
Python的生成器
如何产生一个列表呢?
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author: rex.cheny # E-mail: rex.cheny@outlook.com def main(): list1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] for i in list1: print(i) if __name__ == '__main__': main()
通过上面的语句我们可以定义一个长度为10的列表,还有其他方法吗?
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author: rex.cheny # E-mail: rex.cheny@outlook.com def main(): list1 = [i for i in range(10)] for i in list1: print(i) if __name__ == '__main__': main()
结果和上面是一样的。那么你想一个问题列表占用内存空间,10个元素很少,但是假设有100万个元素的列表,难道你要写100万个吗?显然你会用第二种方法,但是这里有有一个问题,内存中放100万个元素是不是太占空间了?别以为你内存大,如果是10亿呢?这里就要用到列表生成器了。
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author: rex.cheny # E-mail: rex.cheny@outlook.com def main(): list1 = [i for i in range(10)] print(list1) # 通过列表生成器产生列表 list2 = (i for i in range(10)) print(list2) if __name__ == '__main__': main()
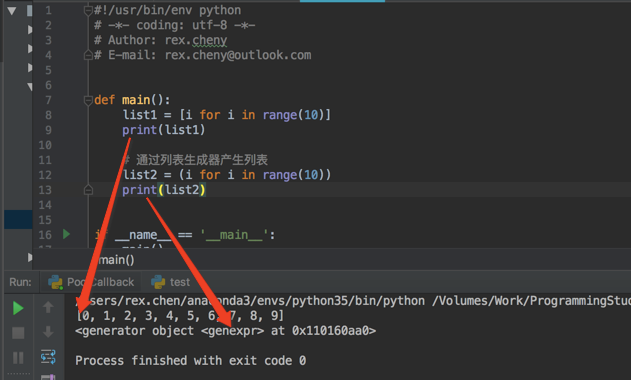
看起来写法差不多啊,其实区别就是把[]换成(),但是输出你发现第一种输出的是真实的列表,而第二种输出的是一个生成器地址。这时候你想了,那我怎么遍历这个列表呢?其实和正常遍历列表一样生成器本身也是可以迭代的。下面我们说说列表生成器是什么?
列表生成器是根据算法推算列表元素,而不是直接定义,这样你创建一个列表生成器而不是创建一个完整列表,当遍历这个列表时,一边遍历一边生成后面的元素,不能跳着访问,真实的列表你可以通过指定下标来访问任意位置,但是列表生成器只能通过遍历挨个访问,所以它也不能做切片。下面我们自定义一个生成器。
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author: rex.cheny # E-mail: rex.cheny@outlook.com # 自定义生成器 def consumtGenerator(max): """ 第一次调用这个函数将返回一个生成器而不是真正执行这里面的方法,只有调这个生成器的next方法才会执行。 yield 可以返回数据,我这里返回 n 同时你也可以把yield赋值给一个变量,这样可以接收数据 m = yield n。 程序走到这里遇到yield就返回了.返回后程序就停在这里了。只有当唤醒之后才会执行下面的语句. """ n = 0 while n < max: yield n n += 1 def main(): # 第一次调用函数,获得一个生成器 a = consumtGenerator(10) for i in a: print(i) if __name__ == '__main__': main()

输出结果是一样的。这里最重要的就是yield。执行过程如下:
- 初始化a成为一个生成器
- 第一次执行 for i in a 将第一次执行自定义生成器函数,n = 0 while这些语句,当遇到yeild时该函数返回n的值,此时是0,然后暂停
- 执行for语句中的打印语句
- 第二次执行for i in a 语句,将第二次执行自定义生成器函数,此时从上一次暂停的地方继续执行也就是 n += 1,然后是while语句,之后再次遇到yeild语句,返回1,然后暂停
- 一次类推直到n = max
通过上例可以看出0-9这10个数字并没有提前定义,而是给定一个算法遍执行遍按照算法计算然后输出值。实际你可以感受到整个执行逻辑就是在自定义生成器和main函数直接来回切换,感觉很像单核心CPU上的多线程不也是来回切换利用速度和时间模拟并发么。
通过生成器编写消费者和生产者
#!/usr/bin/env python # -*- coding: utf-8 -*- def consumer(name, pices): print("--->[%s]等待骨头,请喂我 %d 块。" % (name, pices)) eaten = 0 while True: # 第一次调用这个函数将返回一个生成器而不是真正执行这里面的方法,只有调这个生成器的next方法才会执行。 # yield 可以返回数据,我这里没有返回。程序走到这里遇到yield就返回了,这里为什么赋值给一个变量呢,因为可以接收数据。 # 返回后程序就停在这里了。只有当唤醒send之后才会执行下面的打印语句。 bone = yield if eaten == pices: print("[%s] 我已经吃饱了。" % name) else: print("[%s] 吃了 %s 块骨头。" % (name, bone)) eaten += 1 print("[%s] 我已经吃了 %d 块骨头。" % (name, eaten)) # time.sleep(1) def producer(): # 通过对生成器调用 next()的时候才会执行 next(petDog1) next(petDog2) n = 0 while n < 10: n += 1 print("\033[32;1m[主人]\033[0m 丢 %s 块骨头。" % 1) # send是唤醒生成器,也就是让函数继续执行,这里输入一个参数,表示激活这个生成器的时候给它传递一个变量进去,本例就是上面的 bone 这个变量,丢一块骨头 petDog1.send(1) petDog2.send(1) if __name__ == '__main__': # 函数里面有 yield 第一次调用这个函数它返回的是一个生成器,所以第一次不执行 petDog1 = consumer("金毛", 10) petDog2 = consumer("泰迪", 3) master = producer()

泰迪吃了3块就不吃了,金毛吃10块。是不是有点多线程的意思。其实这是协程,至于协程是什么会有单独文章来讲。

