结对编程作业
结对编程作业
一、开头
博客链接
具体分工
| AI算法 | 大比拼 | 原型设计 | GUI | 博客编写 | Github | |
|---|---|---|---|---|---|---|
| 魏荣峰 | ✔ | ✔ | ✔ | ✔ | ✔ | |
| 卓越 | ✔ | ✔ |
二、原型设计
设计说明
该原型展示了图片华容道小游戏的部分基本功能与页面,采用MockingBot0.7.8进行原型设计。
游戏中会将原始字符图片平均切割成九个部分,并抠掉一张图当空格。此时图片为原始状态。游戏开始时会将小图顺序打乱,用户通过点击鼠标进行移动小图,直到将打乱的图片恢复至原始状态上即可完成游戏。
原型中的主页面即为进入游戏后的初始页面。中间的图片为所提供的所有字符图片的原图。下方有开始游戏、游戏介绍、排行榜、历史得分四个可点击项。用户可以通过点击第一项开始游戏、点击第二项查看该游戏的基本介绍、点击第三项查看排行榜,点击第四项查看历史得分。

点击Introduction,进入到游戏介绍的页面。用户可在该页面查看游戏规则。阅读完毕后,用户可通过点击下方返回项返回到主页面。

回到主页面。用户点击开始游戏项,可以开始游戏,进入到游戏开始后的初始状态,页面中为被切割并打乱的字符图片。用户通过点击空白两侧的小图片进行图片移动。页面上方有退出项,用户可以点击退出返回到主页面。页面右侧的悬浮框会记录当前移动步数,初始为0。移动到一定步数的时候,系统会强制调换此时棋盘上的两个格子,由于此时棋盘不一定有解,玩家有一次自由调换的机会,可选择调换任意两个图片的位置,该权利仅在棋盘无解的情况下使用,且需紧接着强制调换的操作

成功复原图片后,游戏结束。页面上方会出现提示游戏结束的相关字样。用户可以选择点击重新开始项重新开始游戏,或者点击返回项回到主页面。
点击主页Rank,进入排行榜页面,可查看历史玩家得分的排行情况。

点击主页History Score,可查看各玩家历史得分情况。

原型开发工具
采用的原型开发工具为MockingBot0.7.8。
结对的过程
结对的过程:在团队项目小组内进行结对。
结对照片:

非摆拍.jpg
遇到的困难
由于之前没有接触原型设计和相关的开发工具,在熟悉Mockingbot工具方面花费了较多的时间。好在Mockingbot是中文版的开发工具,上手难度较低。通过观看网上的一些教程,对一些基本功能有了初步的了解。
在设计页面点击和切换功能的时候,由于对开发工具不够熟悉,不知道如何实现该功能,后来发现只要通过拖拽具体模块旁边的闪电标志,连接到具体页面即可实现该功能。同时也学会了使用其他的一些操作,但是界面的美观度还有待提高,希望在以后的原型设计中能够有所改进。
三、AI与原型设计实现
1、代码实现思路
-
网络接口的使用
获取数据:
通过requests库get到url中的json格式数据,并用
eval()转换为列表便于提取def interfaceJson(name): te = requests.get("http://47.102.118.1:8089/api/problem?stuid=041801420") te = eval(te.text) img = base64.b64decode(te['img']) step = te['step'] swap = te['swap'] uuid = te['uuid'] with open(name + '.png', 'wb') as f: f.write(img) f.close() print("get test image successfully") print("saved to : ", './' + name + '.png') return step, swap, uuid提交结果:
通过requests库的post函数提交结果,并得到返回的测试结果
def post(uuid, operation, swap): postUrl = 'http://47.102.118.1:8089/api/answer' swap[0] += 1 swap[1] += 1 datas = { "uuid": str(uuid), "answer": { "operations": str(operation), "swap": swap } } s = json.dumps(datas) print(s) headers = {'Content-Type': 'application/json'} r = requests.post(url=postUrl, headers=headers, data=s) print(r.text) -
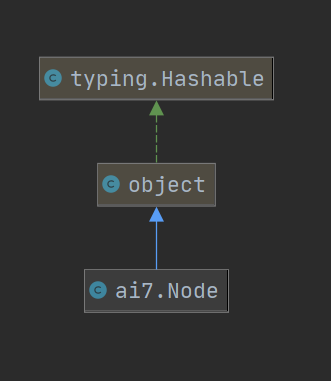
代码组织与内部实现设计(类图)
-
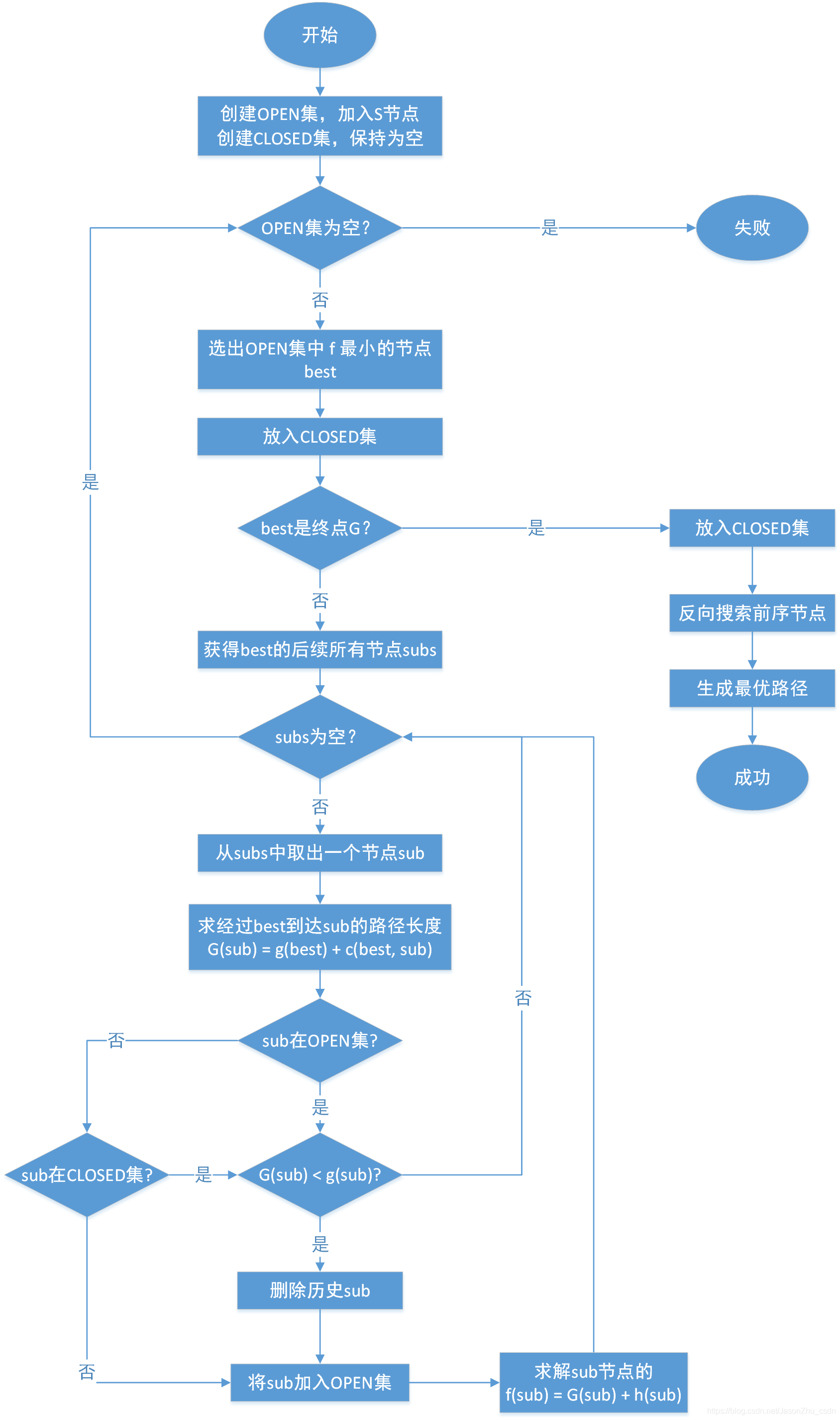
关键算法流程图
A star
-
我认为有价值的代码块
1️⃣根据图片像素不变的属性对于缺了1/9的图片来说,即使将其打乱,这张图片的像素值仍然是不变的;
在此前,前提得到了所有36种字母的
childs(也就是把每张图片都分别生成9张childs,分别在1-9这九个位置设置空白格),在函数countImgs()中,算出每张图像的平均像素值,由此作为该字母's child的索引,从而定位到某一个child,再通过取余确定原图。由以下代码可以得到所有字母的所有缺块情况图片的索引,数据保存在./childIndex.txt,据此我们将实现快速识别出测试图片是哪个字母。
def countImgs(folderPath): """ 注意:由于采用的是img[:, :, 0].mean(),速度较快,仅用于映射识别到原图像 制作索引映射集合,已通过验证,请不要修改此函数 :param folderPath: 输入一个文件夹路相对径--'./child/' :return: 计算出child文件夹内所有子文件夹下的所有字母(不同形态空白)的像素均值 采用img[:, :, 0].mean(),目的是标记每一张图片,作为索引 example: countImgs('./child/') """ with open(folderPath + '/childIndex.txt', 'a+', encoding='utf-8')as text: root_dir = folderPath sub_list = os.listdir(root_dir) for folder in sub_list: print(folder) if folder.split('.')[-1] == 'txt': continue img_list = os.listdir(os.path.join(root_dir, folder)) for img_name in img_list: if img_name.split('.')[-1] != 'png' and img_name.split('.')[-1] != 'jpg': continue img_path = os.path.join(root_dir, folder, img_name) print(img_path) img = cv2.imread(img_path) text.write(str(img[:, :, 0].mean()) + '\n') print("index:", str(img[:, :, 0].mean())) text.close()2️⃣同样根据像素的原理,我们对每一张test的图片进行切割,分成9份,找到的原图进行一一比对并且与之前,将原图按12345678顺序编码,白块固定编码为0,由此映射到test图片,得到test图片对应编码
根据原图和test图片的编码,我们就可以开始A * 算法进行路径搜索
def getSequence(): step, swap, uuid = interfaceJson('test') testIndex = countImg('./test.png') # origImgPath -> ./child\A_ (2)\_sub7.png origImgPath = str(mapped(testIndex)) # countImg('./child/O_/_sub8.png') clip('./test.png') # 因为origImgPath是os.path.join生成的,并不全是相对路径的/,所以不能直接用clip函数中自带的split方法 clip(origImgPath.replace('\\', '/')) testBlocks = count("./imgsClipped/test") origBlocks = count('./imgsClipped/' + str(origImgPath).split('\\')[-1].split('.')[0]) origT = [] testT = [] cnt = 1 for item in origBlocks: if item == 255: origT.append(0) else: origT.append(cnt) cnt += 1 # print(origT) for item in testBlocks: testT.append(origT[origBlocks.index(item)]) print("orig: ", origT, '\n', "test:", testT) print("swap at steps:", step) swap[0] -= 1 swap[1] -= 1 print("to be swap:", swap) return origT, testT, step, swap, uuid3️⃣搜索核心:A star算法
def AStar(init, goal): # 边缘队列初始已有源状态节点 size = int(9 ** 0.5) start = tuple(init) process = list([]) target = tuple(goal) # 优先队列,值越小,优先级越高 pQueue = PriorityQueue() pQueue.put([0 + calDistance(start, size), start, start.index(0), 0, process]) seen = {start} # 已遍历过的结点 while not pQueue.empty(): _pri, board, pos0, depth, process = pQueue.get() if board == target: return depth, process for d in (-1, 1, -size, size): # 对应的是左右上下的相邻结点 nei = pos0 + d if abs(nei // size - pos0 // size) + abs(nei % size - pos0 % size) != 1: continue if 0 <= nei < size ** 2: # 符合边界条件的相邻结点 newboard = list(board) newboard[pos0], newboard[nei] = newboard[nei], newboard[pos0] newt = tuple(newboard) if newt not in seen: # 没有被遍历过的状态 seen.add(newt) # pQueue.put([depth + 1 + 2 * self.calDistance(newt), newt, nei, depth + 1, process + [d]]) pQueue.put( [depth + 1 + 0.9 * calDistance(newt, size), newt, nei, depth + 1, process + [d]]) # 调整启发函数的权重可以缩短时间但增加步数 -
性能分析与改进
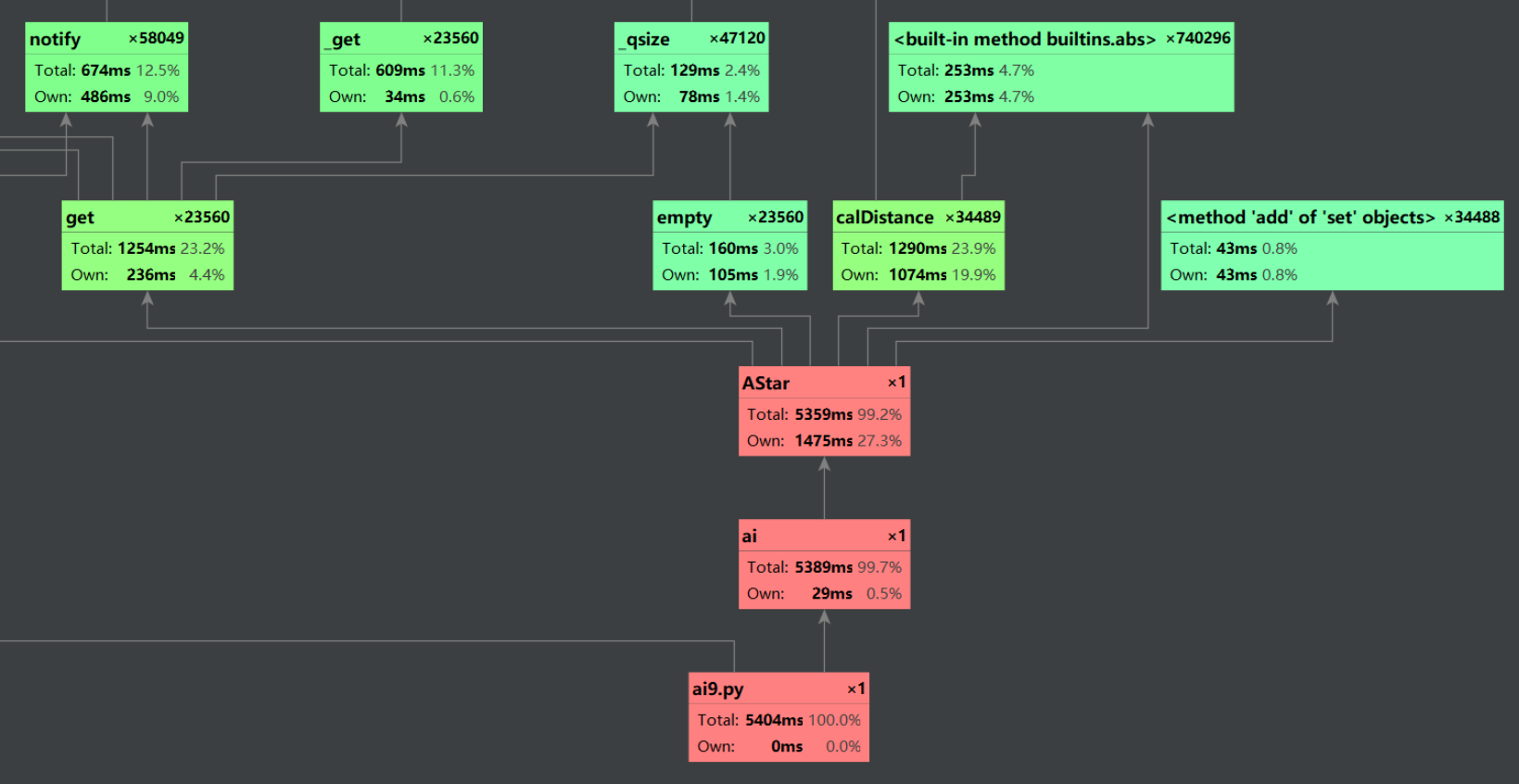
这是原本采用BFS的性能图描述(在A*中设置启发值为0)
测试耗时长达5s+
-
描述你改进的思路
在BFS搜索算法中,如果能在搜索的每一步都利用估价函数f(n)=g(n)+h(n)对Open表(队列)中的节点进行排序,则该搜索算法为
A*算法。由于估价函数中带有问题自身的启发性信息,因此,A*算法又称为启发式搜索算法,可以大大减少搜索时间。 -
性能分析图和程序中消耗最大的函数

2、GitHub签入信息
3、遇到的代码模块异常或结对困难及解决方法
-
问题描述
说来话长,挑几个最痛苦的异常一吐为快:
🅰️最早的时候想,c++的速度应该会比python慢很多,假若大家都用python,而我用c++,应该可以在速度上跑出优势。国庆花了一天弄出c++代码,眼看调试出正确路径挺开心,那么如何将python与c++接口连接🔗呢?
🅱️为什么大比拼的测试总是得到false?明明手动移的方块都是正确的??
-
解决尝试
🅰️了解了ctypes库的使用,然而不知道什么原因,在Windows上python总是无法成功调用,只能采用Linux
🅱️在一遍遍的手动模拟之下,眼睛都看花了。。最后咨询了测试组才知道,规则没有理解正确,所以算法是完全错误的。
-
是否解决
🅰️首先,在编译上我觉得是我系统的问题,经常在安装python包的时候如果需要使用到vs16(好像是这个)编译得到whl的我都会报错,即使我安装了全套vs2015和2019。后面越来越觉得用c++实在不现实,幸好提前退水改用python,不然后面这么多规则怎么改的过来。
🅱️对于我来说,时间实在是有点紧迫,直到AI大比拼的第三天我才知道规则没有理解正确
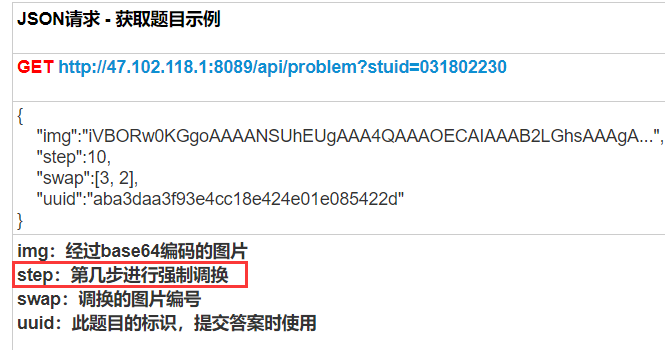
个人认为,这里的step表示第几步进行强制交换,那应该是走了step-1步以后到了即将走第step步时交换呢,还是走完step步了在第step步的时候做交换?可能是我语文水平的问题
-
有何收获
读懂规则确实重要。虽然说很多的消息都是在群里流水账一般源源不断,但总得静下心来,仔细阅读一番,才能明确方向,而不是一直按照自己的理解。
最后一天才写出能在大比拼中每submit每true的代码,可能也是不想留遗憾吧,一方面不希望之前的努力付之东流,因为我很清楚其实离成功很近,只是规则上没有完全理透,然而另一方面来说,其实还是很遗憾,最后一天已经改变不了多少分数了,即使我这三天都没有改代码,用之前旧版的代码也能rank20-40,功利上来说确实亏了。
4、评价队友
-
值得学习的地方
rfgg牛逼,永远滴神。队友承担了大部分工作量,从算法、AI大比拼、代码,到签入github,每一项工作都做的非常出色。
-
需要改进的地方
无。
5、PSP
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 400 | 400 | 6 | 6 | 熟悉python语言tkinter,pyqt特性 |
| 2 | 500 | 900 | 12 | 19 | c++,了解了ctype用法 |
| 3 | 400 | 1300 | 12 | 31 | 完成字母识别 |
| 4 | 800 | 2100 | 20 | 51 | 学习A star,完成AI算法,基本游戏界面 |
| 5 | 400 | 2500 | 8 | 59 | 改进AI算法,测试 |
四、最后的总结
这次结对编程,虽然学习了一些原型设计和相关开发工具的基本知识和使用方法,但是在这方面依然还有很多需要学习的地方。大量在实际开发过程中呈现出来的功能和页面,我没能通过最初的原型设计实现,这也是令我感到很遗憾的地方。
我的队友承担了本次结对编程作业的很大一部分工作量,除了设计原型外,其他大部分内容都由他完成,我常常只是起到了一个帮助他测试测试代码,完善一些小细节、打打杂之类的微乎其微的作用。这是我需要反思和总结的地方。
希望在以后的项目和作业中,不仅能够发挥自己原本的一些优势,也要勇敢跳出舒适圈,尝试更多新的任务和角色,不断突破自我,取得更多的进步吧。

