
遗传算法解决TSP问题
- 生成popSize个包含[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14](用random.sample)随机数存在列表oldPop中,并计算通过适值函数(两地之间的距离)计算适应值存在列表oldFit中;
- 进行maxGen次交叉、变异、选择操作;
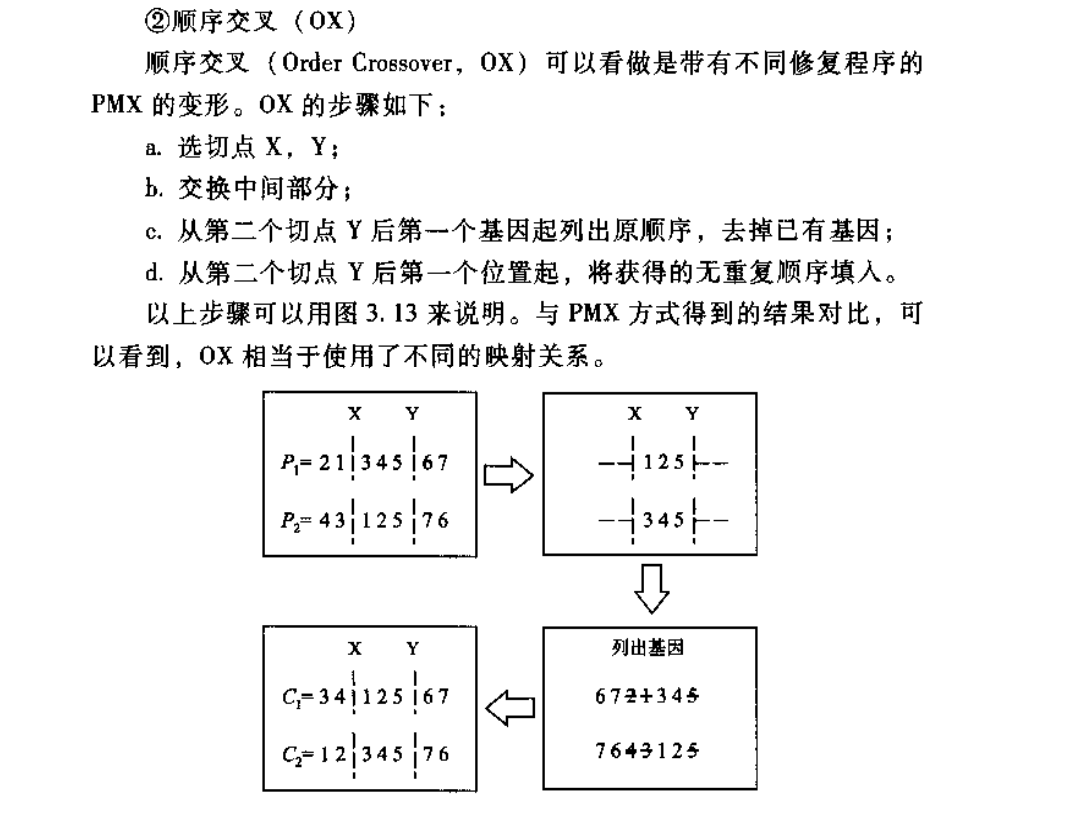
- 交叉方式:顺序交叉(XO)
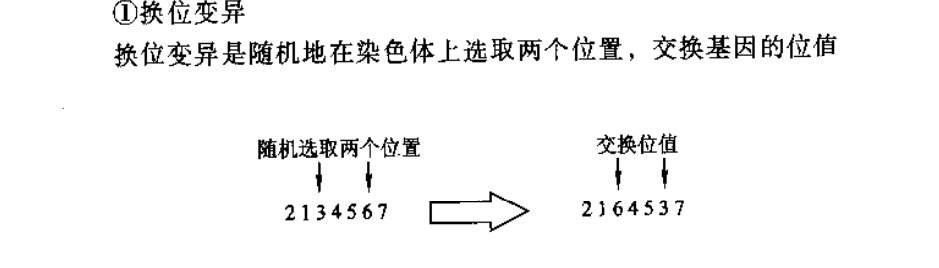
- 变异:
- 选择:从P∪P’里面的个体排序,取最小的前popsize个,组成新的种群
- 得到最优解
main.py
from Func_2opt import *
# 参数值
popSize = 80 # 种群规模
maxGen = 100 # 最大代数
crossProbability = 0.9 # 交叉率
mutProbability = 0.05 # 变异率
MAX_COUNT = 100
oldPop = initialize_pop(popSize)
oldFit = fitness_fun(oldPop)
Fitness = []
for i in range(1, maxGen):
# 交叉,顺序交叉
newPop = crossover(oldPop, crossProbability)
# 变异,换位变异
newPop = mutation(newPop, mutProbability)
# 适应值
# newFit = fitness_fun(newPop)
# 选择,精英选择
[oldPop, oldFit] = sel(oldPop, newPop, popSize)
# 2opt处理
oldPop = opt(oldPop)
oldFit = fitness_fun(oldPop)
Fitness.append(oldFit[0])
# 输出最好的个体和适应度值,即为最优解和最优函数值
bestIndividual = oldPop[0]
bestFitness = oldFit[0]
print("最优解:%s" % bestIndividual)
print("最优函数值:%s" % bestFitness)
draw_tsp(bestIndividual)
draw_func(Fitness, [x for x in range(1, maxGen)])Func_2opt.py
import random
import math
import load_data
from copy import deepcopy
import matplotlib.pyplot as plt
import numpy as np
def initialize_pop(pop_size):
"""
初始化种群,种群列表中每个元素为一个个体,个体[1,2,3,4,5.....city_count]表示旅游途径
:param pop_size: 种群大小
:return: 返回初始化种群列表
"""
city_count = load_data.cityCount
old_pop = []
a = []
for i in range(1, city_count + 1):
a.append(i) # 生成列表[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
for j in range(pop_size):
b = random.sample(a, city_count)
old_pop.append(b)
return old_pop
def dist(city_name):
"""
计算个体的适应值(距离总和)
:param city_name: 个体[1,2,3,4,5.....city_count]表示旅游途径
:return:返回适应值(距离总和)
"""
city_x = load_data.city_x
city_y = load_data.city_y
distance = 0
for i in range(1, len(city_name)):
x1 = city_x[city_name[i - 1] - 1]
y1 = city_y[city_name[i - 1] - 1]
x2 = city_x[city_name[i] - 1]
y2 = city_y[city_name[i] - 1]
s = math.sqrt(pow((x1 - x2), 2) + pow((y1 - y2), 2))
distance = distance + s
s = math.sqrt(pow((city_x[city_name[len(city_name) - 1] - 1] - city_x[city_name[0] - 1]), 2)
+ pow((city_y[city_name[len(city_name) - 1] - 1] - city_y[city_name[0] - 1]), 2))
distance = distance + s
return distance
def fitness_fun(old_pop):
"""
计算种群的适应度
:param old_pop: 种群
:return: 种群的适应值列表
"""
old_fit = []
for a in old_pop:
distance = dist(a)
old_fit.append(distance)
return old_fit
def crossover(old_pop, cross_probability):
"""
顺序交叉,①随机选切点x,y;②交换中间部分;
③从第二个切点y后第一个基因起列出原顺序,去掉已有基因;
④从第二个切点y后第一个位置起,将获得的无重复的顺序填入
:param old_pop:待交叉种群
:param cross_probability:交叉率
:return:交叉后的新种群
"""
new_pop = []
for p in old_pop: # 遍历
a = deepcopy(p)
[x, y] = random.sample(range(0, len(a) - 1), 2) # 随机产生交叉位置
b = deepcopy(old_pop[random.randint(0, len(old_pop) - 1)]) # 随机挑选另外一组城市序列
if random.random() < cross_probability: # 开始交叉
swap_list = a[x: y] # p1-p2为交换部分
swap_list_2 = b[x: y]
for j in range(len(a) - y): # 列表右移len - p2 位
a.insert(0, a.pop()) # [1, 2, 3,*, *, *,4, 5] ==>[4, 5, 1, 2, 3,*, *, *]
b.insert(0, b.pop())
for m in swap_list_2:
if m in a:
a.remove(m) # # 城市1右移后删去和片段2的重复部分
for n in swap_list:
if n in b:
b.remove(n) # # 城市1右移后删去和片段2的重复部分
a = a + swap_list_2 # 去重后加入交换片段
b = b + swap_list
for l in range(len(a) - y): # 左移len - p2 位
a.insert(len(a), a[0]) # 将第一位复制到最后一位
a.remove(a[0]) # 删除第一位
b.insert(len(b), b[0])
b.remove(b[0])
new_pop.append(a)
new_pop.append(b)
else:
new_pop.append(a)
new_pop.append(b)
return new_pop
def mutation(new_pop, mut_probability):
"""
换位变异,随机的在染色体上选取两个位置,交换基因的位值
:param new_pop:待变异种群
:param mut_probability: 变异率
:return:变异后的新种群
"""
for a in new_pop:
if random.random() < mut_probability: # 开始变异
[m, n] = random.sample(range(0, len(a) - 1), 2)
p = a[m]
a[m] = a[n]
a[n] = p
return new_pop
def sel(old_pop, new_pop, pop_size):
"""
选择,将交叉前的种群、变异后的种群后合并后,精英选择前0.2,按照适应值排序,随机选择剩余的0.8
:param old_pop:交叉前的种群
:param new_pop:变异后的种群
:param pop_size:种群大小
:return:选择后的种群
"""
old_pop.extend(new_pop)
old_pop.sort(key=dist)
a = []
elite_choice = int(pop_size * 0.2)
for i in range(elite_choice):
a.append(old_pop[i])
random_sel = random.sample(range(elite_choice, len(old_pop)), pop_size - elite_choice)
for m in random_sel:
a.append(old_pop[m])
b = fitness_fun(a)
return [a, b]
def draw_tsp(bestIndividual):
"""
画最佳路径图
:param bestIndividual:最优解(最佳路径)
:return:
"""
city_x = load_data.city_x
city_y = load_data.city_y
sorted_x = []
sorted_y = []
for i in bestIndividual:
sorted_x.append(city_x[i - 1])
sorted_y.append(city_y[i - 1])
sorted_x.append(city_x[bestIndividual[0] - 1])
sorted_y.append(city_y[bestIndividual[0] - 1])
print(sorted_x)
print(sorted_y)
plt.title("Route")
plt.xlim(min(sorted_x) - 2, max(sorted_x) + 2) # x轴坐标轴
plt.ylim((min(sorted_y) - 2, max(sorted_y) + 2)) # y轴坐标轴
plt.plot(sorted_x, sorted_y, marker='o')
plt.show()
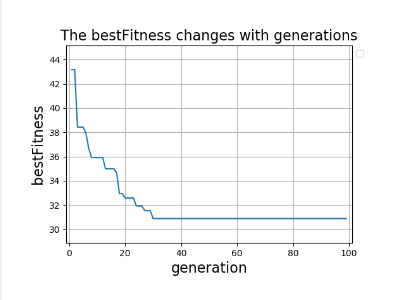
def draw_func(best_fitness, max_gen):
"""
The bestFitness changes with generations
:param best_fitness: 最优解列表
:param max_gen: 最大代数
:return:
"""
plt.legend(loc='upper left', bbox_to_anchor=(1, 1))
plt.tight_layout(pad=5)
plt.xlim(min(max_gen) - 2, max(max_gen) + 2) # x轴坐标轴
plt.ylim((min(best_fitness) - 2, max(best_fitness) + 2)) # y轴坐标轴
plt.grid()
plt.plot(max_gen, best_fitness, )
plt.title('The bestFitness changes with generations', fontsize=16)
plt.xlabel('generation', fontsize=16)
plt.ylabel('bestFitness', fontsize=16)
# plt.savefig('out_14.jpg',bbox_inches='tight')
plt.show()
def generateRandomPath(path):
"""
:param path:
:return:
"""
a = np.random.randint(len(path))
while True:
b = np.random.randint(len(path))
if np.abs(a - b) > 1:
break
if a > b:
return b, a, path[b:a + 1]
else:
return a, b, path[a:b + 1]
def updateBestPath(bestPath):
count = 0
while count < 3:
# print(calPathDist(bestPath))
# print(bestPath.tolist())
start, end, path = generateRandomPath(bestPath)
rePath = path.copy()
rePath[1:-1] = rePath[-2:0:-1]
if dist(path) <= dist(rePath):
count += 1
continue
else:
count = 0
bestPath[start:end + 1] = rePath
return bestPath
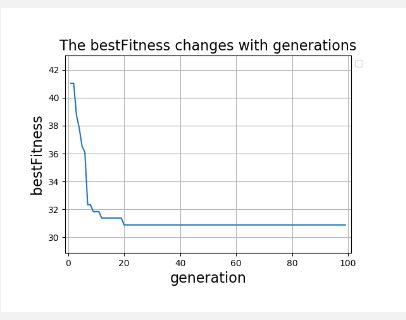
def opt(old_pop):
"""
2opt处理:防止进入局部,尽量使他跳出这个局部最优
路线s:(比方说是A->B->C->D->E->F->G),假设是最短路线min;
随机选择在路线s中不相连两个节点,将两个节点之间的路径翻转过来获得新路径
比方我们随机选中了B节点和E节点,则新路径为A->(E->D->C->B)->F->G,()部分为被翻转的路径;
如果新路径比min路径短,则设新路径为最短路径min,将计数器count置为0,返回步骤2,
否则将计数器count加1,当count大于等于3时,算法结束,此时min即为最短路径,否则返回步骤2;
:param old_pop:待opt处理的种群,2opt处理前20%
:return:opt处理后的种群
"""
opt_choice = int(len(old_pop) * 0.2)
new_pop = []
for i in range(opt_choice):
path = np.array(old_pop[i])
# print(type(path))
new_path = updateBestPath(path)
# new_path = new_path.tolist()
new_pop.append(new_path.tolist())
for j in range(opt_choice, len(old_pop)):
new_pop.append(old_pop[j])
return new_pop # 2opt处理后的新的种群load_data.py
import pandas as pd
import numpy as np
# 载入数据
df = pd.read_csv('burma14.tsp', sep=" ", engine='python', skiprows=lambda x: x <= 7, header=None)
city = np.array(df[0][0:len(df) - 1])
city_name = city.tolist()
# print(city_name)
cityCount = len(city)
city_x = np.array(df[1][0:len(df) - 1])
city_y = np.array(df[2][0:len(df) - 1])
city_location = list(zip(city_x, city_y))
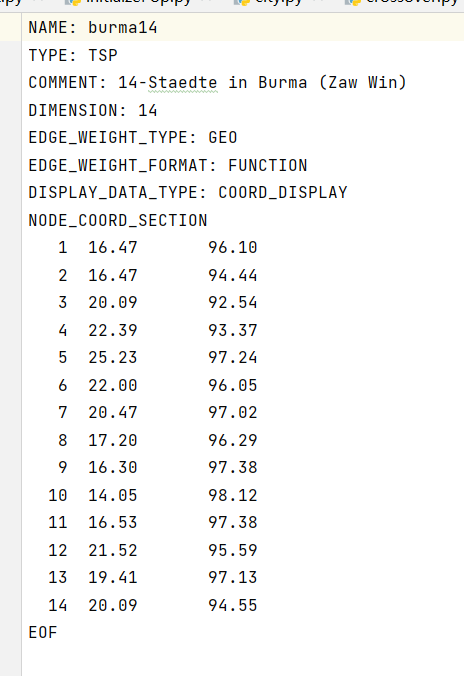
# print(city_location)burma14.tsp
NAME: burma14
TYPE: TSP
COMMENT: 14-Staedte in Burma (Zaw Win)
DIMENSION: 14
EDGE_WEIGHT_TYPE: GEO
EDGE_WEIGHT_FORMAT: FUNCTION
DISPLAY_DATA_TYPE: COORD_DISPLAY
NODE_COORD_SECTION
1 16.47 96.10
2 16.47 94.44
3 20.09 92.54
4 22.39 93.37
5 25.23 97.24
6 22.00 96.05
7 20.47 97.02
8 17.20 96.29
9 16.30 97.38
10 14.05 98.12
11 16.53 97.38
12 21.52 95.59
13 19.41 97.13
14 20.09 94.55
EOF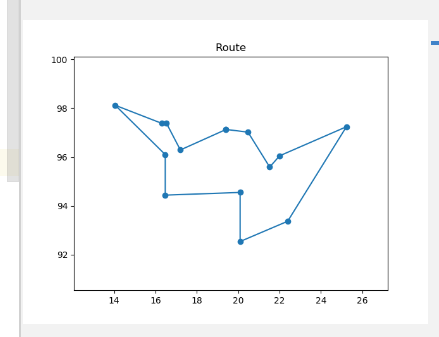
opt优化:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律