
读论文啦!相关性匹配经典论文A Deep Relevance Matching Model for Ad-hoc Retrieval
我们知道:语义匹配可分为两大类,基于表示的和基于交互的。
基于表示的:学习 query 和 doc ( 放在推荐里就是 user 和 item ) 的 representation 表示,然后通过定义 matching score 函数。
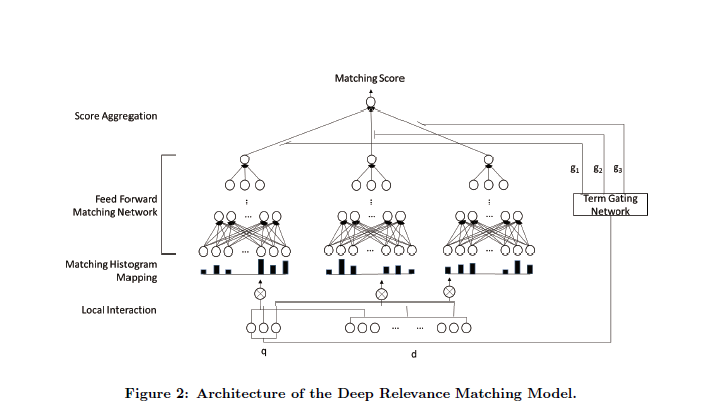
一、首先建立起query和doc的局部交互,不同于传统基于交互的模型用一个匹配矩阵来表征query term和doc term的局部交互性步骤如下:
对于query中的每个term: - 将它和文档的所有单词的匹配分,离散化分桶,统计在每个桶上的次数,即得到一个关于这个和文档匹配分的一个直方图,即一个向量。 - 得到上述向量后,使用全连接层学习匹配分。注意,不同的单词 ,这些全连接层的参数是共享的。 - 将上述的匹配分加权求和,这里的权重论文中也介绍了两者方法,其中一种是使用简单的IDF。 ,
二、Matching Histogram Mapping
上一步的输出是query和doc的局部交互性,但聪明的你肯定会想到:query和doc长度都是不定的呀!!之前基于交互的模型这个匹配矩阵保留了query和doc中词条的顺序,这对于位置敏感的任务是很有用的。但是根据多样匹配性的要求,相关性匹配并不关心位置信息,因为与query相关的内容能出现在一个长文档的任一位置。这篇文章采用了匹配直方图,因为词条之间相关性在【-1,1】之间,划分为以下五个子区间{[−1,−0.5), [−0.5,−0), [0, 0.5), [0.5, 1), [1, 1]},[1,1]表示精准匹配,再统计落在每个字区间的个数,最终得到的形式是 类似[0, 1, 3, 1, 1]这样一个向量表示。
此篇论文介绍了三种Matching Histogram Mapping方法:基于计数的;基于归一化的;基于log-COUNT的(对计数值取log。)
三、Feed forwardMatching Network
四、Term Gating Network
之前基于交互的模型在matching 矩阵上进行CNN的系列操作,这会保留了词之间的顺序信息,这对于语义匹配任务来说是重要的,因为词之间的顺序很影响整个句子的语义。虽然也有些模型利用一些pooling策略将位置敏感的交互转换成词强度的交互,MV-LSTM应用K-max pooling从matching矩阵中选取强度前K大的信号作为MLP的输入,但会带来这么有一个毛病:使得模型倾向于长文本,因为长文本含与query相关的词的可能性更大。
这篇论文Term Gating Network来建模query中term的重要性,
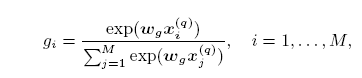
xi 就是query中第i个词的输入,有以下两种输入
词向量:query中第i个词对应的向量;
IDF:query中第i个词对应的逆文档频率。
gi:query中第i个词贡献了多少相关度
五、模型训练
很经典的pairwise ranking 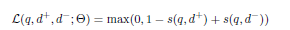
- 使用直方图,不用像卷积那样子使用padding
- 相比原始的匹配信号,直方分布图更鲁棒
