酒店舆情分析

select * from hotel_comment_datas group by `评论ID`
特征工程
利用特征工程获取相应评论的内容,需将文本信息转为相应的数值
(1)获取评论内容,做相应的索引(对所有的评论做处理)
import pandas as pd sql = '''select * from hotel_comment_datas group by `评论ID`''' data = pd.read_sql(sql, conn) # 去除标签列所对应的缺失值,可以使用花式索引的方式,对于数据进行相应的清洗和替换 data = data[['评论内容', '评分']].replace('none', np.NaN) data = data.dropna() # 删除评论内容和用户评分为空的数据
(2)开始分词----cut
comment = data['评论内容'] # print(comment) # (2)开始分词----cut list_word = [] # 创建空列表用来接收相应的结果 for i in comment: a = list(jieba.cut(i)) # 按照列表的方式进行相应的分词 list_word.append(' '.join(a))

(3)对于分词后的文本进行相应的特征抽取,TF-TDF特征抽取。TF表示关键词的频率,TDF表示逆文档的频率,主要用来表示每个关键字在文档的重要性
# TF-IDF 特征抽取 from sklearn.feature_extraction.text import TfidfVectorizer tf = TfidfVectorizer() # 调用TF-TDF分词算法,将文本转化为频率 data1 = tf.fit_transform(list_word) # 先拟合,再转换,得出一个稀疏矩阵
对因变量(住客评分)进行相应的分类

分类代码
bq = [] for i in data['评分']: # 初始的分类级别 if float(i) <= 0: bq.append(0) elif 0 < float(i) <= 1: bq.append(1) elif 1 < float(i) <= 2: bq.append(2) elif 2 < float(i) <= 3: bq.append(3) elif 3 < float(i) <= 4: bq.append(4) else: bq.append(5)
划分数据集
(1)找到相对应的特征(自变量)x,标签y(因变量)
x = data2
y = bq
(2)划分相应的训练集和测试集,其中训练集为80%,测试集为20%
# 划分数据集 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
(3)对数据进行标准化(将自变量的数据进行相应的标准化处理,可以使得某一个特征不会对总的结果产生较大影响)
# 对数据进行标准化处理 from sklearn.preprocessing import StandardScaler ss = StandardScaler() # print(ss.fit_transform(x_train)) # 标准化后,有的值为正,有的值为负 x_train = ss.fit_transform(x_train) x_test = ss.fit_transform(x_test)
数学建模-朴素贝叶斯分类算法
利用贝叶斯分类的目的:依据对应的评论内容给这个结果进行预测打分和客户实际打分的区别
- 预测打分可以将客户评价分级,(分级的结果acc准确率要求比较高)
- 进一步:分级后,将不同等级的用户,单独提取出来,按照预测的打分结果,产生新的一列
- 按照预测评分结果,按照预测结果的不同等级,将整个数据划分为三个级别,需进一步考虑
- 对于不同级别的顾客,可以考虑做相应的评价画像
- 同样可以考虑做顾客画像
代码实现
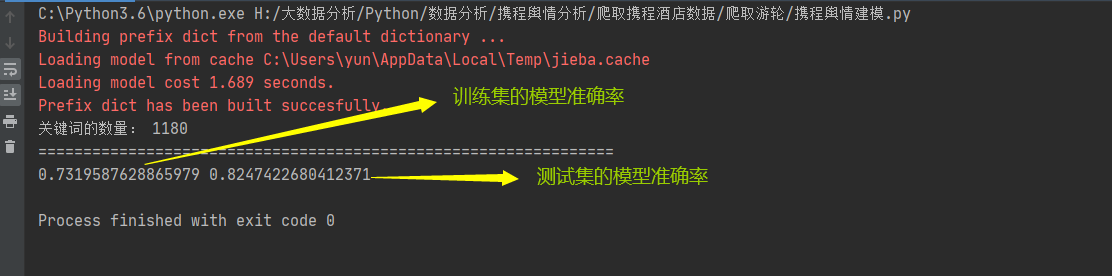
from sklearn.naive_bayes import GaussianNB # 用于处理有正有负的数据 nb = GaussianNB() # 因为稀疏矩阵标准化后的值很可能是负值 nb.fit(x_train, y_train) # 拟合相应的训练集 x_predict = nb.predict(x_test) # 放入相应的测试集进行分类 t_predict = nb.predict(x_train) # 放入相应的训练集进行分类 score_1 = nb.score(x_train, y_train) # 使用对应的训练集测试一下评估的ACC score_2 = nb.score(x_test, y_test) print(score_1, score_2)
模型的准确性
模型调优
增加相应的特征(如评论的推荐数)
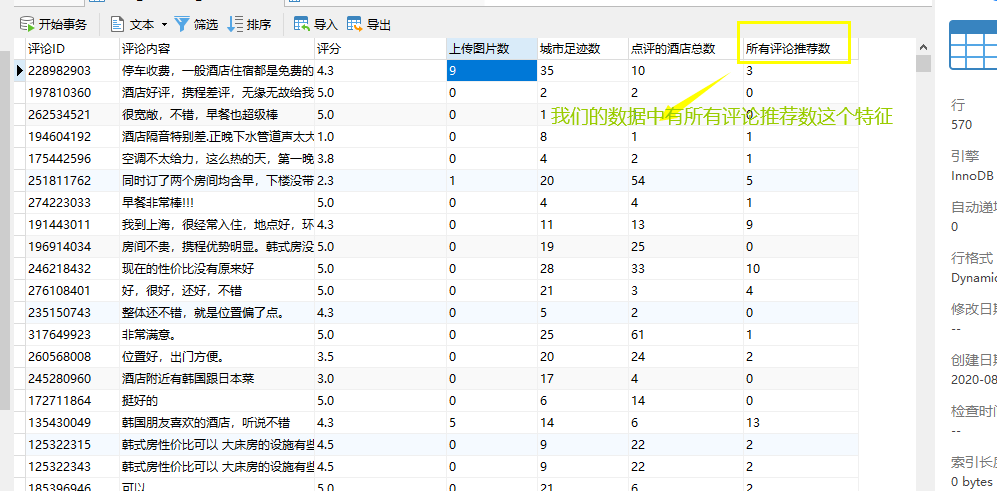
这个特征,所有评论特征数,我们可以通过筛选所有评论特征数来提高我们的数据质量(数据的可靠性),进而提高我们的数学模型的ACC(准确率)
# 在sql部分重新筛选所有评论推荐数大于1的数据 sql = '''select * from hotel_comment_datas where `所有评论推荐数` >1 group by `评论ID`'''

与未使用所有评论推荐数的特征的模型准确率,相比,训练集的ACC提高了将近7个百分点,测试集的ACC降低了6个百分点
可以考虑分类级别过多
我们是对酒店进行分类,一般我们对酒店的评价是差、一般、好;但是我们之前是划分了5个等级,我们考虑一下是否分类过度,导致模型ACC过低?尝试降低分类数
缩小分类级别 for i in data['评分']: if float(i) <= 2: bq.append(0) elif 2 < float(i) <= 4: bq.append(1) else: bq.append(2)

相比与上图的数学模型ACC而言,本次的训练集数学模型ACC提高了近1个百分点 ,测试集数学模型ACC基本一致
修改训练集(70%)与测试集(30%)的占比
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)

相比上图的数学模型ACC而言,本次训练集的数学模型ACC提高近2个百分点,测试集的数学模型ACC提高近0.8个百分点


增加特征,重新筛选数据
select * from hotel_comment_datas where `所有评论推荐数` >1 and `城市足迹数` >1 group by `评论ID`

此时我们发现,我们的数学模型的ACC非常好
酒店数学建模代码


# --encoding:utf-8-- # Yun import numpy as np import pandas as pd import sklearn from pprint import pprint # TF-IDF 特征抽取 from sklearn.feature_extraction.text import TfidfVectorizer # 对数据进行标准化处理 from sklearn.preprocessing import StandardScaler # 引入朴素贝叶斯算法 from sklearn.naive_bayes import GaussianNB # 用于处理有正有负的数据 from sklearn.naive_bayes import MultinomialNB # 用于处理有正数的数据 # 划分数据集 from sklearn.model_selection import train_test_split # 对所有的评论内容分开 import jieba import pymysql config = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'password': '123456', 'db': 'xiecheng_cruise', 'charset': 'utf8' } # 步骤一:连接数据库并进行数据清洗 # 连接数据库 conn = pymysql.connect(**config) # 获取MSC地中海邮轮·地中海辉煌号5天4晚福冈游轮旅游的评论 # sql = '''select * from cruise_comment where cruise_name="MSC地中海邮轮·地中海辉煌号5天4晚福冈" group by comment_id''' sql = '''select * from hotel_comment_datas where `所有评论推荐数` >1 and `城市足迹数` >1 group by `评论ID`''' data = pd.read_sql(sql, conn) # 去除标签列所对应的缺失值,可以使用花式索引的方式,对于数据进行相应的清洗和替换 data = data[['评论内容', '评分']].replace('none', np.NaN) data = data.dropna() # 删除评论内容和用户评分为空的数据 # 步骤二:对因变量进行相应的分类 # 需要对标签进行相应的分类 bq = [] # for i in data['评分']: # 初始的分类级别 # if float(i) <= 0: # bq.append(0) # elif 0 < float(i) <= 1: # bq.append(1) # elif 1 < float(i) <= 2: # bq.append(2) # elif 2 < float(i) <= 3: # bq.append(3) # elif 3 < float(i) <= 4: # bq.append(4) # # else: # bq.append(5) # 降低分类级别 for i in data['评分']: if float(i) <= 2: bq.append(0) elif 2 < float(i) <= 4: bq.append(1) else: bq.append(2) # print(bq) # 步骤三:利用特征工程获取相应评论的内容,需将文本信息转为相应的数值 # (1)获取评论内容,做相应的索引(对所有的评论做处理) comment = data['评论内容'] # print(comment) # (2)开始分词----cut list_word = [] # 创建空列表用来接收相应的结果 for i in comment: a = list(jieba.cut(i)) # 按照列表的方式进行相应的分词 list_word.append(' '.join(a)) # print(list_word) # (3)对于分词后的文本进行相应的特征抽取,TF-TDF特征抽取。TF表示关键词的频率, # TDF表示逆文档的频率,主要用来表示每个关键字在文档的重要性 tf = TfidfVectorizer() # 调用TF-TDF分词算法,将文本转化为频率 data1 = tf.fit_transform(list_word) # 先拟合,再转换,得出一个稀疏矩阵 # print(data1) print('关键词的数量:', len(tf.get_feature_names())) # 查看一下分词之后关键词的数量 data2 = data1.toarray() # 将产生的稀疏矩阵转化为相应的数组 # pprint(data2) # 步骤四:划分数据集 # 需将数据集进行相应的划分,train test # (1)找到相对应的特征(自变量)x,标签y(因变量) x = data2 y = bq # (2)划分相应的训练集和测试集,其中训练集为80%,测试集为20% # 为了演示结果一致,可以考虑使用随机种子设置0 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0) # print(x_train, y_train) # (3)对数据进行标准化 ss = StandardScaler() # print(ss.fit_transform(x_train)) # 标准化后,有的值为正,有的值为负 x_train = ss.fit_transform(x_train) x_test = ss.fit_transform(x_test) # 步骤五:正式引入贝叶斯算法,进行相应的分类-------朴素贝叶斯算法原理 # 利用贝叶斯分类的目的:依据对应的评论内容给这个结果进行预测打分和客户实际打分的区别。 # 预测打分可以将客户评价分级,(分级的结果acc准确率要求比较高) # 进一步:分级后,将不同等级的用户,单独提取出来,按照预测的打分结果,产生新的一列 # 预测评分结果,按照预测结果的不同等级,将整个数据划分为三个级别,进一步考虑:对于不同级别的顾客 # 做相应的评价画像(同样可以考虑做顾客画像) nb = GaussianNB() # 因为稀疏矩阵标准化后的值很可能是负值 nb.fit(x_train, y_train) # 拟合相应的训练集 x_predict = nb.predict(x_test) # 放入相应的测试集进行分类 t_predict = nb.predict(x_train) # 放入相应的训练集进行分类 # print(x_predict) print('================================================================') # print(t_predict) score_1 = nb.score(x_train, y_train) # 使用对应的训练集测试一下评估的ACC score_2 = nb.score(x_test, y_test) print(score_1, score_2) # 步骤六:模型优化,增加相应的特征---我们在抽取数据的时候考虑进一步筛选数据 # 在数据筛选的时候考虑多个字段,在sql部分直接处理 # 可以考虑分类的级别过多,减少分类的个数,在对应的标签处处理,发现对于总的评论而言 # 模型的准确率提升,并且,发现评论的推荐数,这个字段非常有用,可以提高整个模型的准确率(ACC)
酒店所有评论的词云图

酒店差评词云图

词云绘制代码
# --encoding:utf-8-- # Yun import numpy as np import pandas as pd import pymysql from jieba import analyse # 运用此模块做相对应的分词处理----提取关键词 from PIL import Image # 处理图片 from matplotlib import pyplot as plt from wordcloud import WordCloud, ImageColorGenerator config = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'password': '123456', 'db': 'xiecheng_cruise', 'charset': 'utf8' } # 步骤一:连接数据库并进行数据清洗 # 连接数据库 conn = pymysql.connect(**config) # 依据贝叶斯分类方法提取的数据方式是一样的 sql = '''select * from hotel_bad_comment_datas where 所有评论推荐数>1 and 酒店ID='662464' GROUP BY 评论ID''' # sql = '''select * from hotel_comment_datas where `所有评论推荐数` >1 and `城市足迹数` >1 group by `评论ID`''' data = pd.read_sql(sql, conn) print(data) # 清理none值,否则会成为高频词汇 data1 = data['评论内容'].replace('none', np.NaN).dropna() # 删除评论内容为空的数据 # 处理数据,生成关键词的占比权重,此时的data1是Series数据 # 分词是对于整个数据而言 data2 = data1.to_list() # 将Series数据转化为列表,为了做下一步的拼接 data3 = ''.join(data2) # print(data3) # 提取对应的关键词,并查看这些关键词对应的权重 result = analyse.textrank(data3, topK=50, withWeight=True) print(result) dict_1 = {} for i in result: dict_1[i[0]] = i[1] # print(dict_1) # 生成对应的词云 # 利用PIL的Image打开背景图片,并且进行相应的参数化 img = Image.open('timg2.jpg') graph = np.array(img) # 把img的参数给到graph生成相应的词云 # WordCloud默认不支持中文,加载对应的中文黑色字体库,一般在电脑的C盘 fonts # mask以传递过来的数据绘制词云 wc = WordCloud(font_path='C:\Windows\Fonts\simhei.ttf', background_color='white', max_words=300, mask=graph) # 将字典的文本生成相对应的词云 wc.generate_from_frequencies(dict_1) # 进一步,基于背景颜色,设置字体的颜色 image_color = ImageColorGenerator(graph) # 显示对应的图片 plt.imshow(wc) # 显示对应的词云图 plt.axis('off') # 关闭图像对应的坐标 plt.show() # 显示对应的窗口 # 将生成的图片保存 wc.to_file('H:\大数据分析\携程舆情分析\酒店差评词云.jpg') # 考虑到这是多个酒店的差评的词云,考虑将单一酒店的词云图提取出来, # 在sql数据筛选阶段修改筛选条件 # 例如通过酒店ID筛选每个酒店的差论词云
Great works are not done by strength, but by persistence!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号