

第十四章 正则
# 第十四章 正则
## 一、正则表达式
### 1、什么是正则表达式
一组特殊符号组成的表达式,它能帮助你方便的检查一个字符串是否与某种模式匹配。该应用场景生活中随处可见。Python 自1.5版本起增加了re 模块,re 模块为Python的内置模块,Python程序中通过这个模块来使用正则表达式,re模块拥有全部的正则表达式功能。
### 2、re模块特点
- re模块是python独有的
- 正则表达式所有编程语言都可以使用
- re模块、正则表达式是对字符串进行操作
### 2、正则表达式应用场景
- 1.用于从字符串中匹配满足某种规则的内容,多数用于爬虫应用程序
- 2.判断字符串串内容是否满足某种规则,多用于严重用户输入。例如密码是否规范,手机号是否正确等
### 3、元字符
正则是一堆特殊符号组成的,我们主要学习的就是这些特殊符号,下面列举一些常见的元字符:
- .(匹配除换行符以外的任意字符)
- \w(匹配字母或数字或下划线)
- \s(匹配任意的空白符)
- \d(匹配数字)
- \n(匹配一个换行符)
- \b(字母数字与非字母数字的边界)
- ^(匹配字符串的开始)
- $(匹配字符串的结尾)
- \W(匹配非字母或数字或下划线)
- \D(匹配非数字)
- \S(匹配非空白符)
- a|b(匹配字符a或字符b)
- ()(匹配括号内的表达式,也表示一个组)
- [...](匹配字符组中的字符)
- [^...]匹配除了字符组中字符的所有字符
### 4、量词
正则表达式匹配的规则可以有一次,还可以多次。
- *(重复零次或更多次)
- +(重复一次或更多次)
- ?(重复零次或一次)
- {n}(重复n次)
- {n,}(重复n次或更多次)
- {n,m}(重复n到m次)
### 5、简单的元字符匹配案例
我们知道很多网站需要填写邮箱,如果你填的邮箱格式出错了,会有温馨提示,这可以使用正则进行判断,现在,我们就通过正则来判断用户提交的邮箱格式是否正确。

执行该代码,结果为:
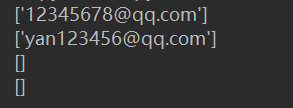
在第一行出,先导入re模块;在第三行处,re.findall()是re模块常用的匹配方法之一,下一小节详细说明。
看这个正则表达式:r'^[a-zA-Z0-9]+@[a-zA-Z0-9]+\.com$','12345678@qq.com',[a-zA-Z-0-9]表示所有大小写字母和0-9字母都可以匹配,^和$分别表示匹配字符串的开始和结束位置。
r'':表示原生字符串。与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
结合本案例的代码,如果不加r和\,.会被是被为正则的元字符,所以加上r和\就能让原生.可以正常表示出来。
## 二、re的常用方法
将正则表达式模式编译为正则表达式对象,可使用match(),search()以及下面所述的其他方法将其用于匹配。
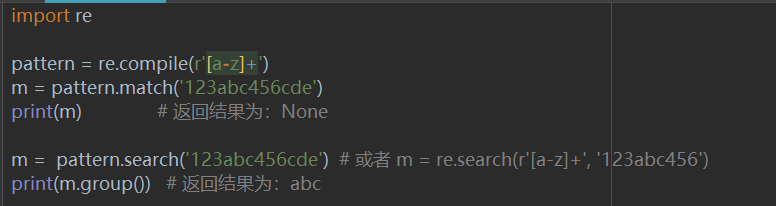
### 1、re.match
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。如果字符串开头的零个或多个字符与正则表达式模式匹配,则返回相应的匹配对象。如果字符串与模式不匹配,则返回None。
- re.match(pattern, string, flags=0)
- pattern : 正则中的模式字符串。
- string : 要被查找替换的原始字符串。
- flags:默认为0,表示不进行特殊指定,比如忽略大小写,指定语言等
```
s=re.match('ab','abc123abde').group()
print(s)
```
执行该代码,结果为:ab。re.match规定从起始位置匹配对象,所以第二个ab是不会被匹配到的。通过group方法获取匹配的内容。
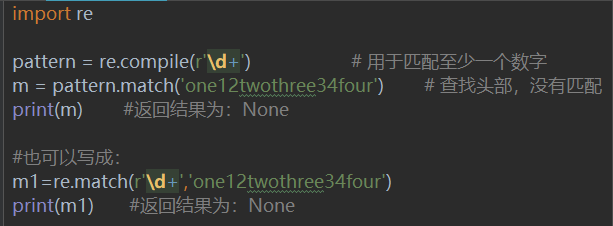
### 2、re.search
不同于match方法的从头开始匹配,search方法用于在字符串中的进行查找(从左向右进行查找),只要找到一个匹配结果,就返回 Match 对象,若没有则返回None。
- re.search(pattern, string, flags=0)
### 3、re.sub
返回通过用替换repl替换字符串中最左边的不重叠模式所获得的字符串。如果找不到该模式, 则返回的字符串不变。 repl可以是字符串或函数;如果是字符串,则处理其中的任何反斜杠转义。即,将其转换为单个换行符,将其转换为回车,依此类推。count参数表示将匹配到的内容进行替换的次数。
- re.sub(pattern, repl, string, count=0, flags=0)
- repl : 替换的字符串,也可为一个函数。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。

执行该代码,结果为:

### 4、re.compile
将正则表达式模式编译为正则表达式对象,可使用match(),search()以及下面所述的其他方法将其用于匹配。
- re.compile(pattern[, flags])
### 5、re.split
通过出现模式来拆分字符串。如果在pattern中使用了捕获括号,那么模式中所有组的文本也将作为结果列表的一部分返回。如果maxsplit不为零,则最多会发生maxsplit分割,并将字符串的其余部分作为列表的最后一个元素返回。
- re.split(pattern, string[, maxsplit=0, flags=0])
- maxsplit:分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。

执行该代码,结果为:['abc', 'de', 'fgh', 'ij']。
### 6、re.findall
以string列表形式返回string中pattern的所有非重叠匹配项。从左到右扫描该字符串,并以找到的顺序返回匹配项。如果该模式中存在一个或多个组,则返回一个组列表;否则,返回一个列表。如果模式包含多个组,则这将是一个元组列表。空匹配项包含在结果中。
- re.findall(pattern,string,flags = 0 )
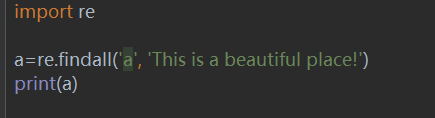
执行该代码,结果为:['a', 'a', 'a']。
## 三、贪婪匹配和非贪婪匹配
### 1、贪婪匹配
默认情况下,正则表达式将进行贪婪匹配。所谓“贪婪”,其实就是在多种长度的匹配字符串中,选择较长的那一个。例如,如下正则表达式本意是选出人物所说的话,但是却由于“贪婪”特性,出现了匹配不当:
```
>>> sentence = """You said "why?" and I say "I don't know"."""
>>> re.findall(r'"(.*)"', sentence)
['why?" and I say "I don\'t know']
```
### 2、非贪婪匹配
当我们期望正则表达式“非贪婪”地进行匹配时,需要通过语法明确说明:
- {2,5}? 捕获2-5次,但是优先次数少的匹配
在这里,问号?可能会有些让人犯晕,因为之前他已经有了自己的含义:前面的匹配出现0次或1次。其实,只要记住,当问号出现在表现不定次数的正则表达式部分之后时,就表示非贪婪匹配。
```
>>> sentence = """You said "why?" and I say "I don't know"."""
>>> re.findall(r'"(.*?)"', sentence)
['why?', "I don't know"]
>>> re.findall('hi*?', 'hiiiii')
['h']
>>> re.findall('hi{2,}?', 'hiiiii')
['hii']
>>> re.findall('hi{1,3}?', 'hiiiii')
['hi']
```
## 四、课堂练习
#### 1、使用正则提取出字符串中的单词(s="""i love you not because of who 234 you are, 234 but 3234ser because of who i am when i am with you""")。
#### 2、使用正则表达式匹配合法的邮件地址(s="""xiasd@163.com, sdlfkj@.com sdflkj@180.comsolodfdsf@123.comsdlfjxiaori@139.comsaldkfj.comoisdfo@.sodf.com.com""")。
## 五、上一节课堂练习答案
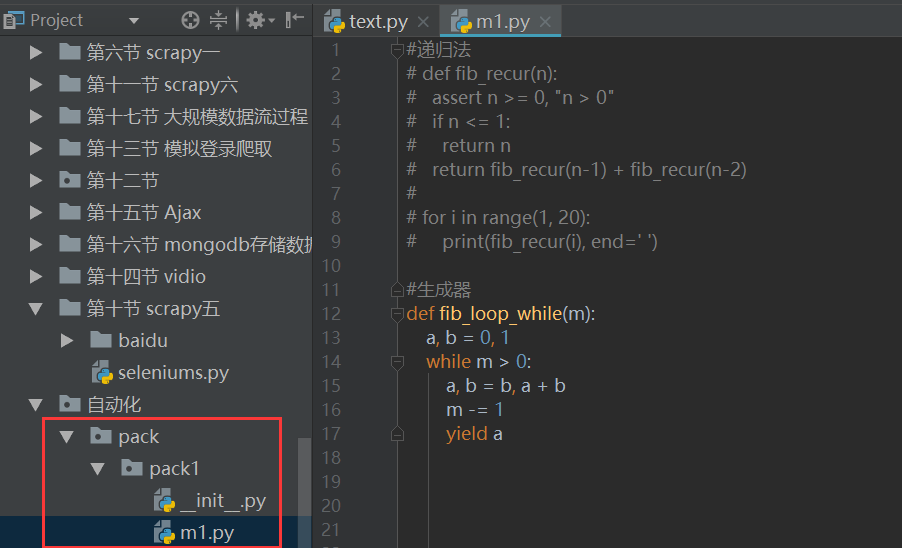
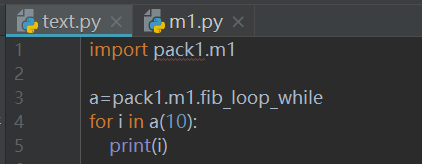
#### 1、在一个模块中定义一个生成器,这个生成器可以生成斐波拉契数列,在另一个模块中使用这个生成器,得到斐波拉契数列。斐波拉契数列:数列中每一个数的值都等于前两个数相加的值。[1,1,2,3,5,8,13,21,34,55,....]
如有问题请留言,谢谢!
