


java8 新特性Stream流的应用
作为一个合格的程序员,如何让代码更简洁明了,提升编码速度尼。
今天跟着我一起来学习下java 8 stream 流的应用吧。
废话不多说,直入正题。
考虑以下业务场景,有四个人员信息,我们需要根据性别统计人员的姓名。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | package com;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;public class Test { public static void main(String[] args) { List<Map<String, String>> list = new ArrayList<>(); Map<String, String> map = new HashMap<>(); map.put("userName", "张三"); map.put("age", "18"); map.put("sex", "男"); list.add(map); Map<String, String> map1 = new HashMap<>(); map1.put("userName", "李四"); map1.put("age", "20"); map1.put("sex", "女"); list.add(map1); Map<String, String> map2 = new HashMap<>(); map2.put("userName", "王五"); map2.put("age", "15"); map2.put("sex", "女"); list.add(map2); Map<String, String> map3 = new HashMap<>(); map3.put("userName", "若风"); map3.put("age", "23"); map3.put("sex", "男"); list.add(map3); //现在我们要根据性别统计人员的姓名 //初级写法 StringBuilder stringBuilder1 = new StringBuilder(); StringBuilder stringBuilder2 = new StringBuilder(); for (Map<String, String> item : list) { //指向当前下标的map System.out.println("item: " + item); if (item.get("sex").equals("男")) { //存性别为男的人员名称,以逗号隔开 stringBuilder1.append(item.get("userName")).append(","); } else { //存性别为女的人员名称,以逗号隔开 stringBuilder2.append(item.get("userName")).append(","); } } //去掉最后一个逗号 String userName_nan = stringBuilder1.deleteCharAt(stringBuilder1.length() - 1).toString(); String userName_nv = stringBuilder2.deleteCharAt(stringBuilder2.length() - 1).toString(); System.out.println("userName_nan: " + userName_nan); System.out.println("userName_nv: " + userName_nv); }} |
打印记录如下:
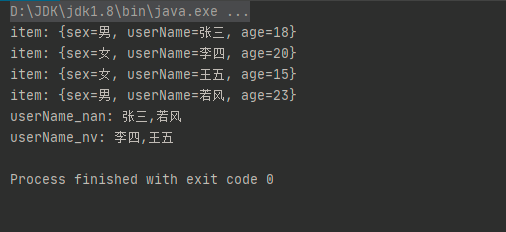
是不是感觉代码写的不怎么优雅,那么我们开始换个姿势,用java8 Stream 流的方式来操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | package com;import org.apache.commons.lang.StringUtils;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;public class Test { public static void main(String[] args) { List<Map<String, String>> list = new ArrayList<>(); Map<String, String> map = new HashMap<>(); map.put("userName", "张三"); map.put("age", "18"); map.put("sex", "男"); list.add(map); Map<String, String> map1 = new HashMap<>(); map1.put("userName", "李四"); map1.put("age", "20"); map1.put("sex", "女"); list.add(map1); Map<String, String> map2 = new HashMap<>(); map2.put("userName", "王五"); map2.put("age", "15"); map2.put("sex", "女"); list.add(map2); Map<String, String> map3 = new HashMap<>(); map3.put("userName", "若风"); map3.put("age", "23"); map3.put("sex", "男"); list.add(map3); //现在我们要根据性别统计人员的姓名 //初级写法// StringBuilder stringBuilder1 = new StringBuilder();// StringBuilder stringBuilder2 = new StringBuilder();// for (Map<String, String> item : list) {// //指向当前下标的map// System.out.println("item: " + item);// if (item.get("sex").equals("男")) {// //存性别为男的人员名称,以逗号隔开// stringBuilder1.append(item.get("userName")).append(",");// } else {// //存性别为女的人员名称,以逗号隔开// stringBuilder2.append(item.get("userName")).append(",");// }// }// //去掉最后一个逗号// String userName_nan = stringBuilder1.deleteCharAt(stringBuilder1.length() - 1).toString();// String userName_nv = stringBuilder2.deleteCharAt(stringBuilder2.length() - 1).toString();// System.out.println("userName_nan: " + userName_nan);// System.out.println("userName_nv: " + userName_nv); //java8 stream流的写法 //先定义一个Map 用来存储我们的人员姓名 Map<String, String> userNameMap = new HashMap<>(4); //装逼开始 // list.stream().map(v1 -> { //map 可以理解为new 一个新的对象,复制原来list的数据copy 到一个新的List ,用map对数据进行修改操作时,不会改变原来的对象。需要返回值!!! //v1指向当前下标的map对象 System.out.println("v1: " + v1); //定义一个新的map 用来存储人员的姓名和性别 Map<String, String> data = new HashMap<>(); map.put("userName", v1.get("userName")); map.put("sex", v1.get("sex")); return map; }).reduce(userNameMap, (a, b) -> { //a 可以理解为上一次循环的返回结果 //b 当前的循环对象 //取出当前循环的人员姓名 String thisUserName = b.get("userName"); //取出当前循环的人员性别 String thisSex = b.get("sex"); if (thisSex.equals("男")) { //取上一次循环的返回结果,第一次循环,是没有值的,第二次循环时,取得是第一次循环的返回结果,以此类推。 String val = a.get("newMenUserName"); System.out.println("val: " + val); //第一次循环时val 是没有值的,我们赋值一个空的字符串, // 第二次循环时,把第一次循环的返回的newUserName的值取出来,加上逗号,拼接当前下标的人员姓名 String newUserName = (StringUtils.isBlank(val) ? StringUtils.EMPTY : val + ",") + thisUserName; //把拼接好的人员姓名添加到map 中 System.out.println("newUserName: " + newUserName); a.put("newMenUserName", newUserName); } else { //取上一次循环的返回结果,第一次循环,是没有值的,第二次循环时,取得是第一次循环的返回结果,以此类推。 String val = a.get("newWomenUserName"); System.out.println("val: " + val); //第一次循环时val 是没有值的,我们赋值一个空的字符串, // 第二次循环时,把第一次循环的返回的newUserName的值取出来,加上逗号,拼接当前下标的人员姓名 String newUserName = (StringUtils.isBlank(val) ? StringUtils.EMPTY : val + ",") + thisUserName; System.out.println("newUserName: " + newUserName); //把拼接好的人员姓名添加到map 中 a.put("newWomenUserName", newUserName); } //返回当前循环的map return a; }); System.out.println("userNameMap: " + userNameMap); System.out.println("userName_nan: " + userNameMap.get("newMenUserName")); System.out.println("userName_nv: " + userNameMap.get("newWomenUserName")); }} |
打印的值如下:
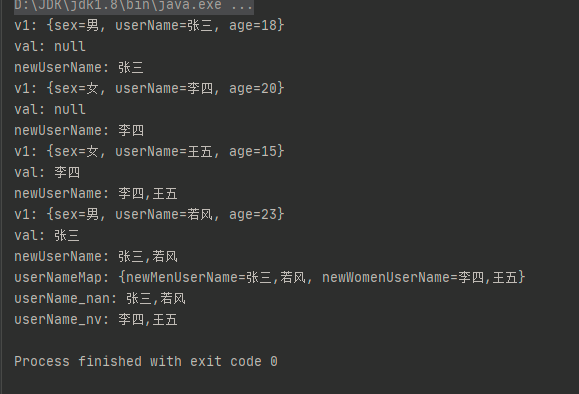
场景二、取两个List 的交集

package com; import java.util.ArrayList; import java.util.List; import java.util.stream.Collectors; public class Test { public static void main(String[] args) { // 业务场景2:取出两个List 的数值相同的元素(交集) List<Integer> list1=new ArrayList<>(); list1.add(1); list1.add(2); list1.add(3); list1.add(4); List<Integer> list2=new ArrayList<>(); list2.add(2); list2.add(4); //交集 List<Integer> list3=new ArrayList<>(); //初级写法 for(Integer item:list1){ if(list2.contains(item)){ list3.add(item); } } System.out.println("for循环的结果"); System.out.println("list3: "+list3); System.out.println("------------------------------------------------------------"); //stream 流的写法 //v1 表示当前下标的对象 //filter 过滤掉结果为false 的数据 list3=list1.stream().filter(v1->list2.contains(v1)).collect(Collectors.toList()); System.out.println("stream循环的结果"); System.out.println("list3: "+list3); //list 本身的方法 System.out.println("------------------------------------------------------------"); System.out.println("old 数据,list1:"+list1); System.out.println("old 数据,list2:"+list2); list1.retainAll(list2); System.out.println("new 数据,list1"+list1); System.out.println("new 数据,list2"+list2); } }
打印结果:
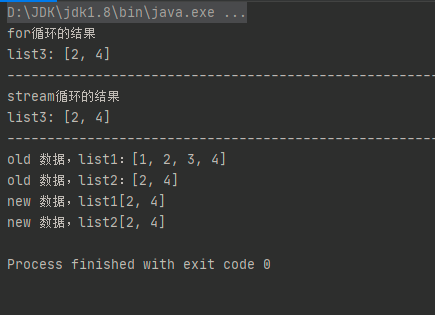
场景三、对一个List 排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | package com;import java.util.*;import java.util.stream.Collectors;public class Test { public static void main(String[] args) {// 业务场景3:对List 排序 List<Map<String, String>> list = new ArrayList<>(); Map<String, String> map = new HashMap<>(); map.put("userName", "张三"); map.put("age", "18"); map.put("sex", "男"); list.add(map); Map<String, String> map1 = new HashMap<>(); map1.put("userName", "李四"); map1.put("age", "20"); map1.put("sex", "女"); list.add(map1); Map<String, String> map2 = new HashMap<>(); map2.put("userName", "王五"); map2.put("age", "15"); map2.put("sex", "女"); list.add(map2); Map<String, String> map3 = new HashMap<>(); map3.put("userName", "若风"); map3.put("age", "23"); map3.put("sex", "男"); list.add(map3); //stream 流的写法 System.out.println("------------------------排序前--------------------------------"); System.out.println("排序前,List :"+list); //sorted stream排序,这里我们根据年龄和姓名进行排序 //Test::age Java 8 中我们可以通过 `::` 关键字来访问类的构造方法,对象方法,静态方法。 //装逼开始 List<Map<String, String>> list2=list.stream().sorted(Comparator.comparing(Test::age).thenComparing(Comparator.comparing(Test::userName))).collect(Collectors.toList()); System.out.println(); System.out.println("------------------------排序后--------------------------------"); System.out.println("排序后,list2 :"+list2); } private static String userName(Map<String,String> map){ return map.get("userName"); } private static Integer age(Map<String,String> map){ return Integer.parseInt(map.get("age")); }} |
打印结果:

总结:
1、 Stream流不是一种数据结构,不保存数据,它只是在原数据集上定义了一组操作。
2、这些操作是惰性的,即每当访问到流中的一个元素,才会在此元素上执行这一系列操作。
3、Stream不保存数据,故每个Stream流只能使用一次。
2、这些操作是惰性的,即每当访问到流中的一个元素,才会在此元素上执行这一系列操作。
3、Stream不保存数据,故每个Stream流只能使用一次。
Stream流可以分成两部分:Intermediate(中间操作)和Terminal(终止操作)。中间操作的返回结果都是Stream,故可以多个中间操作叠加;终止操作用于返回我们最终需要的数据,只能有一个终止操作!!!
一、stream流的Intermediate方法(中间操作)
1、filter(Predicate)
将结果为false的元素过滤掉,不会改变原来对象的数据,需要显示指定返回值!!!
2、map(fun)
把对象copy到一个新的对象中,遍历新的对象,对数据进行修改不会改变原来对象的数据,需要显示指定返回值!!!
3、flatMap(fun)
若元素是流,将流摊平为正常元素,再进行元素转换
4、limit(n)
保留前n个元素
5、 skip(n)
跳过前n个元素
6、distinct()
剔除重复元素
7、sorted(Comparator)
将流元素按Comparator排序
8、peek(fun)
流不变,但会把每个元素传入fun执行,可以用作调试
9、forEach()
遍历当前对象,对数据进行修改时,会改变对象的数据,不需要显示指定返回值!!!(注意和map的区别)
1、filter(Predicate)
将结果为false的元素过滤掉,不会改变原来对象的数据,需要显示指定返回值!!!
2、map(fun)
把对象copy到一个新的对象中,遍历新的对象,对数据进行修改不会改变原来对象的数据,需要显示指定返回值!!!
3、flatMap(fun)
若元素是流,将流摊平为正常元素,再进行元素转换
4、limit(n)
保留前n个元素
5、 skip(n)
跳过前n个元素
6、distinct()
剔除重复元素
7、sorted(Comparator)
将流元素按Comparator排序
8、peek(fun)
流不变,但会把每个元素传入fun执行,可以用作调试
9、forEach()
遍历当前对象,对数据进行修改时,会改变对象的数据,不需要显示指定返回值!!!(注意和map的区别)
二、stream流的Terminal方法(终结操作)
约简操作
约简操作
1、max(Comparator)
取最大值
2、min(Comparator)
取最小值
3、 count()
去和
4、findFirst()
返回第一个元素
5、 findAny()
返回任意元素
6、anyMatch(Predicate)
任意元素匹配时返回true
7、allMatch(Predicate)
所有元素匹配时返回true
8、noneMatch(Predicate)
没有元素匹配时返回true
9、reduce(fun)
从流中计算某个值,接受一个二元函数作为累积器,从前两个元素开始持续应用它,累积器的中间结果作为第一个参数,流元素作为第二个参数
10、 reduce(a, fun)
a为幺元值,作为累积器的起点
11、reduce(a, fun1, fun2)
与二元变形类似,并发操作中,当累积器的第一个参数与第二个参数都为流元素类型时,可以对各个中间结果也应用累积器进行合并,但是当累积器的第一个参数不是流元素类型而是类型T的时候,各个中间结果也为类型T,需要fun2来将各个中间结果进行合并(参考场景一)
三、stream流的收集操作:
1、Collectors.toList()
取最大值
2、min(Comparator)
取最小值
3、 count()
去和
4、findFirst()
返回第一个元素
5、 findAny()
返回任意元素
6、anyMatch(Predicate)
任意元素匹配时返回true
7、allMatch(Predicate)
所有元素匹配时返回true
8、noneMatch(Predicate)
没有元素匹配时返回true
9、reduce(fun)
从流中计算某个值,接受一个二元函数作为累积器,从前两个元素开始持续应用它,累积器的中间结果作为第一个参数,流元素作为第二个参数
10、 reduce(a, fun)
a为幺元值,作为累积器的起点
11、reduce(a, fun1, fun2)
与二元变形类似,并发操作中,当累积器的第一个参数与第二个参数都为流元素类型时,可以对各个中间结果也应用累积器进行合并,但是当累积器的第一个参数不是流元素类型而是类型T的时候,各个中间结果也为类型T,需要fun2来将各个中间结果进行合并(参考场景一)
三、stream流的收集操作:
1、Collectors.toList()
返回一个List
2、Collectors.toSet()
2、Collectors.toSet()
返回一个集合
3、Collectors.toCollection(集合的构造器引用)
4、Collectors.joining()、Collectors.joining(delimiter)、Collectors.joining(delimiter、prefix、suffix)
字符串元素连接
5、Collectors.summarizingInt/Long/Double(ToInt/Long/DoubleFunction)
产生Int/Long/DoubleSummaryStatistics对象,它有getCount、getSum、getMax、getMin方法,注意在没有元素时,getMax和getMin返回Integer/Long/Double.MAX/MIN_VALUE
6、Collectors.toMap(fun1, fun2)/toConcurrentMap
两个fun用来产生键和值,若值为元素本身,则fun2为Function.identity()
7、Collectors.toMap(fun1, fun2, fun3)/toConcurrentMap
fun3用于解决键冲突,例如(oldValue, newValue) -> oldValue,有冲突时保留原值
8、Collectors.toMap(fun1, fun2, fun3, fun4)/toConcurrentMap
默认返回HashMap或ConcurrentHashMap,fun4可以指定返回的Map类型,为对应的构造器引元
9、Collectors.groupingBy(fun)/groupingByConcurrent(fun)
fun是分类函数,生成Map,键是fun函数结果,值是具有相同fun函数结果元素的列表
10、Collectors.partitioningBy(fun)
键是true/false,当fun是断言函数时用此方法,比groupingBy(fun)更高效
11、Collectors.groupingBy(fun1, fun2)
fun2为下游收集器,可以将列表转换成其他形式,例如toSet()、counting()、summingInt/Long/Double(fun)、maxBy(Comparator)、minBy(Comparator)、mapping(fun1, fun2)(fun1为转换函数,fun2为下游收集器)
参考: https://blog.csdn.net/lixiaobuaa/article/details/81099838
3、Collectors.toCollection(集合的构造器引用)
4、Collectors.joining()、Collectors.joining(delimiter)、Collectors.joining(delimiter、prefix、suffix)
字符串元素连接
5、Collectors.summarizingInt/Long/Double(ToInt/Long/DoubleFunction)
产生Int/Long/DoubleSummaryStatistics对象,它有getCount、getSum、getMax、getMin方法,注意在没有元素时,getMax和getMin返回Integer/Long/Double.MAX/MIN_VALUE
6、Collectors.toMap(fun1, fun2)/toConcurrentMap
两个fun用来产生键和值,若值为元素本身,则fun2为Function.identity()
7、Collectors.toMap(fun1, fun2, fun3)/toConcurrentMap
fun3用于解决键冲突,例如(oldValue, newValue) -> oldValue,有冲突时保留原值
8、Collectors.toMap(fun1, fun2, fun3, fun4)/toConcurrentMap
默认返回HashMap或ConcurrentHashMap,fun4可以指定返回的Map类型,为对应的构造器引元
9、Collectors.groupingBy(fun)/groupingByConcurrent(fun)
fun是分类函数,生成Map,键是fun函数结果,值是具有相同fun函数结果元素的列表
10、Collectors.partitioningBy(fun)
键是true/false,当fun是断言函数时用此方法,比groupingBy(fun)更高效
11、Collectors.groupingBy(fun1, fun2)
fun2为下游收集器,可以将列表转换成其他形式,例如toSet()、counting()、summingInt/Long/Double(fun)、maxBy(Comparator)、minBy(Comparator)、mapping(fun1, fun2)(fun1为转换函数,fun2为下游收集器)
参考: https://blog.csdn.net/lixiaobuaa/article/details/81099838
本博客仅作为学习参考


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决