
读论文啦!Context-Aware Sentence/Passage Term Importance Estimation For First Stage Retrieval
在query-doc任务中,一般在召回层返回给我们一些文档(数量级在百),我们需要再对其进行排序返回跟query最相关的doc(数量级在十),第一阶段的召回传统做法是基于布尔查询的,当一个query中有多个term时,每个词对于文档的召回的贡献度是不一样的,我们不能一视同仁地看待这些term,常用做法是基于统计得到的词频,逆文档频率。但基于频率得到的term 权重并不一定对应term在这段话中的重要性,
比如我们搜索“stomach”,以下两个片段中stomach的词频都是2,但第二个片段完全不符合我们的搜索要求,它只是包含了这个词但却是离题的。这篇文章做的就是 用Bert生成依据上下文变化而变化的表征,因此同一term的重要性会随着不同上下文语境而变化。

1. Contextualized word embedding generation:生成上下文敏感的向量,这部分没啥好说的~如果不太理解,回去看下Bert模型哦
2.用一个线性回归函数来将基于上下文的向量转化为term weight,损失函数为MSE,

真实label下面介绍哈
Bert模块用训练好的Bert模型初始化,最后一层的回归层的参数从头学起。
我们可以用这篇文章提出的DeepCT 做以下两件事:
1、对片段或者片段长短的文档进行词权重计算、通过倒排进行存储每个term对应的权重
在这个任务中,要对片段中的term 进行权重学习,回归层的真实label采用的是query term recall,
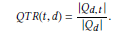
怎么理解这个指标呢?假设我们面前摆了一段话,你对这段话进行提问,在提问中出现的越多,也就证明这个词在这段话的重要性越高。
前面线性转换层输出是每个term对应的weight,数值在【0,1】,乘上一个系数进行放大,

2、对query中的每个term 赋予权重
对于含有很多term,很长的query,如果我们用传统的TF,每个词的tf会很接近拉不开差距,
当线上接收到一个query时,比如“apple pie",我们会用已经估计好的term weight来生成bag -of -word query , 会得到
weight(0.8 apple 0.7 pie),bow未考虑到单词之间的次序,引入次序信息的话和term之间的共线性,就是Sequential dependency model。
