

Deep Q-Learning
Deep Q-Learning
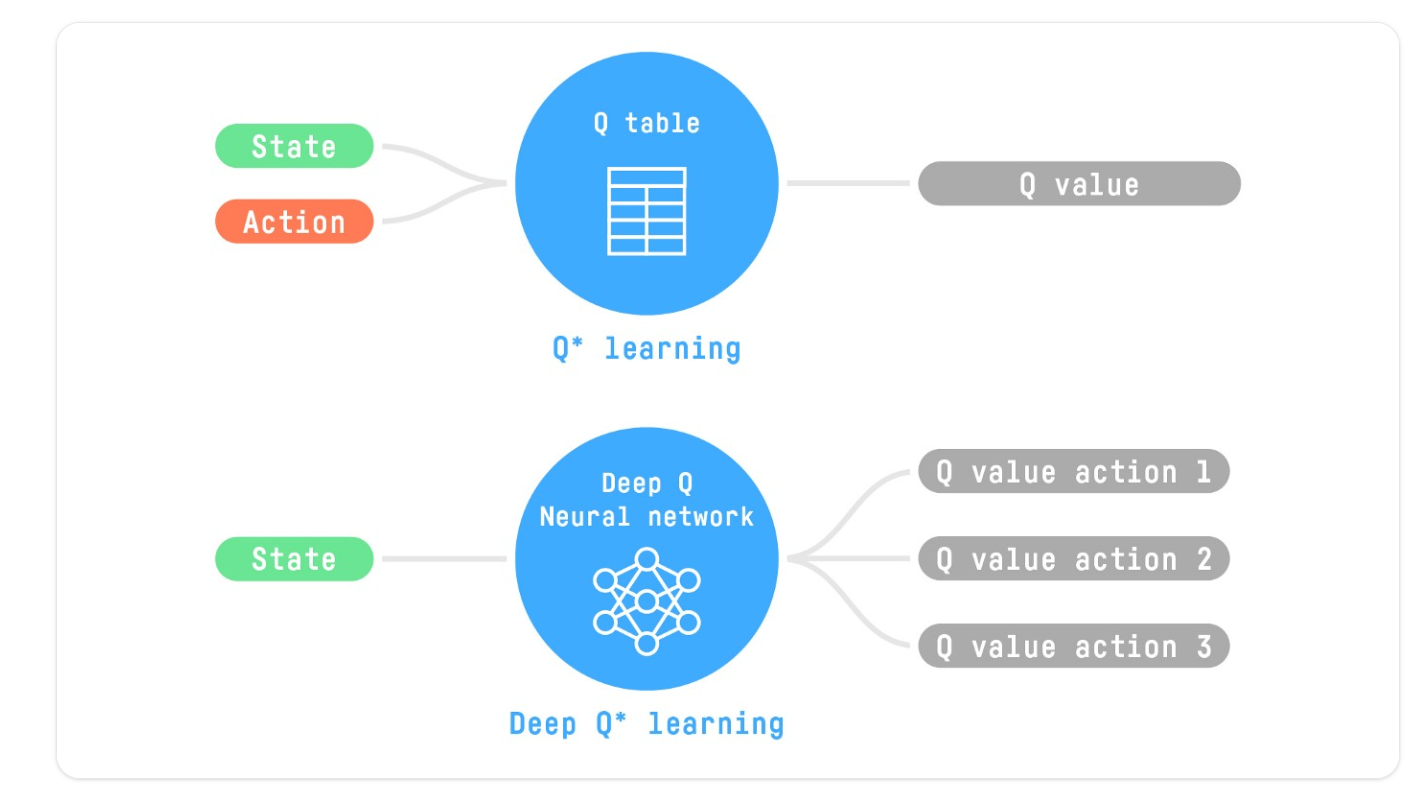
产生和更新Q表在大状态空间环境中可能变得无效
Deep Q-Learning使用了一个神经网络,它获取一个状态,并基于该状态近似每个动作的Q-值,而不是使用Q-表。
我们将使用RL Zoo训练它玩太空入侵者和其他雅达利环境,这是一个使用稳定基线的RL训练框架,提供训练脚本、评估代理、调整超参数、绘制结果和录制视频。
在深度Q-Learning中,我们创建了一个损失函数(loss function),将我们的Q-值预测与Q-目标进行比较,并使用梯度下降来更新我们的深度Q-网络的权重,以更好地逼近我们的Q-值

Deep Q-Learning伪代码

Deep Q-Learning训练算法分为两个阶段:
- 采样(Sampling):我们执行操作并将观察到的经验元组存储在重放存储器中。
- 训练(Training):随机选择一小批元组,并使用梯度下降更新步骤从这一批元组中学习。
与Q-Learning相比,这不是唯一的区别。Deep Q-Learning训练可能会受到不稳定的影响,主要是因为结合了非线性Q值函数(神经网络)和自举(当我们使用现有估计值而不是实际的完整回报更新目标时)
为了使训练稳定,我们实施了三种不同的解决方案:
- Experience Replay可更有效地利用经验(Experience Replay to make more efficient use of experiences)
- 固定Q-Target以稳定训练(Fixed Q-Target to stabilize the training)
- 双重Deep Q-Learning,处理Q值过高的问题(Double DQN)
Deep Q-Learning training algorithm
Experience Replay to make more efficient use of experiences:

经验回放(Experience Replay) 在Deep Q-Learning 中有两个功能:
- 在培训期间更有效地利用经验
通常,在线强化学习中,代理在环境中交互,获取体验(状态、行动、奖励和下一个状态),从中学习(更新神经网络),然后丢弃它们。这是没有效率的。
- 避免忘记以前的经历,并减少经历之间的相关性
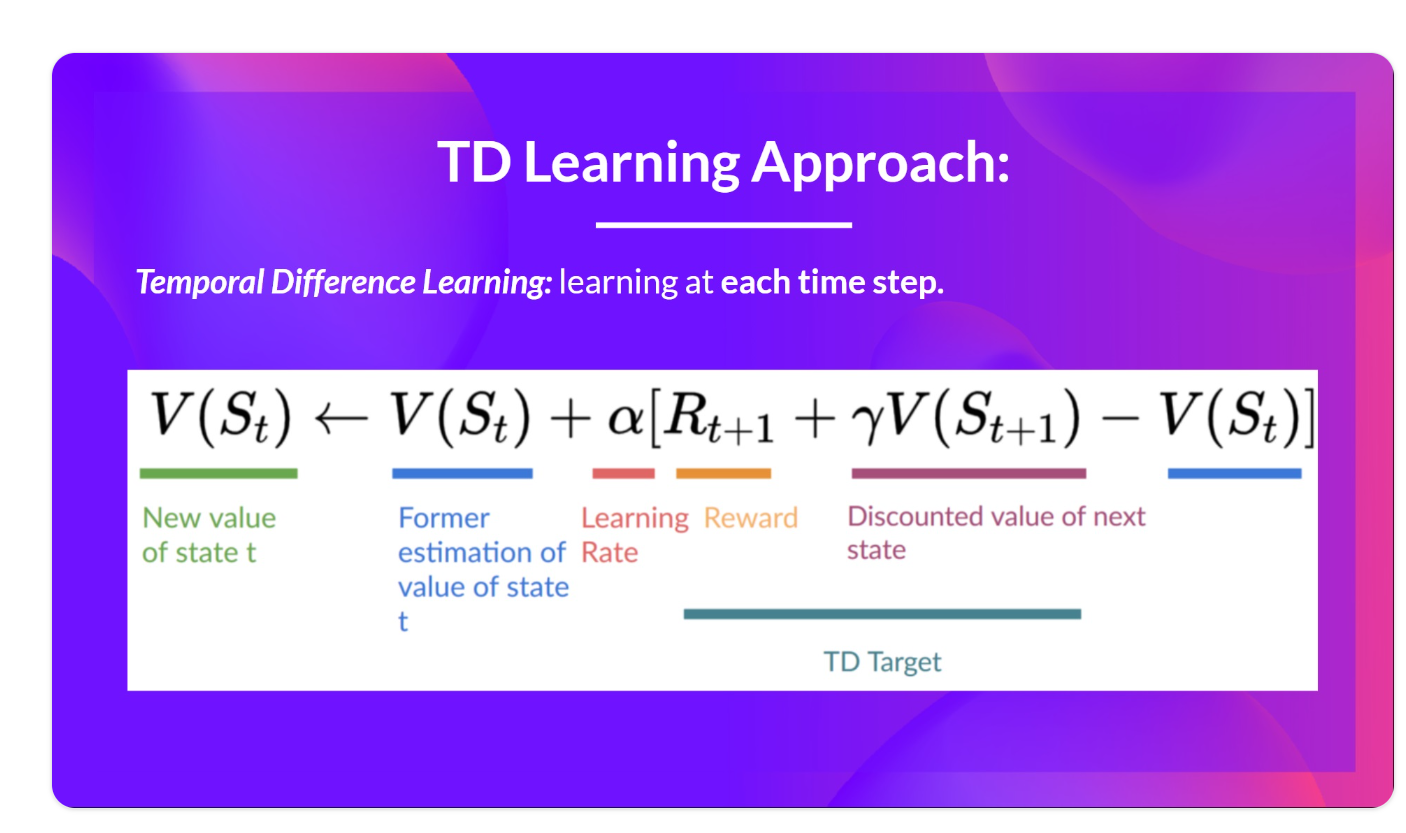
Fixed Q-Target to stabilize the training:
当我们想要计算TD误差(也称为损耗)时,我们计算TD目标(Q-target)和当前Q值(Q的估计)之间的差值。
但我们对真正的TD目标一无所知。我们需要对其进行估计。使用贝尔曼方程( Bellman equation),我们发现TD目标只是在该状态下采取行动的奖励加上下一状态下的贴现最高Q值。
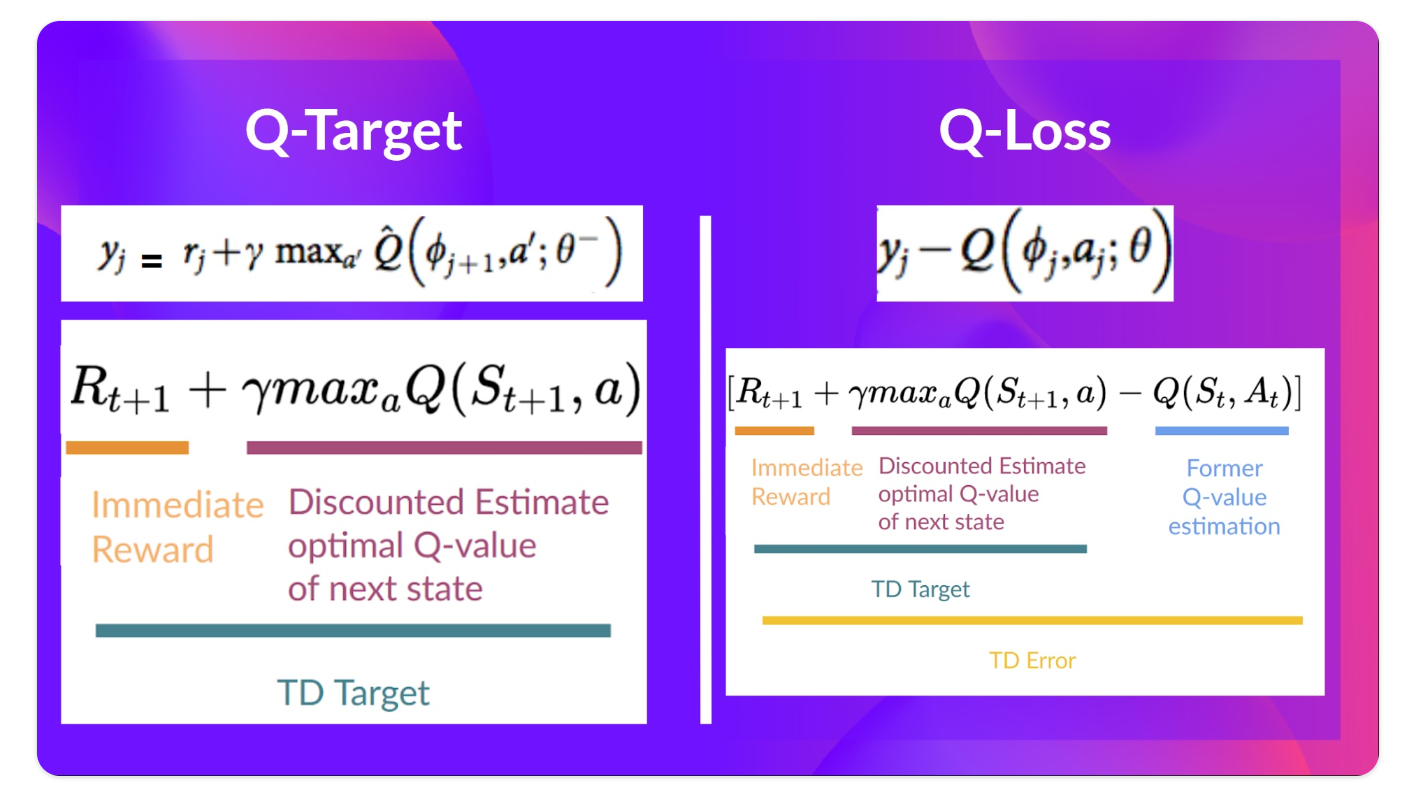

我们在伪代码中看到的是:
- 使用具有固定参数的单独网络来估算TD目标
- 在每个C步骤中复制我们的Deep Q-Network中的参数以更新目标网络
Double DQN:
当我们计算Q目标时,我们使用两个网络将操作选择与目标Q值生成分离。
- 使用我们的 DQN 网络选择要对下一个状态采取的最佳操作(具有最高 Q 值的操作)。
- 使用我们的目标网络计算在下一个状态下采取行动的目标 Q 值。、
因此,Double DQN 帮助我们减少对 Q 值的高估,从而帮助我们更快地训练和获得更稳定的学习



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报