用户行为分析
本文采用的数据集是阿里天池提供的user_behavior_data_on_taobao_app公开数据集进行分析,期望通过此次分析能通推动产品迭代、实现精准营销,提供定制服务,驱动产品决策等,需要此数据的小朋友们可以前往天池下载
用户行为分析
想要进行精细化运营,围绕的中心永远是用户。用户研究的常用方法有:情境调查、用户访谈、问卷调查、A/B测试、可用性测试与用户行为分析。其中用户行为分析是用户研究的最有效方法之一。
什么是用户行为分析
了解用户行为分析
用户行为分析是对用户在产品上的产生的行为及行为背后的数据进行分析,通过构建用户行为模型和用户画像,来改变产品决策,实现精细化运营,指导业务增长。
在产品运营过程中,对用户行为的数据进行收集、存储、跟踪、分析与应用等,可以找到实现用户自增长的病毒因素、群体特征与目标用户。从而深度还原用户使用场景、操作规律、访问路径及行为特点等。
用户行为分析的目的
对于互联网金融、新零售、供应链、在线教育、银行、证券等行业的产品而言,以数据为驱动的用户行为分析尤为重要。用户行为分析的目的是:推动产品迭代、实现精准营销,提供定制服务,驱动产品决策等。
主要体现在以下几个方面:
- 对产品而言,帮助验证产品的可行性,研究产品决策,清楚地了解用户的行为习惯,并找出产品的缺陷,以便需求的迭代与优化。
- 对设计而言,帮助增加体验的友好性,匹配用户情感,细腻地贴合用户的个性服务,并发现交互的不足,以便设计的完善与改进。
- 对运营而言,帮助裂变增长的有效性,实现精准营销,全面地挖掘用户的使用场景,并分析运营的问题,以便决策的转变与调整。
用户行为分析指标
对用户行为数据进行分析,关键是找到一个衡量数据的指标。根据用户行为表现,可以细分多个指标,主要分为三类:黏性指标、活跃指标和产出指标。
- 粘性指标:主要关注用户周期内持续访问的情况,比如新用户数与比例、活跃用户数与比例、用户转化率、用户留存率、用户流失率、用户访问率。
- 活跃指标:主要考察的是用户访问的参与度,比如活跃用户、新增用户、回访用户、流失用户、平均停留时长、使用频率等。
- 产出指标:主要衡量用户创造的直接价值输出,比如页面浏览数PV、独立访客数UV、点击次数、消费频次、消费金额等。
这些指标细分的目的是指导运营决策,即根据不同的指标去优化与调整运营策略。简而言之,用户行为分析指标细分的根本目的有:一是增加用户的粘性,提升用户的认知度;二是促进用户的活跃,诱导用户的参与度;三是提高用户的价值,培养用户的忠诚度。
实施用户行为分析
确定好用户行为分析指标后,我们可以借助一些模型对用户行为的数据进行定性和定量的分析。
常用的分析模型有:
- 行为事件分析
- 用户留存分析
- 漏斗模型分析
- 行为路径分析
- 福格模型分析
行为事件分析
行为事件分析是根据运营关键指标对用户特定事件进行分析。通过追踪或记录用户行为事件,可以快速的了解到事件的趋势走向和用户的完成情况。
作用:主要是解决用户是谁,从哪里来,什么时候来,干了什么事情,如何做的,归纳总结即为事件的定义遵循5W原则:Who、When、Where、What、How。主要用于研究某行为事件的发生对企业组织价值的影响以及影响程度。
用户留存分析
用户留存分析是一种用来分析用户参与情况与活跃程度的模型。通过留存量和留存率,可以了解用户的留存和流失状况。比如用次日留存、周留存、月留存等指标来衡量产品的人气或粘度。
留存率=新增用户中登录用户数/新增用户数*100%(一般统计周期为天) 新增用户数:在某个时间段(一般为第一整天)新登录应用的用户数; 登录用户数:登录应用后至当前时间,至少登录过一次的用户数; 第N日留存:指的是新增用户日之后的第N日依然登录的用户占新增用户的比例 第1日留存率(即“次留”):(当天新增的用户中,新增日之后的第1天还登录的用户数)/第一天新增总用户数; 第3日留存率:(当天新增的用户中,新增日之后的第3天还登录的用户数)/第一天新增总用户数; 第7日留存率:(当天新增的用户中,新增日之后的第7天还登录的用户数)/第一天新增总用户数; 第30日留存率:(当天新增的用户中,新增日之后的第30天还登录的用户数)/第一天新增总用户数;
作用:
用户留存一般符合40-20-10法则,即新用户的次日留存应该大于40%,周留存大于20%,月留存大于10%才符合业务标准。我们做用户留存分析主要验证是否达到既定的运营目标,进而影响下一步的产品决策。
漏斗模型分析
漏斗模型分析是用户在使用产品过程中,描述各个阶段中关键环节的用户转化和流失率情况。比如在日常活动运营中,通过确定各个环节的流失率,分析用户怎么流失、为什么流失、在哪里流失。找到需要改进的环节,要重点关注,并采取有效的措施来提升整体转化率。
作用:
漏斗模型分析可以验证整个流程的设计是否合理。通过对各环节相关转化率的比较,可以发现运营活动中哪些环节的转化率没有达到预期指标,从而发现问题所在,并找到优化方向。
行为路径分析
行为路径分析就是分析用户在产品使用过程中的访问路径。通过对行为路径的数据分析,可以发现用户最常用的功能和使用路径。并从页面的多维度分析,追踪用户转化路径,提升产品用户体验。 不管是产品冷启动,还是日常活动营销,做行为路径分析首先要梳理用户行为轨迹。用户行为轨迹包括认知、熟悉、试用、使用到忠诚等。轨迹背后反映的是用户特征,这些特征对产品运营有重要的参考价值。
在分析用户行为路径时,我们会发现用户实际的行为路径与期望的行为路径有一定的偏差。这个偏差就是产品可能存在的问题,需要及时对产品进行优化,找到缩短路径的空间。
福格模型分析
福格行为模型是用来研究用户行为原因的分析模型。福格行为模型用公式来简化就是B=MAT,即B=MAT。B代表行为,M代表动机,A代表能力,T代表触发。它认为要让一个行为发生,必须同时具备三个元素:动机、能力和触发器。因此可以借助福格行为模型来评估产品的合理性和能否达到预期目标。
AISAS模型
用户行为分析模型其实也是一种AISAS模型:Attention注意、Interest兴趣、Search搜索、Action行动、Share分享,也影响了用户行为决策。
- Attention Attention是指我们要想获得一定的业绩,就要首先吸引客户的注意。如果没有客户的话,那后面的一切营销活动都会没有任何用武之地。想要吸引客户的注意,我们可以从多方面来下手,比如说通过互动营销这种办法来吸引到店消费。
- Interest 吸引住了客户之后,我们要想真正的留住这些客户,就要让客户对我们的产品产生一定的兴趣,让他们发自内心的想要购买我们的产品。这就要求我们在事先要对目标群体进行一定的市场调查,了解目标群体的痒点。
-
Search 当目标群体对我们产生一定的兴趣之后,他们可能就会通过一些线上或者线下的渠道来搜集我们产品的信息,这个阶段就是搜索阶段。如果要想使客户对我们留下较好的印象,线上要注意搜索引擎优化,线下要做到优化服务、提升口碑。
-
Action 如果客户经过一系列的调查之后对公司的产品较为满意的话,就会直接进行消费。在这个阶段里面促进订单成交的最主要的环节便是销售环节,所以会对销售能力有着较高的要求。
- Share 如果客户使用该企业的产品获得了较好的使用感受,他可能会和周围的人进行分享,向周围的人推荐该企业的产品,这也就是所谓的口碑传播。我们一定要重视口碑传播的重要作用,它的说服力能够秒杀一切营销活动。
数据集描述
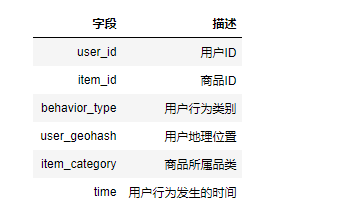
其中,用户行为类别包含点击、收藏、加购物车、支付四种类别,分别用数字1,2,3,4表示
明确分析目的
基于淘宝app平台数据,通过相关指标对用户行为进行分析,推动产品迭代、实现精准营销,提供定制服务,驱动产品决策等。
获得相关指标:
-
总量
-
日pv
-
日uv
用户消费行为分析
- 付费率
- 复购率
通过漏斗模型进行用户行为分析
RFM模型分析用户价值
理解数据
导入相关模块
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import plotly import plotly.graph_objects as go import csv import os import warnings
导入数据
os.getcwd() plt.rcParams["font.family"] = "SimHei" plt.rcParams["axes.unicode_minus"] = False plt.rcParams.update({"font.size":15}) plt.style.use("seaborn-darkgrid") warnings.filterwarnings("ignore") os.chdir(r"H:\大数据分析\用户行为分析") # 数据读入 dt = pd.read_csv("./tianchi_mobile_recommend_train_user/tianchi_mobile_recommend_train_user.csv",dtype=str)
查看数据形态
print(dt.shape)

查看数据集的字段
print(dt.columns)
# user_id 用户id item_id 商品id
# behavior_type 用户行为类别(1:点击,2:收藏,3:加入购物车,4:支付)
# user_geohash 用户地理位置 item_category 商品所属品类
# time 用户行为发生的时间

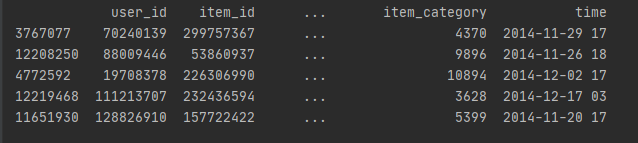
随机抽取数据集中的5条数据
print(dt.sample(5))
清洗数据
缺失值处理
统计缺失值
统计缺失率
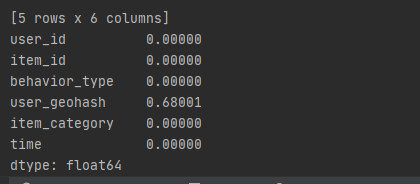
print(dt.apply(lambda x: sum(x.isnull()) / len(x), axis=0))
统计缺失列中的缺失项总量
print(dt.user_geohash.isnull().sum())

可见只有user_geohash这一列缺失,缺失率为68.001%,共缺失8334824,暂不处理
日期时间数据处理
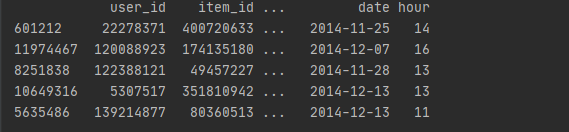
从抽样的5份数据看出,time字段包含日期及小时,这儿对日期与小时作拆分
# 日期时间数据处理,从抽样的5份数据看出,time字段包含日期及小时,这儿对日期与小时作拆分 dt['date'] = dt['time'].str[0:10] dt['hour'] = dt['time'].str[11:] print(dt.sample(5))
更改数据类型
查看数据集的字段类型
print(dt.info())
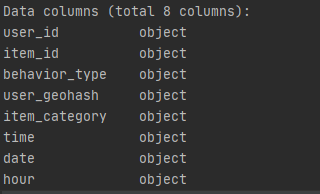
更改time、date为日期型数据,hour为int型数据
# 更改time、date为日期型数据,hour为int型数据 dt['date'] = pd.to_datetime(dt['date']) dt['time'] = pd.to_datetime(dt['time']) dt['hour'] = dt['hour'].astype('int') print(dt.info())

异常值处理
dt.sort_values(by="time", ascending=True, inplace=True) dt.reset_index(drop=True, inplace=True) dt.describe(include="all")
观察知并无异常数据
数据分析
总量
# 用户总量 totle_num = dt["user_id"].drop_duplicates().count()
pv、uv分析
- pv(访问量):PageView
- uv(访客量):UniqueVisitor
日访问分析
日pv : 记录每天用户访问次数
# 日pv : 记录每天用户访问次数 pv_d = dt.groupby("date").count()["user_id"]
pv_d.name="pv_d"

pv_d.index.name
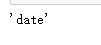
日uv : 记录每日上线的用户数
# 日uv : 记录每日上线的用户数 uv_d = dt.groupby('date')["user_id"].apply( lambda x: x.drop_duplicates().count())
uv_d.name = "uv_d"
uv_d

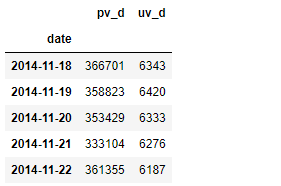
合并uv_d与pv_d
# 合并uv_d与pv_d pv_uv_d = pd.concat([pv_d, uv_d], axis=1)
查看pv_d与uv_d间的相关系数
# 查看pv_d与uv_d间的相关系数 method = ["pearson", "spearman"] for i in method: corr = pv_uv_d.corr(method=i) print(f"{i}相关系数:{corr.iloc[0,1]:.3f}")

访问量与访问用户间的pearson相关系数为0.921、spearman相关系数为0.825,表现为强相关性
plt.rcParams["font.family"] = "SimHei" plt.figure(figsize=(16, 9)) plt.subplot(211) plt.plot(pv_d,c="m",label="pv") plt.legend() plt.subplot(212) plt.plot(uv_d, c="c",label="uv") plt.legend() plt.suptitle("PV与UV变化趋势", size=25) plt.show()
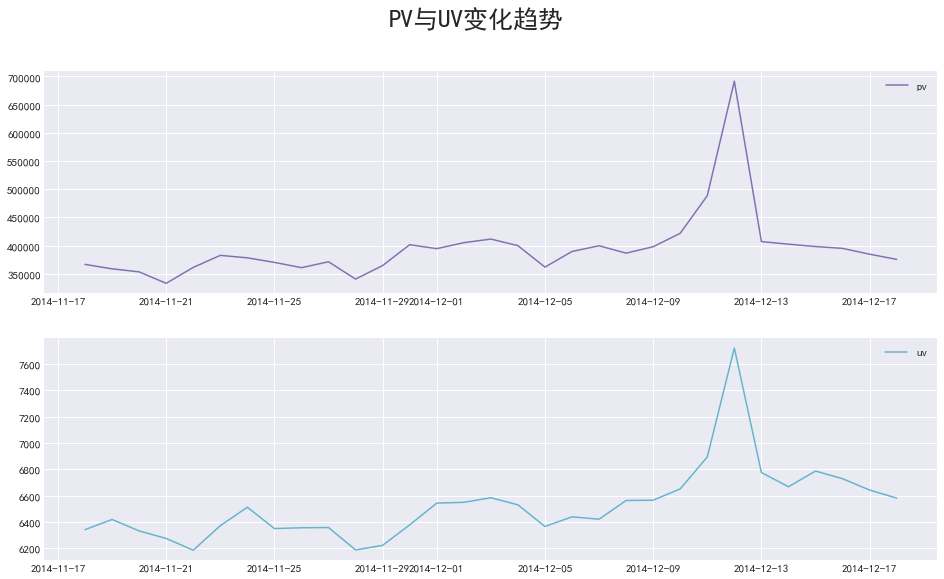
通过图形我们很容易发现双十二期间,pv与uv同时到达峰值
小时访问分析
# pv_h 记录每天中各小时访问次数 pv_h = dt.groupby(["date","hour"]).count()["user_id"]
pv_h.name = "pv_h"
pv_h.head()
uv_h 记录每天中各小时访问用户数
# uv_h 记录每天中各小时访问用户数 uv_h = dt.groupby(["date", "hour"])["user_id"].apply(lambda x: x.drop_duplicates().count())
uv_h.name = "uv_h" uv_h.sample(5)
合并uv_h与pv_h
# 合并uv_h与pv_h pv_uv_h = pd.concat([pv_h, uv_h], axis=1) pv_uv_h.sample(5)
pd.MultiIndex.to_frame(pv_h.index)
查看pv_h与uv_h间的相关系数
# 查看pv_h与uv_h间的相关系数 method = ["pearson", "spearman"] for i in method: corr = pv_uv_h.corr(method=i) print(f"{i}相关系数:{corr.iloc[0,1]:.3f}")

结论: 访问量与访问用户间的pearson相关系数为0.929、spearman相关系数为0.943,表现出极强的相关性
对某天不同时间的pv,uv变化趋势进行可视化
# 对某天不同时间的pv,uv变化趋势进行可视化 # 以2014-12-12为例 plt.figure(figsize=(16, 9)) plt.subplot(211) plt.plot(pv_h.loc["2014-12-09"].values.tolist(), lw=3, label="每小时访问量") plt.xticks(range(0, 24)) plt.legend(loc=2) plt.subplot(212) plt.plot(uv_h.loc["2014-12-09"].values.tolist(), c="c", lw=3, label="每小时访问客户数") plt.suptitle("PV与UV变化趋势", size=22) plt.xticks(range(0, 24)) plt.legend(loc=2) plt.show()
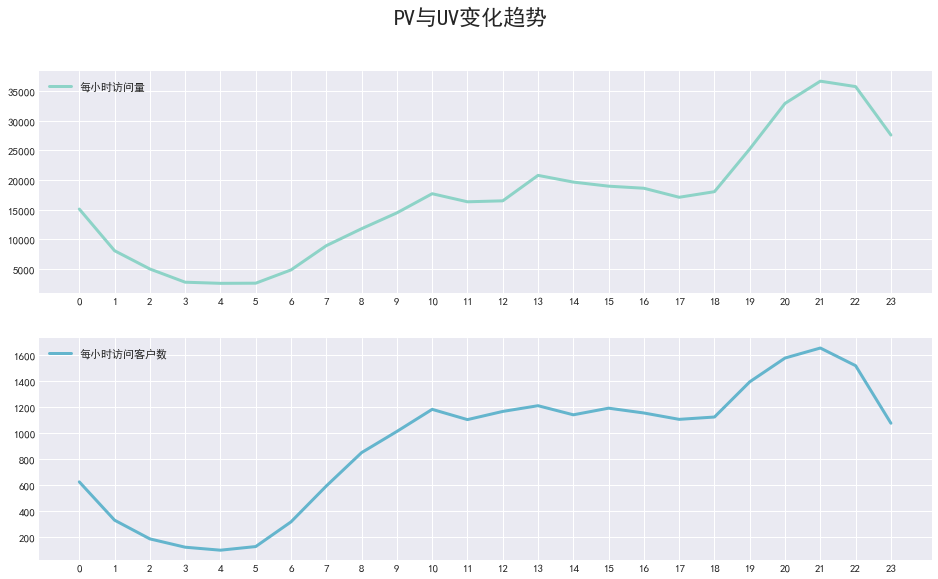
结论:PV与UV呈相同的变化趋势,0-5点呈下降趋势,5-10逐渐增长,21时附近达到峰值,18点-0点为淘宝app用户活跃时间段
不同行为类型用户PV分析
计算不同行为的用户,在每小时的访问量
# 计算不同行为的用户,在每小时的访问量 d_pv_h = pd.pivot_table(columns="behavior_type", index=["hour"], data=dt, values="user_id", aggfunc=np.size)
d_pv_h.sample(10)
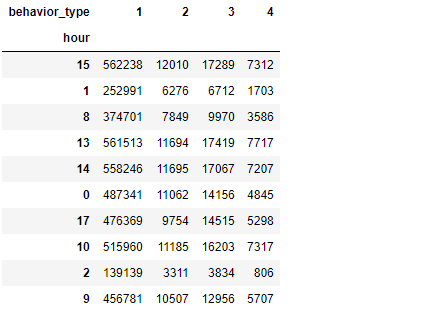
d_pv_h.rename(columns={"1": "点击", "2": "收藏", "3": "加购物车", "4": "支付"})
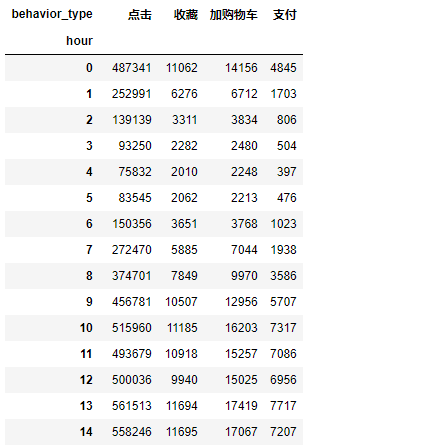
plt.figure(figsize=(10, 4)) sns.lineplot(data=d_pv_h, lw=3) plt.show()
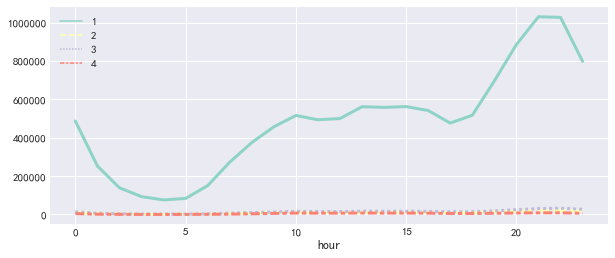
plt.figure(figsize=(10, 4)) sns.lineplot(data=d_pv_h.iloc[:, 1:], lw=3) plt.show()
结论:用户行为类别1,2,3,4分别表示点击、收藏、加购物车、支付,我们可以发现四种用户行为的波动情况基本一致,加购物车的数量高于收藏数
计算各类行为间的流失率
# 计算各类行为间的流失率 d_pv_h["1-2流失率"] = (d_pv_h.iloc[:, 0] - d_pv_h.iloc[:, 1]) / d_pv_h.iloc[:, 0] d_pv_h["1-3流失率"] = (d_pv_h.iloc[:, 0] - d_pv_h.iloc[:, 2]) / d_pv_h.iloc[:, 0] d_pv_h["2-4流失率"] = (d_pv_h.iloc[:, 1] - d_pv_h.iloc[:, 3]) / d_pv_h.iloc[:, 1] d_pv_h["3-4流失率"] = (d_pv_h.iloc[:, 2] - d_pv_h.iloc[:, 3]) / d_pv_h.iloc[:, 2]
print(d_pv_h)
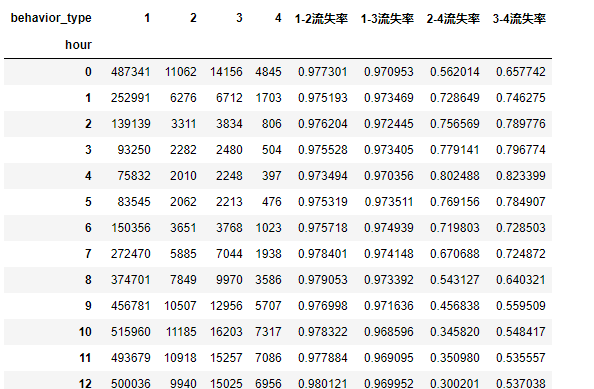
获取有支付行为的客户信息
# 获取有支付行为的客户信息 plt.figure(figsize=(10, 8)) plt.subplot(211) sns.lineplot(data=d_pv_h.iloc[:, 4:6], lw=3) plt.subplot(212) sns.lineplot(data=d_pv_h.iloc[:, 6:], lw=3) plt.show()
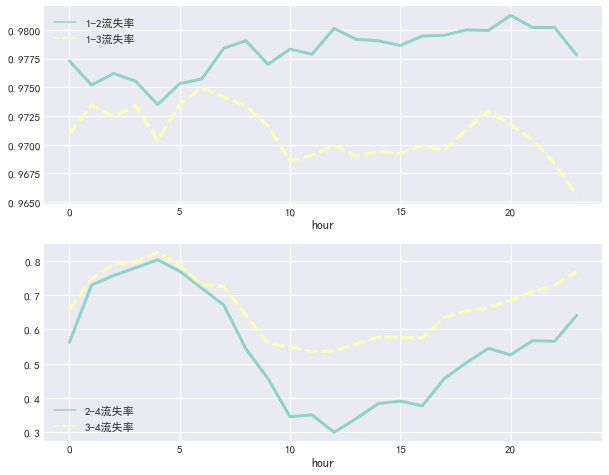
结论:我们能够看到在点击到加购物车和点击到收藏行为间的流失率基本稳定在97.7%左右;在10-15日期间从收藏到支付与从加购物车到支付的流失率较低。
刚开始接触到这类指标,可能得不到多少有效的结论。但不用担心,数据收集和分析持续一段时间后,数据会稳定,你也会适应应用特有的数据分布模式。若是没有这个积累过程,就算面对一个用户严重流失的层次,你也可能完全说不出个所以然。
在获得基线之后,我们可以将数据与基线比较,衡量改动。改进之后,重新收集相关数据。为积累足够访问量,收集过程需要相当时间。获得的数据能清楚地表明改动的效果:若改动后,用户流失比原来小了,那就说明改动成功。相反则需重新考虑设计
消费行为分析
购买频次分析
获取有支付行为的客户信息
dt_buy = dt[dt.behavior_type=="4"]
dt_buy.sample(5)
获取客户消费次数
# 获取客户消费次数 buy_c = dt_buy.groupby("user_id").size()
buy_c.sample(10)
buy_c.describe()

结论:从以上统计可以看出,用户平均购买次数为13.5次,标准差19.6,具有一定波动性。中位数是8次,75分位数是17次,说明用户购买次数大部分都在20次以下。而最大值是809次,这差别有点大。
- 一般情况,消费类型的数据分布,大部分呈现的是长尾形态;绝大多数用户是低频次消费客群,但用户贡献率集中在少数分群里,符合二八法则。
plt.hist(x=buy_c,bins=100)
plt.show()
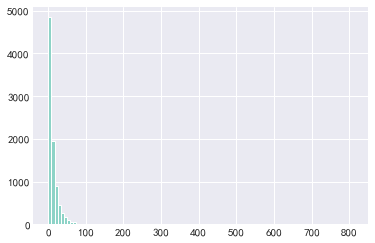
plt.hist(x=buy_c[buy_c.values<=30],bins=10)

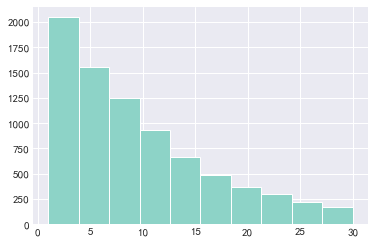
日ARPPU分析
ARPPU(average revenue per paying user)是指从每位付费用户身上获得的收入,即统计周期内,付费用户对产品产生的平均收入
ARPPU = 总收入 / 付费用户数
人均消费次数 = 消费总次数 / 消费总人次数
# 人均消费次数 = 消费总次数 / 消费总人次数 dt_arppu = dt[dt.behavior_type == "4"].groupby( ["date", "user_id"])["behavior_type"].count().reset_index().rename( columns={"behavior_type": "buy_count"})
dt_arppu.sample(10)
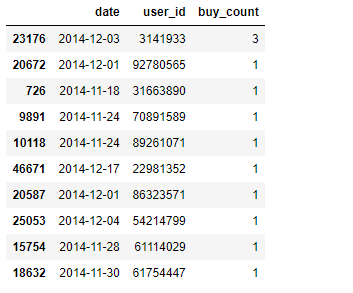
dt_arppu.describe()
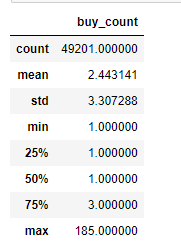
计算ARPPU
# ARPPU = 每日消费总次数除以消费总人数 ARPPU = pd.DataFrame( dt_arppu.groupby("date").sum()["buy_count"] / dt_arppu.groupby("date").count()["buy_count"]).rename( columns={"buy_count": "ARPPU"})
ARPPU.describe()
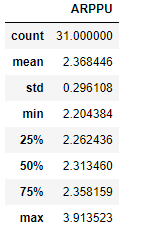
ARPPU.plot()

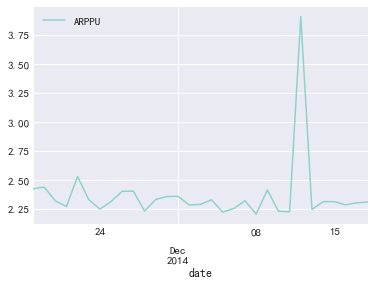
结论:绝大部分消费客户每天消费次数在3次以内,双十二期间达到峰值
日ARPU情况分析
ARPU值 (每用户平均收入,Average Revenue Per User) 就是指每用户平均收入。ARPU注重的是一个时间段内运营商从每个用户所得到的利润。很明显,高端的用户越多,ARPU越高。在这个时间段,从运营商的运营情况来看,ARPU值高说明利润高,这段时间效益好。它可以衡量产品的盈利和发展活力。
ARPU = 消费总收入 / 用户数
因数据集中没有消费金额信息,本次采用消费次数代替消费金额
# 新增一列以便记录各行为次数 dt["behavior_count"] = 1
dt.sample(3)

dt_arpu = dt.groupby(["date", "user_id", "behavior_type" ])["behavior_count"].count().reset_index()
dt_arpu.sample(10)
ARPU = dt_arpu.groupby("date").apply( lambda x: x[x.behavior_type == "4"].sum()/len(x.user_id.unique()))
ARPU.describe()
ARPU.plot()
结论:淘宝app活跃用户(有过操作行为的用户)在2014-11-18至2014-12-18这31天内,每天消费次数在0.5次上下波动,而在双十二期间到达峰值1,976,即平均每人双十二消费2次
付费率
付费率 = 消费人数 / 总用户数
从此份数据中我们不能得到淘宝总用户数,故使用活跃用户总数代替总用户数
# 从此份数据中我们不嫩得到淘宝总用户数,故使用活跃用户总数代替总用户数 rate_pay = dt_arpu.groupby("date").apply(lambda x: x[ x.behavior_type == "4"].count() / len(x.user_id.unique())).iloc[:, 1]
rate_pay.plot()
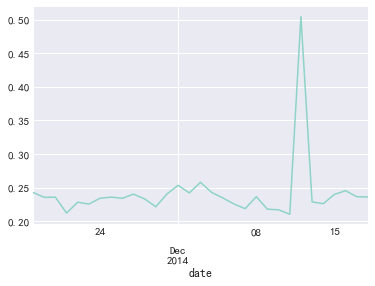
rate_pay.describe()
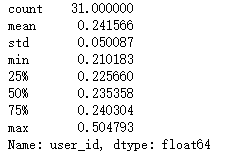
结论:在每天活跃用户群中,具有消费行为的占24%左右,双十二到达50%
同一时间段用户消费次数分布
pay_f = dt[dt.behavior_type=="4"].groupby(["user_id","date","hour"])["behavior_count"].sum()
sns.distplot(pay_f)

pay_f.describe()

pay_f.mode()

结论:在同一小时段中,用户消费次数最多的为一次,75分位数为2次
复购情况分析
复购情况:存在两天及以上有购买行为,一天多次购买算作一次
复购率 = 又复购行为的用户数 / 有购买行为的用户数
复购率
每个用户在不同日期购买总次数
# 每个用户在不同日期购买总次数 dt_rebuy = dt[dt.behavior_type == "4"].groupby('user_id')["date"].apply( lambda x: len(x.unique())).rename("rebuy_count")
dt_rebuy.sample(5)

print("复购率为:%.3f"%(dt_rebuy[dt_rebuy>=2].count()/dt_rebuy.count()))
复购时间分析
计算不同时间,不同用户的购买次数
# 计算不同时间(天),不同用户的购买次数 dt_buy_d = dt[dt.behavior_type == "4"].groupby( ["user_id", "date"])["behavior_count"].count().reset_index()
dt_buy_d.sample(10)
不同用户购物时间间隔
# 不同用户购物时间间隔 dt_buy_d["d_diff"] = dt_buy_d.groupby("user_id").date.apply( lambda x: x.sort_values().diff(1)).map(lambda x:x.days)
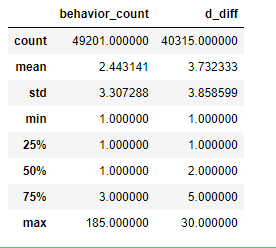
dt_buy_d.describe()
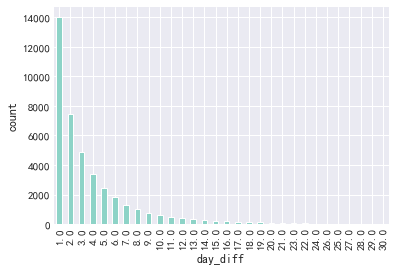
# 绘图 dt_buy_d.iloc[:,-1].dropna().value_counts().plot(kind="bar") plt.xlabel("day_diff") plt.ylabel("count")
Text(0, 0.5, 'count')
不同用户平均复购时间
# 不同用户平均复购时间 sns.distplot(dt_buy_d.groupby("user_id").d_diff.mean().dropna())
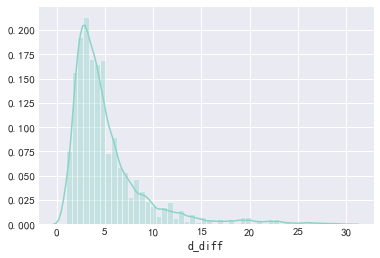
计算分位数
dt_buy_d.quantile(np.linspace(0,1,11)).iloc[:,1]

结论:80%的淘宝用户复购复购时间在6天以内
漏斗流失分析
dt_c = dt.groupby("behavior_type").size()

print("从点击到收藏流失率为%.3f" % ((dt_c[0] - dt_c[1]) * 100 / dt_c[0]))
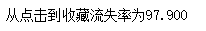
print("从点击到加购物车流失率为%.3f" % ((dt_c[0] - dt_c[2]) * 100 / dt_c[0]))
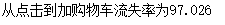
print("从加购物车到支付流失率为%.3f" % ((dt_c[2] - dt_c[3]) * 100 / dt_c[2]))
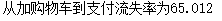
print("从加收藏到支付流失率为%.3f" % ((dt_c[1] - dt_c[3]) * 100 / dt_c[2]))
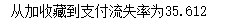
用户价值RFM模型分析
因数据集中无消费金额相关信息,因此此处仅对R、F两方面进行用户价值分析
每位用户最近的购买时间
# 参考时间 from datetime import datetime datenow = datetime(2014, 12, 19)
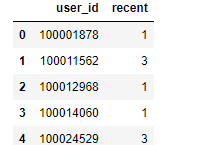
# 每位用户最近的购买时间 recently_pay_time = dt[dt.behavior_type == "4"].groupby("user_id").date.apply( lambda x: datenow - x.sort_values().iloc[-1])
recently_pay_time = recently_pay_time.rename("recent")
recently_pay_time = recently_pay_time.reset_index()
recently_pay_time.recent = recently_pay_time.recent.map(lambda x: x.days)
recently_pay_time.head(5)
每位用户消费频率
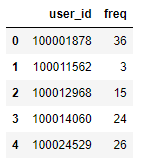
# 每位用户消费频率 buy_freq = dt[dt.behavior_type == "4"].groupby("user_id").date.count().rename( "freq").reset_index()
buy_freq.head()
因为只有31天的数据,所以这儿只基于等频分段,简单的将R、F分为两个等级
# 因为只有31天的数据,所以这儿只基于等频分段,简单的将R、F分为两个等级(分数越高越好) RFM = pd.merge(recently_pay_time,buy_freq,on="user_id",how="outer") RFM["R_value"] = pd.qcut(RFM["recent"],2,labels=["2","1"]) RFM["F_value"] = pd.qcut(RFM["freq"],2,labels=["1","2"]) RFM["RFM"] = RFM["R_value"].str.cat(RFM["F_value"])
RFM.head()
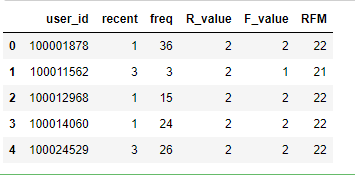
结论:通过RFM对用户进行分组后,可对不同组别的客户拟制实施不同的营销方式
总结
pv、uv分析得知:
日访问
- 访问量与访问用户间,表现为强相关性
- 双十二期间,pv与uv同时到达峰值
小时访问
- PV与UV呈相同的变化趋势,0-5点呈下降趋势,5-10逐渐增长,21时附近达到峰值,18点-0点为淘宝app用户活跃时间段
不同行为类型用户PV分析
我们能够看到在点击到加购物车和点击到收藏行为间的流失率基本稳定在97.7%左右;在10-15日期间从收藏到支付与从加购物车到支付的流失率较低。
消费行为分析
- 用户平均购买次数为13.5次,标准差19.6,具有一定波动性。中位数是8次,75分位数是17次,说明用户购买次数大部分都在20次以下。而最大值是809次,这差别有点大。
- 一般情况,消费类型的数据分布,大部分呈现的是长尾形态;绝大多数用户是低频次消费客群,但用户贡献率集中在少数分群里,符合二八法则。
ARPPU分析:
- 绝大部分消费客户每天消费次数在3次以内,双十二期间达到峰值
日ARPU情况分析
- 淘宝app活跃用户(有过操作行为的用户)在2014-11-18至2014-12-18这31天内,每天消费次数在0.5次上下波动,而在双十二期间到达峰值1,976,即平均每人双十二消费2次
付费情况
- 在每天活跃用户群中,具有消费行为的占24%左右,双十二到达50%
- 在同一小时段中,用户消费次数最多的为一次,75分位数为2次
复购情况
- 80%的淘宝用户复购复购时间在6天以内
- 复购率为:0.872
漏斗流失分析
- 从点击到收藏流失率为97.900
- 从点击到加购物车流失率为97.026
- 从加购物车到支付流失率为65.012
- 从加收藏到支付流失率为35.612
RFM
- 我们通过RFM将用户分为了多组,可对不同组别的客户拟制实施不同的营销方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号