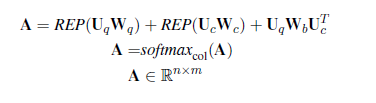读论文啦!Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
小萌新最近实习碰到的第一个项目就是 搜索引擎,最近无论从模型还是从工程角度都苦读了很多知识,准备整理出来 帮助自己更好地理解。
一、Relevance Matching VS Semantic Matching
首先,这两个不是等价的哦!
1、Semantic Matching主要是强调语义上的匹配,包括词之间、短语之间、和句子之间的相似性。而Relevance Matching关注的是相关性匹配,更关注词语字面上的匹配。举个栗子,“今天温度好低”和“今天好冷呀”用不同的表达传达了相似的意义,而这两个句子不含相同的词条。
2、Semantic Matching 涵盖以下子任务:复述识别,问题回答
Relevance Matching 主要用在搜索引擎里,query-doc匹配
3、Relevance Matching里的query-doc数据差异很多,query通常比较短、doc比较长,且数据是异质的,那Siamese这样的对称结构 就不适合用在query-doc的matching上。
Relevance Matching 有以下重要特性:
注重term完全匹配,term层面的匹配的重要性 是不比语义匹配带来的重要性低这也是在传统的召回模型中,用BM25效果也还行。
二、模型框架
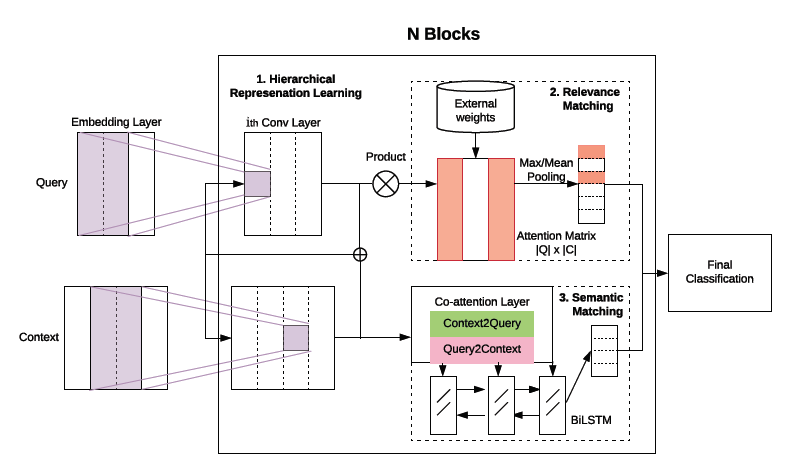
1表示层ENCODER
表示层的输入是 已经embedding过后的query表示和doc表示。为了学习单短语层面的表示,对于query有两种操作,
第一个是叠加多层CNN层来变深,第二个是横向叠加不同窗口尺寸的CNN层。不同于对query 用CNN模块来捕捉k-gram之间的语义,采用多层BiLSTM来编码doc。
2相关性匹配层
将上一层query和doc表示成Uq ,Uc, 将两矩阵相乘得到二者的相似性表示,再利用softmax得到在数值在0-1之间的相似性矩阵。注意,此时query 中的某个term和doc完全匹配的话,则分值会很高,接下来用POOL层来提取最显著的特征。mean pooling 是用来应对 query中的某个词与doc中多处匹配的情况。
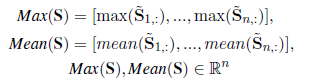
经过pooling后的数值就可视为 query中的短语和doc的revelance matching signal。
我们前面提到:query中每个term的重要性不该是毫无差别的,这篇文章用的是最简单粗暴的IDF来表示term weight,IDF越小,说明该词重要性越高。其实关于 term weight 也有好多方法,小萌新争取也整理出来!
3语义匹配层
在每个编码层应用共同注意机制 Co-Attention,实现多语义层的上下文感知表示学习。
使用了Co-Attention来计算查询向量和文本向量之间的注意力分数,将其作为语义匹配得分