考 CTR 中 FM,处理业务特征:如美团的排序算法演进中,参考了 CTR 中的 wide&deep 模型来添加业务特征,即,有的业务特征不做变换直接连接到最外层,有的业务特征做非线性变化后不够充分,会再进行多项式非线性变换。
-
对两文本中的差异部分单独建模:即在基础模型基础上,再使用一个单独模型处理两文本差异部分,强化负样本的识别能力。可参考 HIT 的 GSD模型。
-
引入混合学习策略:如迁移学习,可参考 MT-hCNN;如多任务学习;以及两者多种方式的组合,具体比较可参考 HIT 的 DFAN,如引入多任务学习和基于 Seq2Seq 的迁移学习的混合策略效果可能最好。
-
在实际应用中,除了模型算法之外,还有很多因素会对最终效果产生很大的影响。其中最重要的就是数据,还有就是应用场景的特点。
对深度学习模型来讲,数据的规模是非常关键的。在网页搜索应用上的成功,有个很重要的因素就是有海量的用户点击数据。但是光有数量还不够,还要看数据如何筛选,正例负例如何设定,特别是负例如何选择的问题。例如在网页搜索应用中,如果不考虑频次问题,可能训练数据的绝大部分构成都是高频 Query 数据,但高频 Query 的搜索效果一般是比较好的了。另外,有的 Query 有点击的网页很多,有的很少,能组成的正负 pair 数差别会很大,这时候如何处理?而对于负例,数量和质量上还应该考虑哪些因素?这些问题都至关重要,不同的数据设计方式会极大地影响最后效果。
应用场景同样很重要。比如最终匹配度得分就是最终的结果,还是作为下一层模型的特征输入?如果作为下一层输入的话,对得分的可比性有没有要求?最终的任务是分类还是排序,是排序的话排序的优化目标和训练中的优化目标如何可以做的更一致?这其中有一些会影响到对数据的组织方式,有一些需要针对性的对一些模型超参数做调整。例如前文 loss 中 margin 的具体设定,会影响到准确率指标和得分区分性之间的一些折中变化。
1.4传统语义匹配模型
3.1tf-idf
3.2bm25
-
BM25 方法核心思想是,对于 query 中每个 term,计算与当前文档 doc 的相关性得分,然后对 query 中所有 term 和 doc 的相关得分进行加权求和,可以得到最终的 BM25
-
对于 query 的表示采用的是布尔模型表达,也就是 term 出现为 1,否则为 0;
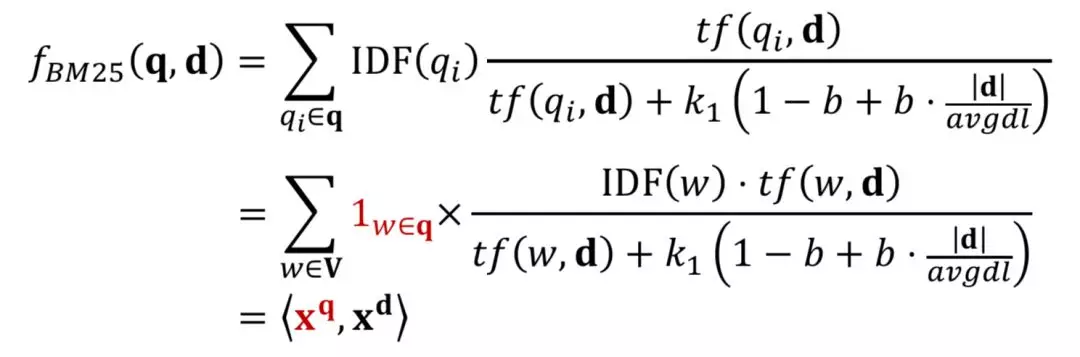
图 BM25 公式为 query 中所有 term 的加权求和表达,可以分为两部分,第一部分是每个 term qi的权重,用 IDF 表示,也就是一个 term 在所有 doc 中出现次数越多,说明该 qi对文档的区分度越低,权重越低。
公式中第二部分计算的是当前 term qi与 doc d 的相关得分,分子表示的是 qi在 doc 中出现的频率;分母中 dl 为文档长度,avgdl 表示所有文档的平均长度,|d|为当前文档长度,k1和 b 为超参数。直观理解,如果当前文档长度|d|比平均文档长度 avgdl 大,包含当前 query 中的 term qi概率也越高,对结果的贡献也应该越小。
3.3隐式模型:一般是将query、title都映射到同一个空间的向量,然后用向量的距离或者相似度作为匹配分,例如使用主题模型
3.4通过将 doc 映射到 query 的空间的,然后在 query 的空间进行匹配。这种方法和机器翻译中,将源语言映射到目标语言的做法是一致的,因此又称为基于 translation 的方法。
-
词义局限:字面匹配无法处理同义词和多义词问题,如在美团业务场景下“宾馆”和“旅店”虽然字面上不匹配,但都是搜索“住宿服务”的同义词;而“COCO”是多义词,在不同业务场景下表示的语义不同,可能是奶茶店,也可能是理发店。
-
结构局限:“蛋糕奶油”和“奶油蛋糕”虽词汇完全重合,但表达的语义完全不同。 当用户搜“蛋糕奶油”时,其意图往往是找“奶油”,而搜“奶油蛋糕”的需求基本上都是“蛋糕”。
1.5 Representation & Interaction Based Model(可尝试)
Learning to Match Using Local and Distributed Representations of Text for Web Search
-
二、相关性匹配
相似度!=相关性,区别是:
-
相似性:
-
-
判断两个句子语义、意思是否相似
-
一般是同质的两段文本,例如两个句子、两个文章(长度接近,属性类似)
-
在两段文本的不同位置进行匹配
-
匹配函数是对称的,因为是同质的文本进行匹配
-
代表性任务:同义句子识别
-
-
相关性:
-
-
判断文档和搜索query是否相关
-
不同质的两段文本,例如一个是query,一个是网页,长度不一样
-
在网页的不同部分进行匹配,例如title、锚文本(链接对应的文本)、正文
-
匹配函数不是对称的,因为不是同质的文本进行匹配
-
代表性任务:query-网页检索 .例如query和网页,网页只有有部分内容和query很相关,而其它部分和query不相关,可能就满足搜索的相关性匹配的要求。
-
Query-Document Relevance Matching的方法也主要分为两大类:
-
-
基于全局的匹配信号
-
基于局部的term级别的匹配信号
-
2.1基于全局的匹配信号
这种方法的基本步骤:
假设query=<q1,q2,q3>,doc=<d1,d2,d3...,dn>
1.对于query中的每个term:
a.计算它在doc中的匹配信号
b.计算整体的匹配强度的分布(q1与doc匹配度)
2.累计匹配强度的分布(对query中所有q进行累计)
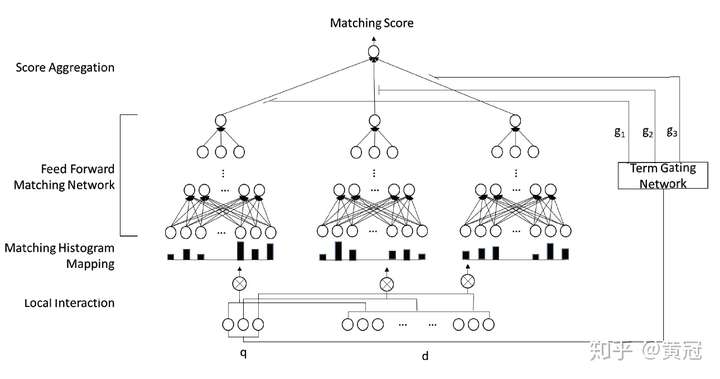
2.1.1Deep Relevance Matching Model
对于query中的每个term:
-
将它和文档的所有单词的匹配分,离散化分桶。特别的是,为精确匹配单独划分一个桶。统计在每个桶上的次数,即得到一个关于这个term和文档匹配分的一个直方图,即一个向量。
-
得到上述向量后,使用全连接层学习匹配分。注意,不同的单词 ,这些全连接层的参数是共享的。
-
将上述的匹配分加权求和,这里的权重论文中也介绍了两者方法,其中一种是使用简单的IDF。
-
Matching Histogram Mapping
传统基于交互的模型用一个匹配矩阵来表征query term和doc term的局部交互性,这个匹配矩阵保留了query和doc中词条的顺序,这对于位置敏感的任务是很有用的。但是根据多样匹配性的要求,相关性匹配并不关心位置信息,因为与query相关的内容能出现在一个长文档的任一位置。这篇文章采用了匹配直方图,因为词条之间相关性在【-1,1】之间,划分为以下五个子区间{[−1,−0.5), [−0.5,−0), [0, 0.5), [0.5, 1), [1, 1]},[1,1]单独划分一个区间来表示精准匹配,再统计落在每个字区间的个数,最终得到的形式是 [0, 1, 3, 1, 1]这样一个向量表示。
[注意]query term和doc term 的向量表示是通过WORD2VEC 训练得到的,向量训练好在模型中 冻结掉,不参与训练。
model training:由于是个排序问题,pairwise ranking loss such as hinge loss to train our deep relevance matching model.
此篇论文含 调参说明和ablation study
Impact of Term Embeddings:实验了50,100,300,500维度,结果先上升后下降。
对于低维的词向量不足以表达起 相似性匹配,但过高维度又需要更多数据来支撑
impact of Matching Histogram:为了将不定长的局部交互表征变成定长的表示,用dynamic pooling, k-max pooling来代替
impact of term gating network
这个模型的优点是:
-
-
区分精确匹配和普通的相似度匹配信号
-
使用直方图,不用像卷积那样子使用padding
-
相比原始的匹配信号,直方分布图更鲁棒
-
缺点是:
-
失去了位置信息。但这篇论文要解决的是Ad-hoc Retrieval的问题,位置信息相对没那么重要。
2.2基于局部的term级别的匹配信号
based on Global Distribution of Matching Strengths的方法是,对于query中的每个term,直接求解它和整个文档的匹配信号。而based onLocal Context of Matched Terms的方法是,对于query中的每个term:
-
-
找出它要匹配的doc的局部上下文
-
匹配query和doc的局部上下文
-
累计每一个term的匹配信号
-
这种方法的好处是:
-
-
鲁棒性强,可以过滤掉doc和query无关的部分
-
在doc的局部上下文,可以很好的考虑顺序信息
-
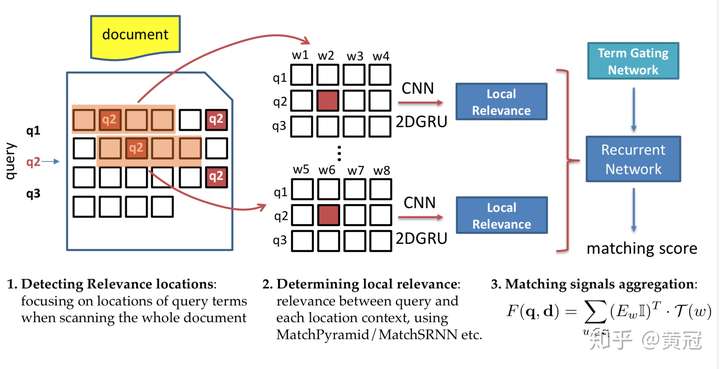
2.2.1DeepRank
-
-
对于query中的每个term,找出它在doc中出现的位置。
-
例如query的第二个term:q2,它在doc中三个地方出现,对于这三个位置,分别取出2k+1个词(前后各取k个),不妨假设取出来的三个句子是s1、s2、s3,然后可以用match-matrix等各种方法算出query和s1、s2、s3匹配信号,然后用rnn融合这三个匹配信号,得到一个匹配分
-
将每个term的匹配分加权求和得到最后的匹配分
-

三、最近新出
3.1DC-BERT
由于每一个问题都需要与 retrieve 模块检索出的每一个文档进行拼接,这需要对大量检索文档进行重编码,非常耗时。为了解决效率问题,DC-BERT 提出具有双重 BERT 模型的解耦上下文编码框架:在线的 BERT 只对问题进行一次编码,而离线的 BERT 对所有文档进行预编码并缓存它们的编码。DC-BERT 在文档检索上实现了 10 倍的加速,同时与最先进的开放域 QA 方法相比,保留了大部分(约98%)的 QA 问答性能。
如上图所示,DC-BERT 自底向上分为如下三个部分:
Dual-BERT component
DC-BERT 框架包含两个 BERT 模型,分别对问题和每个检索得到的文档进行编码。
-
在训练期间,算法将更新两个 BERT 模型的参数以优化学习目标;
-
训练模型后,我们会对所有文档进行预编码,并将其编码存储在离线缓存中;
-
在测试期间,我们只使用在线 BERT 模型对问题进行一次编码,并从缓存中读出由 retrieve 模块检索得到的所有候选文档的缓存编码。
这样做的优点在于 DC-BERT 只对 Query 进行一次编码,从而降低了底层 BERT 的编码计算成本
Transformer component
通过 Dual-BERT component模块,获取到问题的编码 和文档编码 ,其中 是词嵌入的维数, 和 分别是问题和文档的长度。由于 rerank 是预测文档与问题的相关性,因此引入了一个带有训练 global embeddings 的Transformer 组件来使问题和文档进行交互。
具体来讲,全局 position embeddings 和 type embeddings 被加入到问题和文档的顶层编码中,用预训练 BERT 的 position embeddings 和 type embeddings 进行初始化,之后送入 Transformer 层进行深度交互,并在训练过程中进行更新。
3.2Poly-encoders
query 和 candidate 拼成一句话,使得模型可以对 query 和 doc 进行深度交互,充分发挥 BERT 的 next sentence 任务的作用。本篇论文实现的交互式匹配(Cross-encoder)也是基于这种架构。交互式匹配的核心思想是则是 query 和 candidates 时时刻刻都应相互感知,信息相互交融,从而更深刻地感受到相互之间是否足够匹配。相较于 Siamese Network (Bi-encoder),这类交互式匹配方案可以在Q(Query)和D(Doc)之间实现更细粒度的匹配,所以通常可以取得更好的匹配效果。但是很显然,这类方案无法离线计算candidates 的表征向量,每处理一个 query 都只能遍历所有(query, candidate) 的 pairs 依次计算相关性,这种时间和计算开销在工业界是不被允许的。
模型结构
本文是对速度快但质量不足的 Bi-encoder 架构和质量高但速度慢的 Cross-encoder 架构的一种折中,其基本结构如下图:
每个 query 产生 m 个不同的 注意力机制 ,对每一个query产生不同的 attention模块,以此获取 query 中一词多义或切词带来的不同语义信息;接着再根据 动态地将 m 个 注意力矩阵 集成为最终的
https://www.infoq.cn/article/ndedp7vgpmyuys0jemj7 搜索中的深度匹配模型
