


bilstm+crf pytorch 代码 保姆式吐血整理
Pytorch里的LSTM单元接受的输入都必须是3维的张量(Tensors). 值得注意的点 第一维体现的每个句子的长度,因为是喂给网络模型,一般都设定为确定的长度,也就是我们喂给LSTM神经元的每个句子的长度,当然,如果是其他的带有带有序列形式的数据,则表示一个明确分割单位长度,
第二维度体现的是batch_size,也就是一次性喂给网络多少条句子
第三位体现的是输入的元素(elements of input),也就是,每个具体的单词用多少维向量来表示
话不多说,开始啰
在词性预测任务中,为简化问题,假设标签只有名词(N)、动词(V)、形容词(ADG)
将输入句子中的字/词转换为对应的索引,把标签转换为对应的索引

初始化
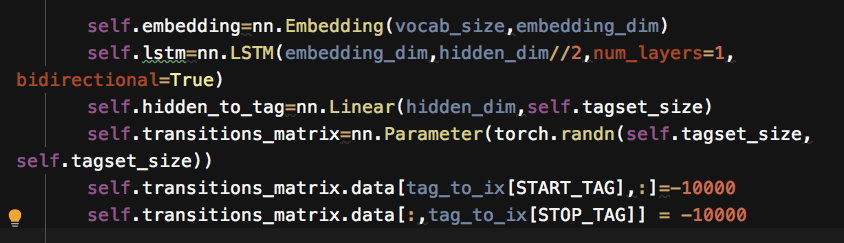
hidden_to_tag :通过一个线性连接层将bilstm隐状态维度从hiddem_dim 转变为标签集合长度
torch.nn.Parameter():,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面,使用这个函数的目的也是想让状态转移矩阵在学习的过程中不断的修改其值以达到最优化
建立转移矩阵,我们希望:1其他tag无法转向start。2不会从stop开始转向其他tag。所以这些位置设为-10000.
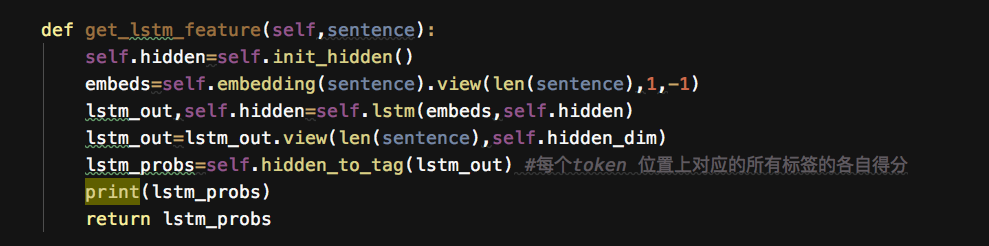
BILSTM层
BILSTM层输出为每个词的所有标签的各自得分,注意bilstm 层输出的标签是独立的,缺少相互之间的约束性,这也正是为啥要往上加CRF层get_lstm_feature输出正是每个token的对应各个标签的得分,作为CRF层中的非归一化的发射概率。
经过了embedding,lstm,linear层, 输出为发射矩阵
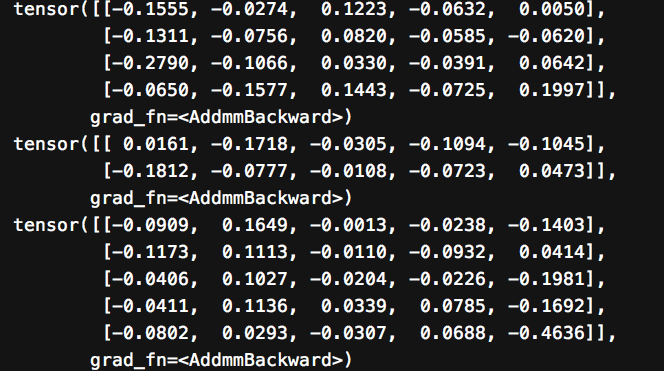
输出如下,以 "girls are beautiful angles"为例,这句话有4个token,标签集合长度为5(加上START_TAG、STOP_TAG),输出向量shape 为一句话长度*标签集合长度
girls 对应的标签N V ADJ START STOP 得分分别是 -0.1555, -0.0274, 0.1223, -0.0632, 0.0050
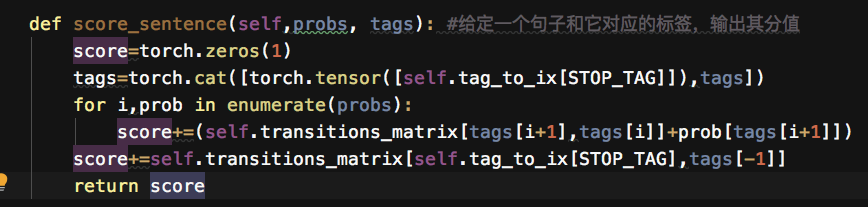
2 CRF层
CRF 损失函数=所有路径总分-真实路径得分(理论部分就不一一展开洛,可参考)
真实路径得分对应的函数如下所示:
Score(x,y)=∑logψEMIT(yi→xi)+logψTRANS(yi-1→yi)
所有路径总分对应的函数如下所示,使用了前向算法来迭代计算所有路径得分之和。
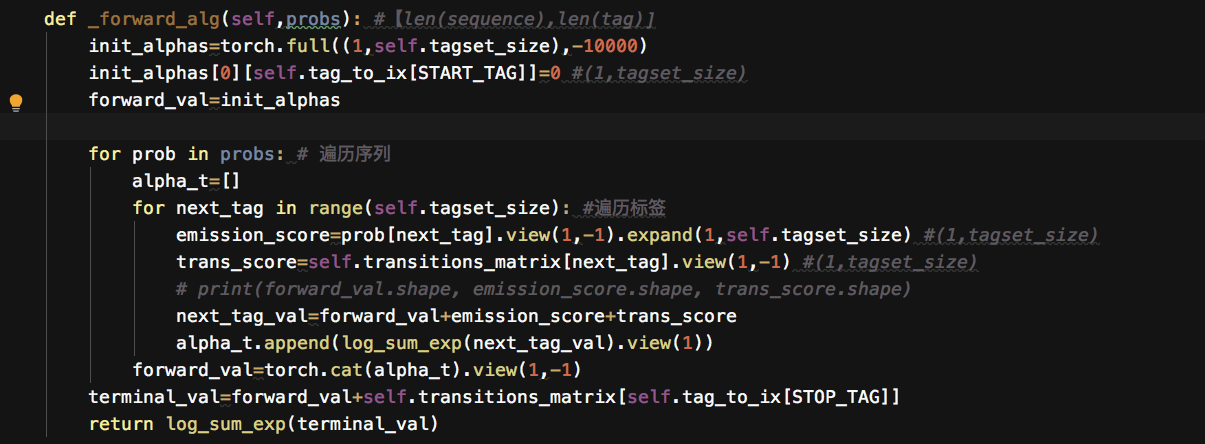
OK,CRF损失函数 对应的函数是
在前行传播计算score,根据真实的标签路径 得到真实路径score,再二者差相剪进行反向传播学习,让模型朝着差值逐步减小的方向迭代,最理想的情况就是 loss=0,所有路径得分=真实路径得分


