

浦语书生大模型实战训练营04笔记和作业
1.1 XTuner
一个大语言模型微调工具箱。由 MMRazor 和 MMDeploy 联合开发。
1.2 支持多种开源LLM
1.3 特色
- 🤓 傻瓜化: 以 配置文件 的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。
- 🍃 轻量级: 对于 7B 参数量的LLM,微调所需的最小显存仅为 8GB : 消费级显卡✅,colab✅
1.4 微调原理
极低的算力去调试跑车
2 快速上手
2.1 平台
Ubuntu + Anaconda + CUDA/CUDNN + 8GB nvidia显卡
2.2 安装
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 2.0.1 的环境:
/root/share/install_conda_env_internlm_base.sh xtuner0.1.9
# 如果你是在其他平台:
conda create --name xtuner0.1.9 python=3.10 -y
# 激活环境
conda activate xtuner0.1.9
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir xtuner019 && cd xtuner019
# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd xtuner
# 从源码安装 XTuner
pip install -e '.[all]'
安装完后,就开始搞搞准备工作了。(准备在 oasst1 数据集上微调 internlm-7b-chat)
# 创建一个微调 oasst1 数据集的工作路径,进入
mkdir ~/ft-oasst1 && cd ~/ft-oasst1
2.3 微调
2.3.1 准备配置文件
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
# 列出所有内置配置
xtuner list-cfg
假如显示bash: xtuner: command not found的话可以考虑在终端输入 export PATH=$PATH:'/root/.local/bin'

拷贝一个配置文件到当前目录: # xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
在本案例中即:(注意最后有个英文句号,代表复制到当前路径)
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
配置文件名的解释:
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
| 模型名 | internlm_chat_7b |
|---|---|
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 把数据集跑几次 | 跑3次:e3 (epoch 3 ) |
2.3.2 模型下载
以下是自己下载模型的步骤。
# 创建一个目录,放模型文件,防止散落一地
mkdir ~/ft-oasst1/internlm-chat-7b
# 装一下拉取模型文件要用的库
pip install modelscope
# 从 modelscope 下载下载模型文件
cd ~/ft-oasst1
apt install git git-lfs -y
git lfs install
git lfs clone https://modelscope.cn/Shanghai_AI_Laboratory/internlm-chat-7b.git -b v1.0.3
2.3.3 数据集下载
https://huggingface.co/datasets/timdettmers/openassistant-guanaco/tree/main
cd ~/ft-oasst1
# ...-guanaco 后面有个空格和英文句号啊
cp -r /root/share/temp/datasets/openassistant-guanaco .
2.3.4 修改配置文件
修改其中的模型和数据集为 本地路径
cd ~/ft-oasst1
vim internlm_chat_7b_qlora_oasst1_e3_copy.py
常用超参
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| evaluation_inputs | 训练过程中,会根据给定的问题进行推理,便于观测训练状态 |
| evaluation_freq | Evaluation 的评测间隔 iter 数 |
| ...... | ...... |
2.3.5 开始微调
训练:
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
例如,我们可以利用 QLoRA 算法在 oasst1 数据集上微调 InternLM-7B:
# 单卡
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
2.3.6 将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
此时,hf 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
可以简单理解:LoRA 模型文件 = Adapter
2.4 部署与测试
2.4.1 将 HuggingFace adapter 合并到大语言模型:
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB
2.4.2 与合并后的模型对话:
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat


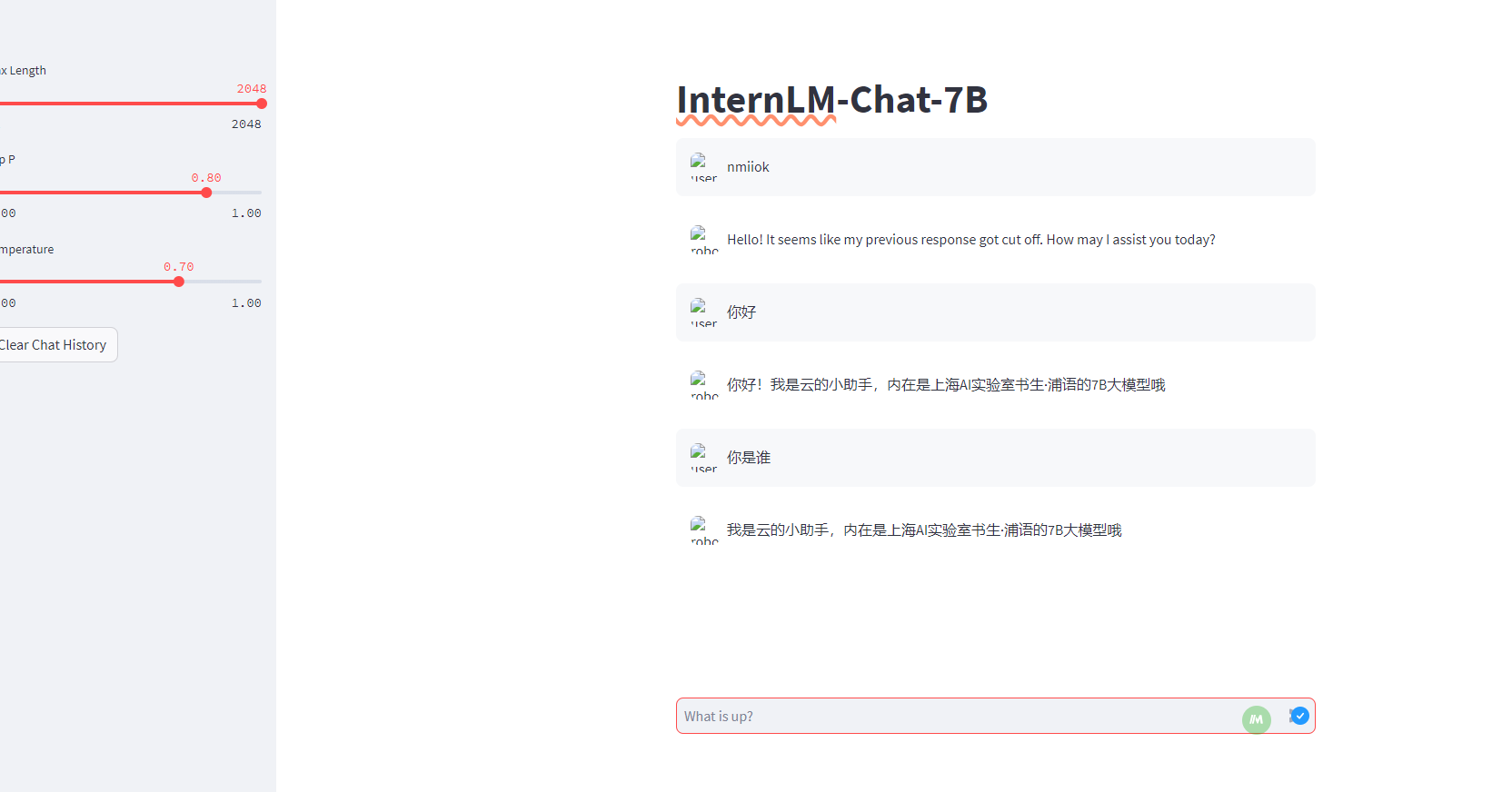
基础作业:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具